文章目录
- 一、背压
- 1.1、背压机制产生的背景
- 二、SparkStreaming的背压机制
- 2.1、spark1.5之前
- 2.1.1、receiver模式
- 2.1.2、direct模式
- 2.1.3、缺点
- 2.2、spark1.5之后
- 2.2.1、一些相关的参数
- 三、Flink背压机制
- 3.1、背压实现
- 3.1.1、采样线程
- 3.1.2、Sample
- 3.1.3、配置
- 3.2、如何定位背压
- 3.2.1、在web页面发现fink的checkpoint生成超时, 失败。
- 3.2.2、查看jobmanager日志
- 3.2.3、 BackPressure界面
- 3.2.4、Metrics 监控背压
- 3.3、背压影响
- 3.4、如何解决背压现象?
- 四、对比总结
一、背压
1.1、背压机制产生的背景
背压(back pressure)机制主要用于解决流处理系统中,业务流量在短时间内剧增,造成巨大的流量毛刺,数据流入速度远高于数据处理速度,对流处理系统构成巨大的负载压力的问题。
如果不能处理流量毛刺或者持续的数据过高速率输入,可能导致Executor端出现OOM的情况或者任务崩溃。
二、SparkStreaming的背压机制
2.1、spark1.5之前
就是 通过限制最大消费速度(这个要人为压测预估)
2.1.1、receiver模式
可以配置spark.streaming.receiver.maxRate参数来限制每个receiver没每秒最大可以接收的数据量
2.1.2、direct模式
可以配置 spark.streaming.kafka.maxRatePerPartition 参数来限制每个kafka分区最多读取的数据量。
2.1.3、缺点
- 实现需要进行压测,来设置最大值。参数的设置必须合理,如果集群处理能力高于配置的速率,则会造成资源的浪费。
- 参数需要手动设置,设置过后必须重启streaming服务。
2.2、spark1.5之后
新版的背压机制不需要手动干预,spark streaming 能够根据当前数据量以及集群状态来预估下个批次最优速率。
2.2.1、一些相关的参数
- 开启背压机制:设置spark.streaming.backpressure.enabled 为true,默认为false
- 启用反压机制时每个接收器接收第一批数据的初始最大速率。默认值没有设置 spark.streaming.backpressure.initialRate
- 速率估算器类,默认值为 pid ,目前 Spark 只支持这个,大家可以根据自己的需要实现 spark.streaming.backpressure.rateEstimator
- 用于响应错误的权重(最后批次和当前批次之间的更改)。默认值为1,只能设置成非负值。weight for response to “error” (change between last batch and this batch) spark.streaming.backpressure.pid.proportional
- 错误积累的响应权重,具有抑制作用(有效阻尼)。默认值为 0.2 ,只能设置成非负值。weight for the response to the accumulation of error. This has a dampening effect. spark.streaming.backpressure.pid.integral
- 对错误趋势的响应权重。 这可能会引起 batch size 的波动,可以帮助快速增加/减少容量。默认值为0,只能设置成非负值。weight for the response to the trend in error. This can cause arbitrary/noise-induced fluctuations in batch size, but can also help react quickly to increased/reduced capacity. spark.streaming.backpressure.pid.derived
- 可以估算的最低费率是多少。默认值为 100,只能设置成非负值。 spark.streaming.backpressure.pid.minRate
三、Flink背压机制
flink 的背压特性是逐渐反向背压,从下游的算子开始逐渐排查是哪个算子处理数据处理不过来了。 然后上游减缓发送速度。当fink自动逐级背压处理不过来的时候就需要人为手动来干预了。
3.1、背压实现
3.1.1、采样线程
背压监测通过反复获取正在运行的任务的堆栈跟踪的样本来工作,JobManager 对作业重复调用 Thread.getStackTrace()。
下面是官方提供的示意图:
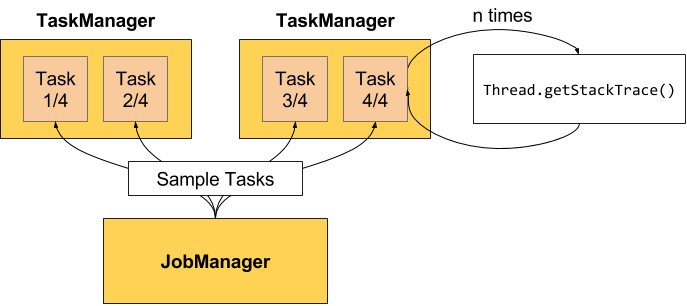
3.1.2、Sample
如果采样(samples)显示任务线程卡在某个内部方法调用中,则表示该任务存在背压。
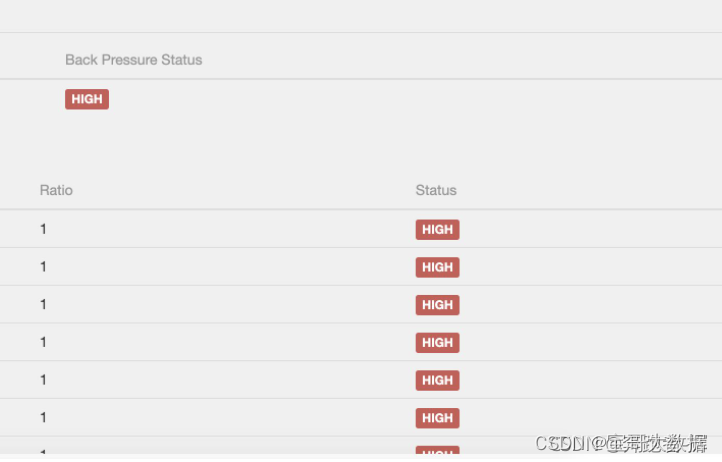
默认情况下,JobManager 每50ms为每个任务触发100个堆栈跟踪,来确定背压。在Web界面中看到的比率表示在内部方法调用中有多少堆栈跟踪被阻塞,例如,0.01表示该方法中只有1个被卡住。状态和比率的对照如下:
- OK:0 <= Ratio <= 0.10
- LOW:0.10 <Ratio <= 0.5
- HIGH:0.5 <Ratio <= 1
为了不使堆栈跟踪样本对 TaskManager 负载过高,每60秒会刷新采样数据。
3.1.3、配置
可以使用以下配置 JobManager 的采样数:
- web.backpressure.refresh-interval,统计数据被废弃重新刷新的时间(默认值:60000,1分钟)。
- web.backpressure.num-samples,用于确定背压的堆栈跟踪样本数(默认值:100)。
- web.backpressure.delay-between-samples,堆栈跟踪样本之间的延迟以确定背压(默认值:50,50ms)。
3.2、如何定位背压
3.2.1、在web页面发现fink的checkpoint生成超时, 失败。
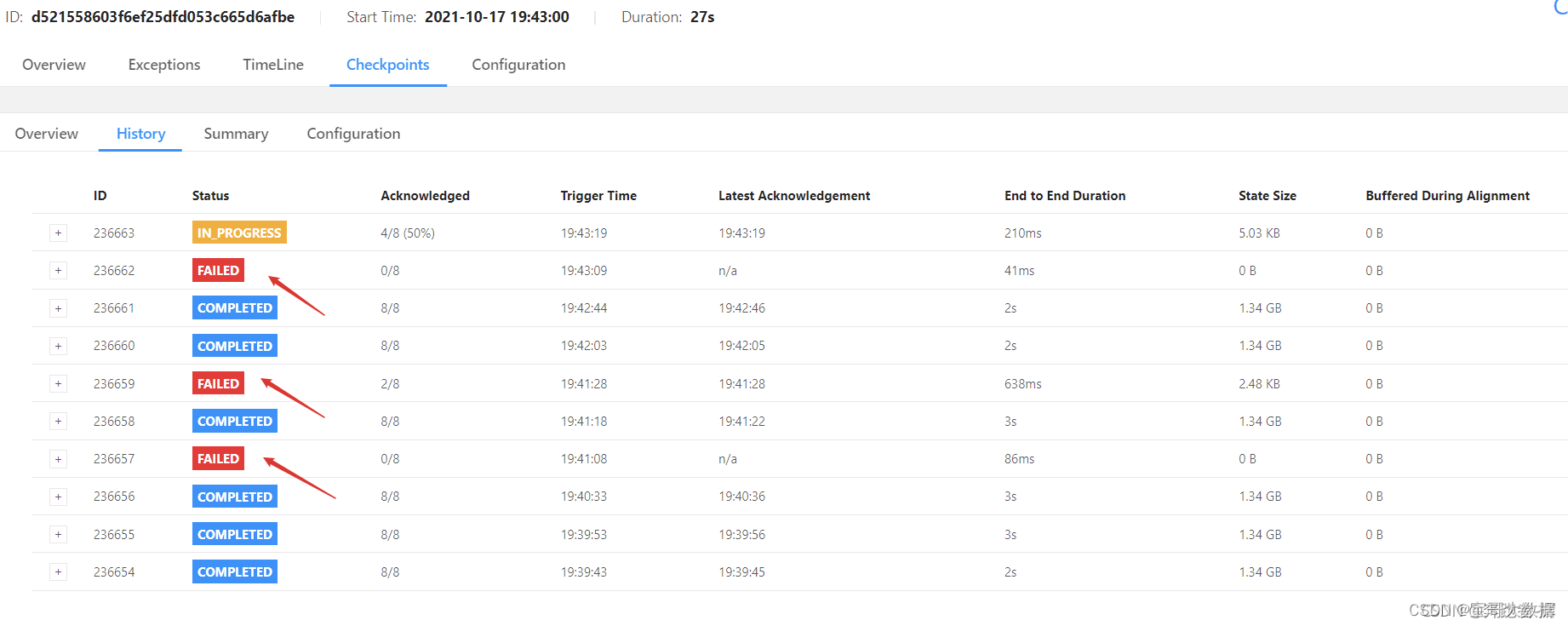
3.2.2、查看jobmanager日志

3.2.3、 BackPressure界面
背压状态可以大致锁定背压可能存在的算子,但具体背压是由于当前Task自身处理速度慢还是由于下游Task处理慢导致的,需要通过metric监控进一步判断。
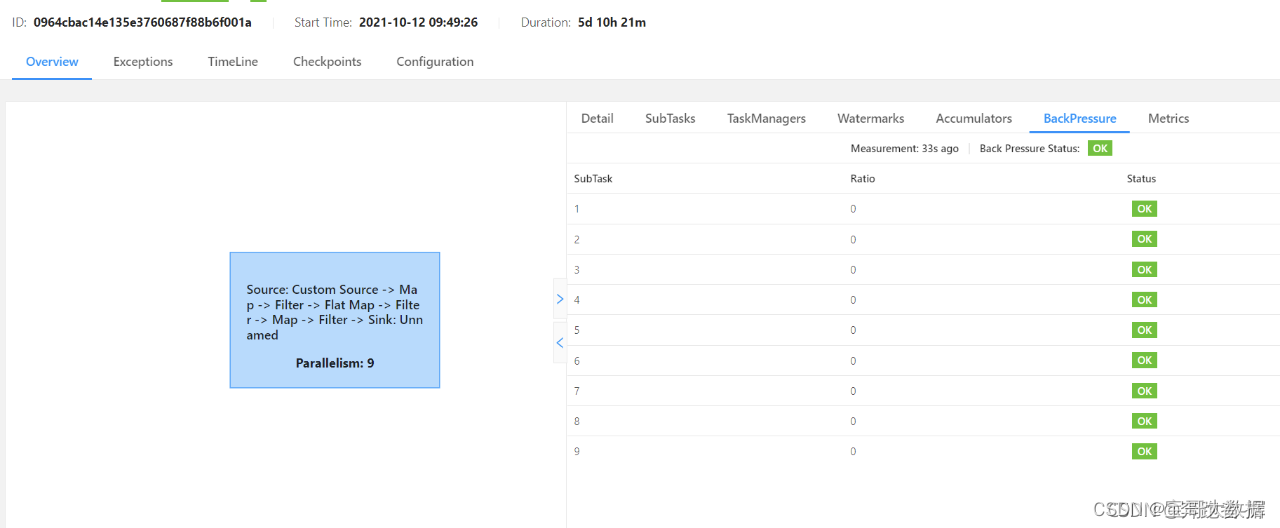
**原理:**BackPressure界面会周期性的对Task线程栈信息采样,通过线程被阻塞在请求Buffer的频率来判断节点是否处于背压状态。计算缓冲区阻塞线程数与总线程数的比值 rate。其中,rate < 0.1 为 OK,0.1 <= rate <= 0.5 为 LOW,rate > 0.5 为 HIGH。
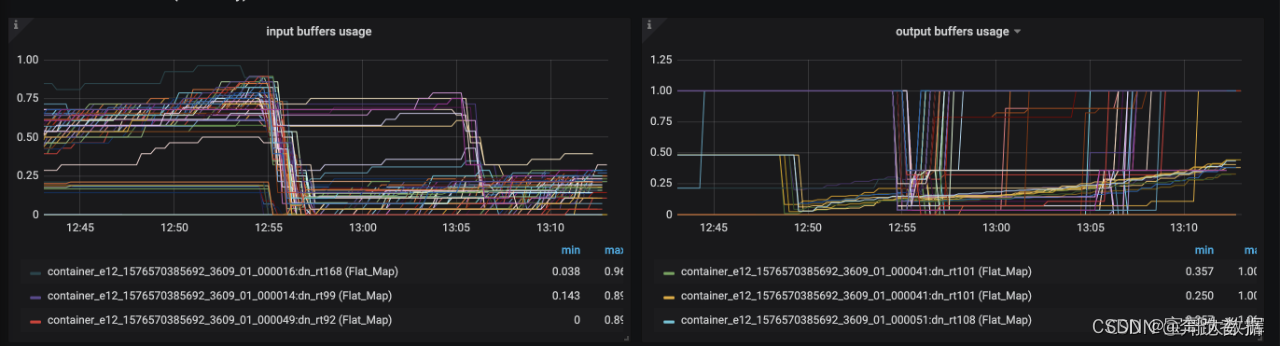
3.2.4、Metrics 监控背压
缓冲区的数据处理不过来,barrier流动慢,导致checkpoint生成时间长, 出现超时的现象。input 和 output缓冲区都占满。
3.3、背压影响
首先,背压不会直接导致系统的崩盘,只是处在一个不健康的运行状态。
(1)背压会导致流处理作业数据延迟的增加。
(2)影响到Checkpoint,导致失败,导致状态数据保存不了,如果上游是kafka数据源,在一致性的要求下,可能会导致offset的提交不上。
原理: 由于Flink的Checkpoint机制需要进行Barrier对齐,如果此时某个Task出现了背压,Barrier流动的速度就会变慢,导致Checkpoint整体时间变长,如果背压很严重,还有可能导致Checkpoint超时失败。
(3)影响state的大小,还是因为checkpoint barrier对齐要求。导致state变大。
原理: 接受到较快的输入管道的barrier后,它后面数据会被缓存起来但不处理,直到较慢的输入管道的barrier也到达。这些被缓存的数据会被放到state 里面,导致state变大。
3.4、如何解决背压现象?
Flink不需要一个特殊的机制来处理背压,因为Flink中的数据传输相当于已经提供了应对背压的机制。所以只有从代码上与资源上去做一些调整。
(1)背压部分原因可能是由于数据倾斜造成的,我们可以通过 Web UI 各个 SubTask 的 指标值来确认。Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。解决方式把数据分组的 key 预聚合来消除数据倾斜。
(2)代码的执行效率问题,阻塞或者性能问题。
(3)TaskManager 的内存大小导致背压。
四、对比总结
参考:
https://blog.csdn.net/may_fly/article/details/103922862
https://www.zhihu.com/question/345381979
最后
以上就是震动雪碧最近收集整理的关于面试题:Flink反压机制及与Spark Streaming的区别一、背压二、SparkStreaming的背压机制三、Flink背压机制四、对比总结的全部内容,更多相关面试题:Flink反压机制及与Spark内容请搜索靠谱客的其他文章。








发表评论 取消回复