资料来自leetcode官网
**
第六题,有效的括号
**
给定一个只包括 ‘(’,’)’,’{’,’}’,’[’,’]’ 的字符串,判断字符串是否有效。
有效字符串需满足:
1.左括号必须用相同类型的右括号闭合。
2.左括号必须以正确的顺序闭合。
输入: " ( [ ) ] "
输出: false
输入: " { [ ] } "
输出: true
注意空字符串可被认为是有效字符串。
方法一:栈
判断括号的有效性可以使用「栈」这一数据结构来解决。
我们对给定的字符串 s进行遍历,当我们遇到一个左括号时,我们会期望在后续的遍历中,有一个相同类型的右括号将其闭合。由于后遇到的左括号要先闭合,因此我们可以将这个左括号放入栈顶。
{ ( ) }
当我们遇到一个右括号时,我们需要将一个相同类型的左括号闭合。此时,我们可以取出栈顶的左括号并判断它们是否是相同类型的括号。如果不是相同的类型,或者栈中并没有左括号,那么字符串 s 无效,返回 False。为了快速判断括号的类型,我们可以使用哈希映射(HashMap)存储每一种括号。哈希映射的键为右括号,值为相同类型的左括号。
在遍历结束后,如果栈中没有左括号,说明我们将字符串 s 中的所有左括号闭合,返回 True,否则返回 False。
注意到有效字符串的长度一定为偶数,因此如果字符串的长度为奇数,我们可以直接返回 False,省去后续的遍历判断过程。
class Solution {
public:
bool isValid(string s)
{
int n=s.size();
if(n%2==1)
{
return false;
}
unordered_map<char,char> pairs=
{
{')','('},{']','['},{'}','{'}//右括号是键,元素,左括号是值,索引
};
stack<char> stk;
for(char c:s)//遍历s里的每一个char,所以都说了c++里string就像数组一样
{
if(pairs.count(c))//是不是有这个右括号?
{
if(stk.empty()||stk.top()!=pairs[c])
{//如果不是相同的类型,或者栈中并没有左括号,那么字符串 s 无效,返回 False
return false;
}
stk.pop();//出栈
}
else//注意条件,这里是只要是左括号就入栈
{
stk.push(c);//入栈
}
}
return stk.empty();//如果全部匹配了,则栈应该是空
};
};直接想一个满足条件的情况带代入,比如{()},并且是从左往右一个一个判断的
for char(char c:s)和for char(char& c:s)用于遍历数组,
使用
for (char c : s)
时会复制一个s字符串再进行遍历操作,而使用
for (char& c : s)
时直接引用原字符串进行遍历操作,由于复制一个字符串花费了大量的时间,所以第二种解法要快于第一种解法。
方法二,还是用栈
class Solution {
public:
bool isValid(string s) {
stack<char> paren;
for (char c : s) {
switch (c) {
case '(':
case '{':
case '[': paren.push(c); break;//case可以攒起来的。。
case ')': if (paren.empty() || paren.top()!='(') return false; else paren.pop(); break;
case '}': if (paren.empty() || paren.top()!='{') return false; else paren.pop(); break;
case ']': if (paren.empty() || paren.top()!='[') return false; else paren.pop(); break;
default: ; // 注意这里
}
}
return paren.empty() ;
}
};奇妙的一个解法,用的java
class Solution {
public boolean isValid(String s) {
while(s.contains("()")||s.contains("[]")||s.contains("{}")){
if(s.contains("()")){
s=s.replace("()","");
}
if(s.contains("{}")){
s=s.replace("{}","");
}
if(s.contains("[]")){
s=s.replace("[]","");
}
}
return s.length()==0;
}
}**
第七题:合并两个有序链表
**
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
方法一:递归
思路
我们可以如下递归地定义两个链表里的 merge 操作(忽略边界情况,比如空链表等):
list1[0] + merge(list1[1:], list2) list1[0] < list2[0] //
list2[0] + merge(list1, list2[1:]) otherwise
也就是说,两个链表头部值较小的一个节点与剩下元素的 merge 操作结果合并。
算法
我们直接将以上递归过程建模,同时需要考虑边界情况。
如果 l1 或者 l2 一开始就是空链表 ,那么没有任何操作需要合并,所以我们只需要返回非空链表。否则,我们要判断 l1 和 l2 哪一个链表的头节点的值更小,然后递归地决定下一个添加到结果里的节点。如果两个链表有一个为空,递归结束。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1,ListNode* l2)
{
if(l1==nullptr)
{
return l2;
}
else if(l2==nullptr)
{
return l1;
}
else if(l1->val<l2->val)
{
l1->next=mergeTwoLists(l1->next,l2);
return l1;
}
else
{
l2->next=mergeTwoLists(l1,l2->next);
return l2;
}
}
};nullptr 空指针 , val就是value,
另外,碰到这种递归的,或者难想的,可以动手画图,就像套娃一样,一层层拆,一层层装;
再另外,递归,就是大问题化小问题,那么就想想最小的情况是什么样,这里就比如两个链表都只有一个值,
具体关于链表去看书,值和指针,结点什么的
递归总是这样,想的时候很绕,一旦想通简直酸爽
目标:合并两个链表,而链表要注意是一个结点一个结点接起来的,,所以合并链表具体点说的操作就是一个结点一个结点判断过去
谁小就把谁接上,直到某个表为空,当然有个本来就有序的前提,
这个思维可能我们还需要更多的做题来培养,
方法二:迭代
思路
我们可以用迭代的方法来实现上述算法。当 l1 和 l2 都不是空链表时,判断 l1 和 l2 哪一个链表的头节点的值更小,将较小值的节点添加到结果里,当一个节点被添加到结果里之后,将对应链表中的节点向后移一位。
算法
首先,我们设定一个哨兵节点 prehead ,这可以在最后让我们比较容易地返回合并后的链表。我们维护一个 prev 指针,我们需要做的是调整它的 next 指针。然后,我们重复以下过程,直到 l1 或者 l2 指向了 null :如果 l1 当前节点的值小于等于 l2 ,我们就把 l1 当前的节点接在 prev 节点的后面同时将 l1 指针往后移一位。否则,我们对 l2 做同样的操作。不管我们将哪一个元素接在了后面,我们都需要把 prev 向后移一位。
在循环终止的时候, l1 和 l2 至多有一个是非空的。由于输入的两个链表都是有序的,所以不管哪个链表是非空的,它包含的所有元素都比前面已经合并链表中的所有元素都要大。这意味着我们只需要简单地将非空链表接在合并链表的后面,并返回合并链表即可。
下图展示了 1->4->5 和 1->2->3->6 两个链表迭代合并的过程:
tmd图是个ppt
跳转
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1,ListNode* l2)
{
ListNode* preHead=new ListNode(-1);
ListNode* prev=preHead;
while(l1!=nullptr&&l2!=nullptr)
{
if(l1->val<l2->val)
{
prev->next=l1;
l1=l1->next;
}
else
{
prev->next=l2;
l2=l2->next;
}
prev=prev->next;
}
prev->next=l1==nullptr?l2:l1;
return preHead->next;
}
};只选用我们需要的
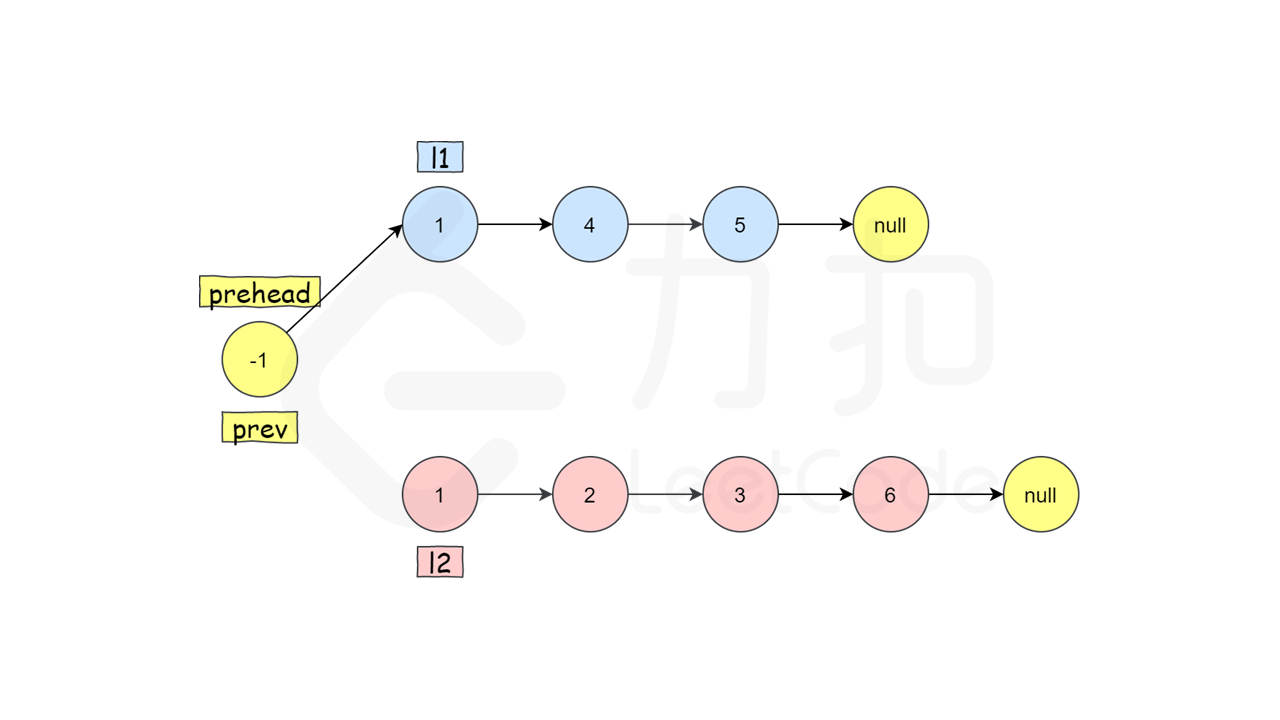
关于为什么要赋值一个prev(哨兵节点)
讲解:首先,比较容易理解的是如果不复制,直接用本体迭代,指向的是尾节点没问题
那么,我们复制一个,然后一步一步看,第一,现在prev和prehead的指针是同一个指针,所以当我们将prev的指针指向l1头时,prehead指针也改变(大概?),
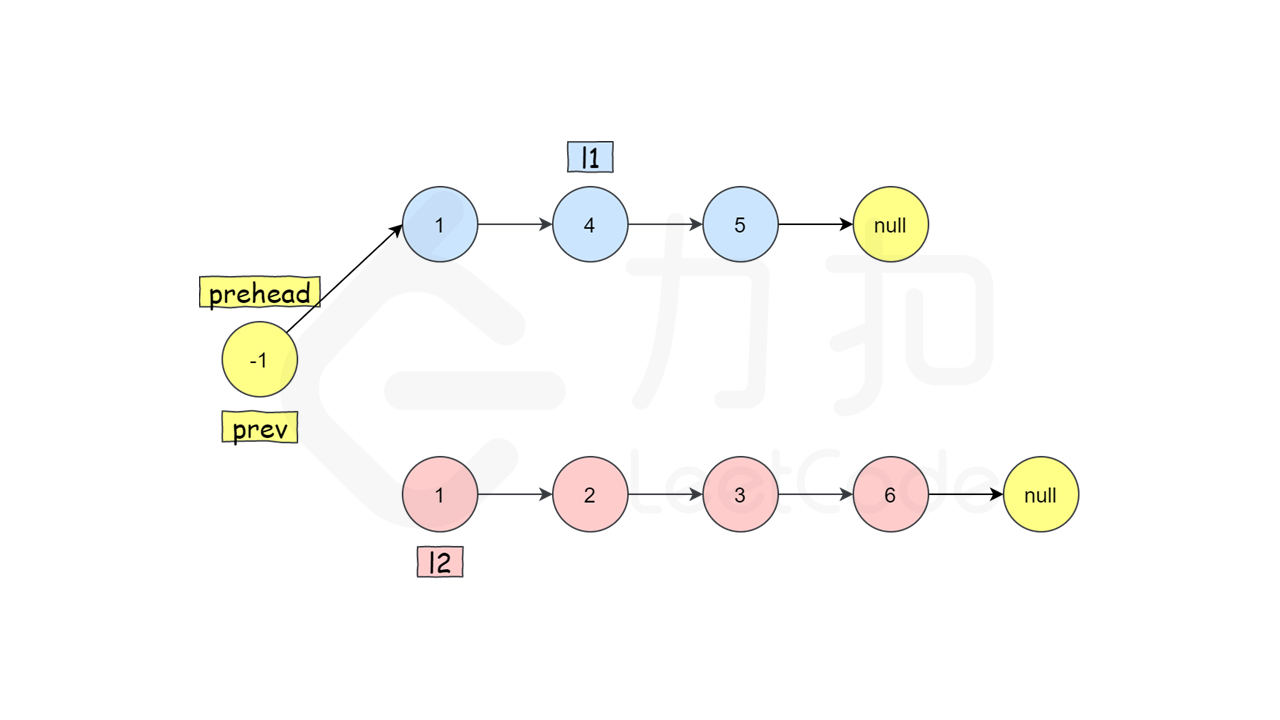
第二步:注意这里先将l1的节点向后移,且是头节点向后移,这里就相当于本体,像l1head,一定注意注意,链表只能通过指针一个一个查找,
给你一个链表,就相当于后面的都看不到,只有一个头节点,就是说,对于链表来说,我们每一时刻其实只能操作一个节点,就像我们操作一个节点prev一样,
移动l1的头节点之后,原本的头结点也没丢掉,链在了l1的这条链上,这条链是一个一个链上的,
但是原本头节点的指针此时就可以被我们操作,链往新的链,
而如果移动l1头节点之前就改变这个指针,则我们就无法找到l1的后续节点了
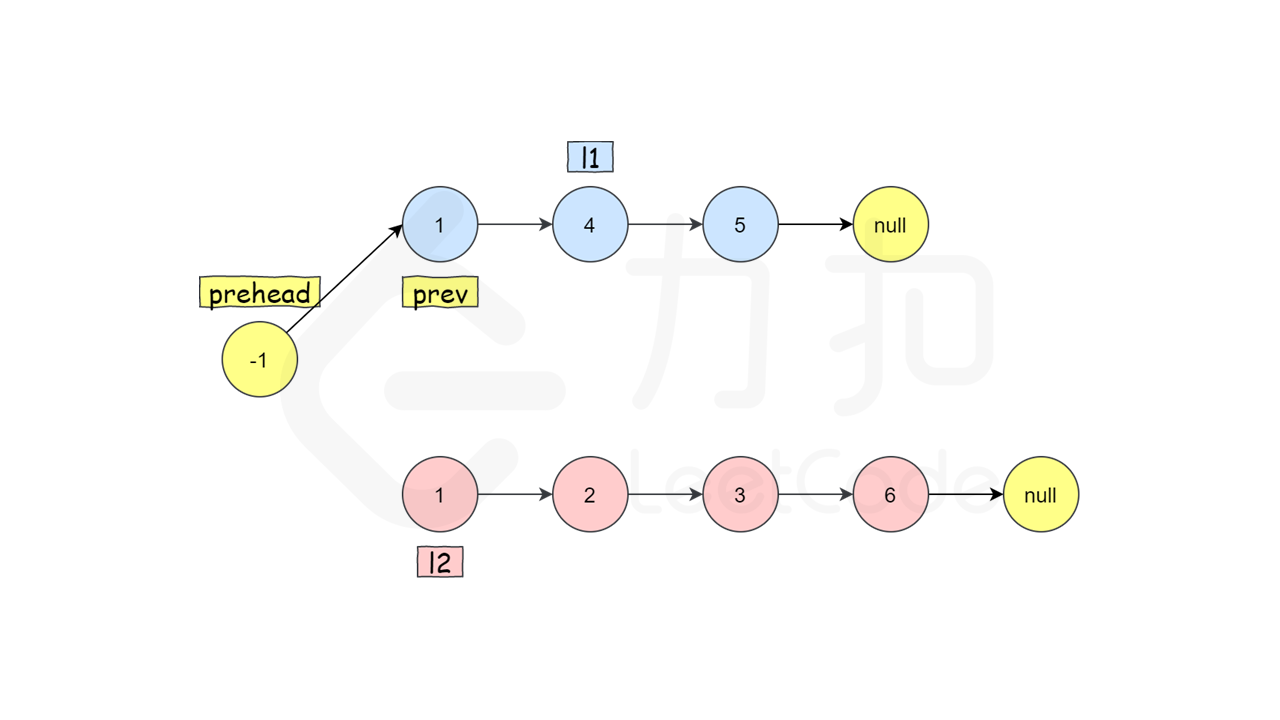
第三步,因为有prev=prev->next这一句存在,prev节点从prehead的复制变成了l1的头节点,这是prev整个节点的改变,上一步相当于通过指针找到了prev的下一个节点,这一步就移动过来(链表只能通过链域也就是节点来查找),
同时注意,prev此时相当于l1的复制了,指针也是l1指针的复制,不再是prehead指针的复制,
指针已经跟着prev的改变而改变了,
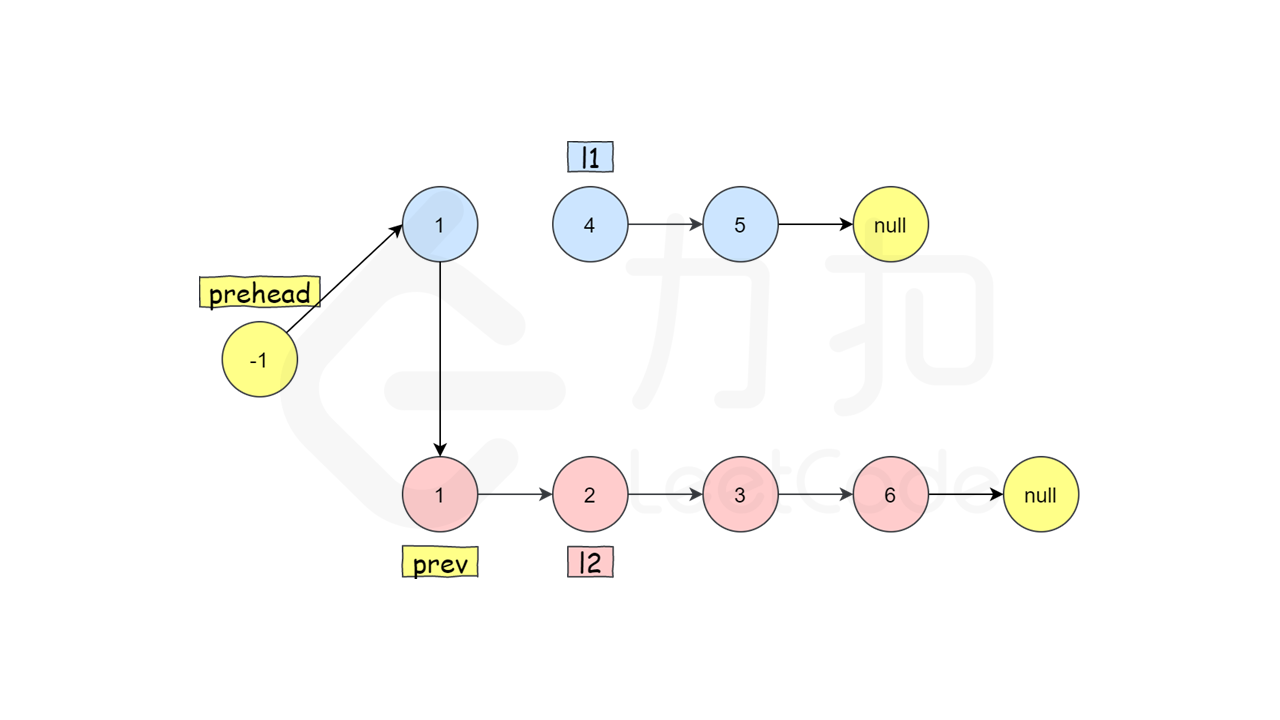
第四步,通过同样的操作,先改变l2的指针,将l2的头节点移动到下一个,然后将prev移动到l2的原头节点,
这样一来,就将每一个我们需要的节点链接了起来,
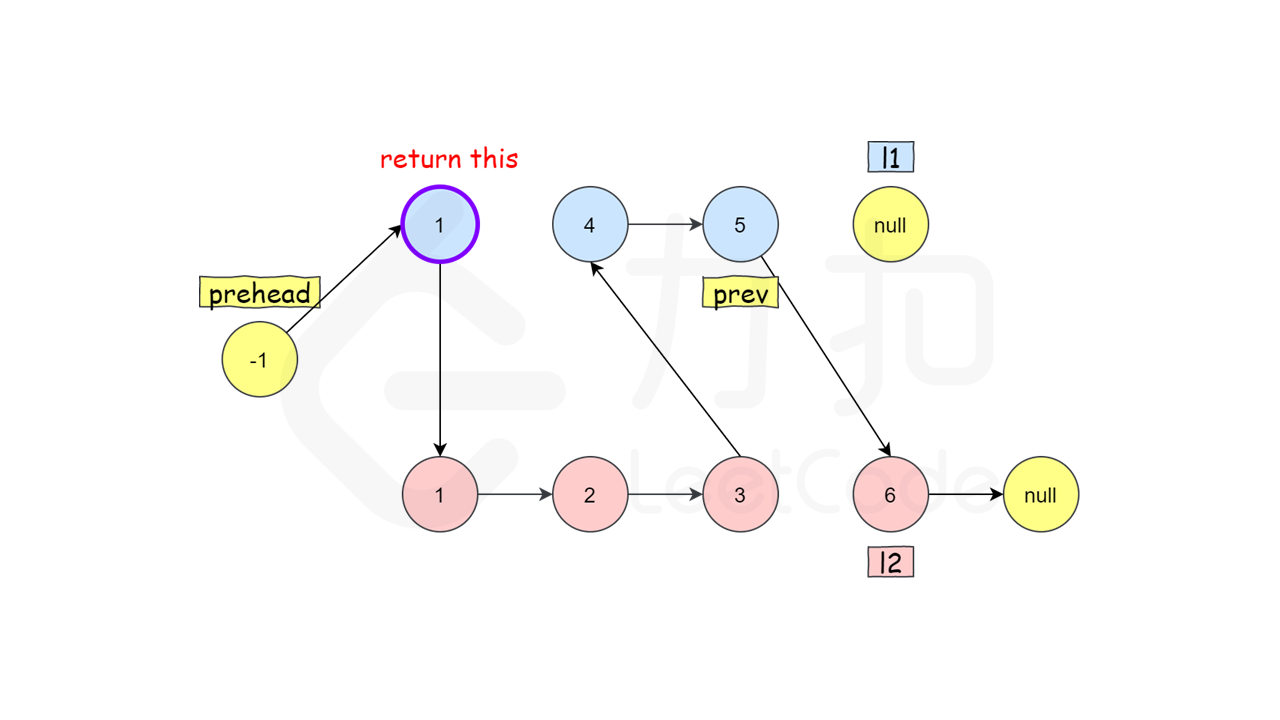
最后比如这样,l1为空了,我们就只需要将l1的尾节点链向l2的剩余节点,(此时的l2头结点)
然后返回prehead->next,即所求链表的头节点(怪不得叫prehead)
多逛一逛评论区经常能学到东西
比如:
ListNode prehead = new ListNode(-1);
ListNode prev = prehead;
求大佬帮忙解释下,为什么要把prehead赋值给prev呢,不能直接用prehead吗?
如果不赋值给prev,用prehead代替prev去做迭代的话,那prehead最终指向的是l1或l2的尾节点,相当于没保存合并后链表的头结点。而赋值之后,让prev不断指向合并后最新节点把链表链接起来,prehead.next还是合并后的头结点
就是用两个指针指向同一个哑节点,一个用来负责指向l1,l2 比较的结果,来合并成一个链表。一个负责返回合并的这个链表,因为一开始两个指针指向的是同一个亚节点,最后返回时要.next。 所以如果只用一个节点的话,它会跟着l1,或者l2移动到尾部,最后指向l1,或l2中尾部最大的那个节点,这是返回的话,返回的只是一个节点。所以一开始我们让两个指针指向同一个亚节点。
能用递归就必然能用迭代
第八题:删除排序数组中的重复项
给定一个排序数组,你需要在 原地 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
方法,双指针法(快慢指针法)
class Solution {
public:
int removeDuplicates(vector<int>& nums)
{
if(nums.empty())
return 0;
int slowIndex=0;
for(int fastIndex=0;fastIndex<(nums.size()-1);fastIndex++)
{
if(nums[fastIndex]!=nums[fastIndex+1])
{
nums[++slowIndex]=nums[fastIndex+1];
}
}
return slowIndex+1;
}
};fastIndex在相等时递增,slowIndex在不等时递增,并且得到数组的值
第九题:移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
这跟上一题差不多。。
解法一:暴力解法
数组的元素在内存地址中是连续的,数组中的元素不能删除,只能覆盖
两层for循环,一层遍历,一层更新(移动)
class Solution {
public:
int removeElement(vector<int>& nums,int val)
{
int size=nums.size();
for(int i=0;i<size;i++)//遍历数组
{
if(nums[i]==val)
{
for(int j=i+1;j<size;j++)//更新数组
{
nums[j-1]=nums[j];
}
i--;//i要向前移动!
size--;
}
}
return size;
}
};时间复杂度 O(n^2)
上面那题也可以这样做吧,不过主要应该还是要用双指针,
解法二:双指针法
双指针法(快慢指针法): 通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。
双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组和链表操作的面试题,都使用双指针法。
class Solution {
public:
int removeElement(vector<int>& nums,int val)
{
int slowIndex=0;
for(int fastIndex=0;fastIndex<nums.size();fastIndex++)
{
if(nums[fastIndex]!=val)
{
nums[slowIndex++]=nums[fastIndex];
}
}
return slowIndex;
}
};// 时间复杂度:O(n)
// 空间复杂度:O(1)
**
第十题:实现strStr()
**
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
输入: haystack = “hello”, needle = “ll”
输出: 2
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。
还用什么kmp,感觉超出目前能力,先跳过,根本不是简单题吧喂
最后
以上就是平淡哑铃最近收集整理的关于LeetCode算法题个人笔记【简单6-10】【c++】第十题:实现strStr()的全部内容,更多相关LeetCode算法题个人笔记【简单6-10】【c++】第十题内容请搜索靠谱客的其他文章。








发表评论 取消回复