多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
所以为了解决这个问题,会有一些加锁等操作。这里博主提供一种不加锁的解决方案(记得点赞加关注哦,码字不易):
import threading
n = 0 # 标记,看能否归零,不能证明被乱改了
def thread1():
for t in range(10000):
print(f"this is thread{t}")
global n
n = n + 1
n -= 1
l = [] # 子线程池
for i in range(10): # 循环创建子线程,我试了最大试了100W,就卡死了,不知道是系统限制,还是博主电脑带不动。
t = threading.Thread(target=thread1) # 实例子线程
l.append(t) # 将子线程添加到线程池统一管理
t.start()
for k in l:
k.join() # 子线程开启线程守护
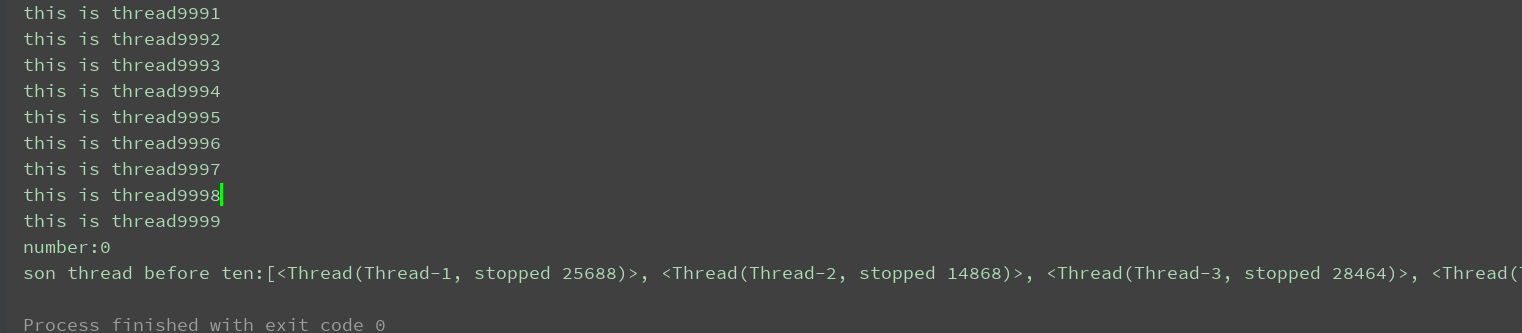
print(f"number:{n}") # 结果
print('son thread before ten:%s' % l[0:10]) # 打印前十线程对象
结果:
拓展:
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
用户界面可以更加吸引人,比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
程序的运行速度可能加快。 - 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标
GIL 全局解释器
在非python环境中,单核情况下,同时只能有一个任务执行。多核时可以支持多个线程同时执行。但是在python中,无论有多少个核
同时只能执行一个线程。究其原因,这就是由于GIL的存在导致的。
GIL的全程是全局解释器,来源是python设计之初的考虑,为了数据安全所做的决定。某个线程想要执行,必须先拿到GIL,我们可以
把GIL看做是“通行证”,并且在一个python进程之中,GIL只有一个。拿不到线程的通行证,并且在一个python进程中,GIL只有一个,
拿不到通行证的线程,就不允许进入CPU执行。GIL只在cpython(解释器)中才有,因为cpython调用的是c语言的原生线程,所以他不能直接操
作cpu,而只能利用GIL保证同一时间只能有一个线程拿到数据。而在pypy和jpython中是没有GIL的
python在使用多线程的时候,调用的是c语言的原生过程。
所以解决GIL问题,方法之一可以替换不同的python解释器。
‘’’
‘’’
python针对不同类型的代码执行效率也是不同的
1、CPU密集型代码(各种循环处理、计算等),在这种情况下,由于计算工作多,ticks技术很快就会达到阀值,然后出发GIL的
释放与再竞争(多个线程来回切换当然是需要消耗资源的),所以python下的多线程对CPU密集型代码并不友好。
2、IO密集型代码(文件处理、网络爬虫等设计文件读写操作),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,
造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序的执行
效率)。所以python的多线程对IO密集型代码比较友好。
‘’’
‘’’
主要要看任务的类型,我们把任务分为I/O密集型和计算密集型,而多线程在切换中又分为I/O切换和时间切换。如果任务属于是I/O密集型,
若不采用多线程,我们在进行I/O操作时,势必要等待前面一个I/O任务完成后面的I/O任务才能进行,在这个等待的过程中,CPU处于等待
状态,这时如果采用多线程的话,刚好可以切换到进行另一个I/O任务。这样就刚好可以充分利用CPU避免CPU处于闲置状态,提高效率。但是
如果多线程任务都是计算型,CPU会一直在进行工作,直到一定的时间后采取多线程时间切换的方式进行切换线程,此时CPU一直处于工作状态,
此种情况下并不能提高性能,相反在切换多线程任务时,可能还会造成时间和资源的浪费,导致效能下降。这就是造成上面两种多线程结果不能的解释。
结论:I/O密集型任务,建议采取多线程,还可以采用多进程+协程的方式(例如:爬虫多采用多线程处理爬取的数据);对于计算密集型任务,python此时就不适用了。
‘’’
————————————————
版权声明:本文为CSDN博主「笨小孩哈哈」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_40481076/article/details/101594705
一万小时定律
人们眼中的天才之所以卓越非凡,并非天资超人一等,而是付出了持续不断的努力。
一万小时的锤炼是任何人从平凡变成超凡的必要条件。
最后
以上就是含糊果汁最近收集整理的关于python3--批量创建多线程(threading)不加锁实现线程安全方法之一的全部内容,更多相关python3--批量创建多线程(threading)不加锁实现线程安全方法之一内容请搜索靠谱客的其他文章。








发表评论 取消回复