抢占式调度
情况1:最常见的现象就是一个进程执行时间太长了,是时候切换到另一个进程
那怎么衡量一个进程的运行时间呢?
在计算机里面有一个时钟,会过一段时间触发一次时钟中断,通知操作系统,时间又过去一个时钟周期
时钟中断处理函数会调用 scheduler_tick
scheduler_tick 函数
kernelschedcore.c
/*
* This function gets called by the timer code, with HZ frequency.
* We call it with interrupts disabled.
*/
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
struct rq_flags rf;
sched_clock_tick();
rq_lock(rq, &rf);
update_rq_clock(rq);
curr->sched_class->task_tick(rq, curr, 0);
cpu_load_update_active(rq);
calc_global_load_tick(rq);
rq_unlock(rq, &rf);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);
#endif
rq_last_tick_reset(rq);
}

- 先取出当前 CPU 的运行队列
struct rq *rq = cpu_rq(cpu); - 然后得到这个队列上当前正在运行中的进程的 task_struct
struct task_struct *curr = rq->curr; - 然后调用这个 task_struct 的调度类的 task_tick 函数来处理时钟事件
curr->sched_class->task_tick(rq, curr, 0);
如果当前运行的进程是普通进程,调度类为 fair_sched_class,调用的处理时钟的函数为 task_tick_fair。
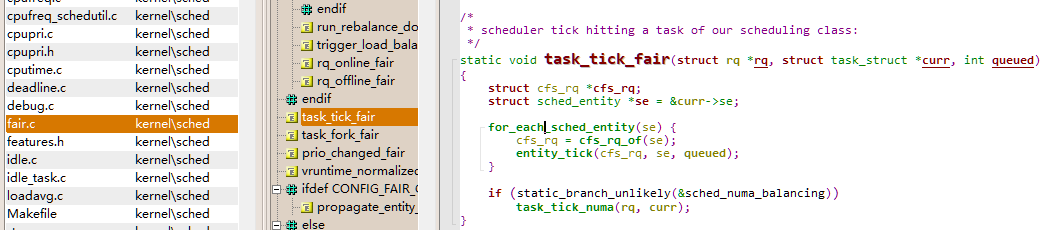
task_tick_fair 函数
kernelschedfair.c
/*
* scheduler tick hitting a task of our scheduling class:
*/
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);
}
if (static_branch_unlikely(&sched_numa_balancing))
task_tick_numa(rq, curr);
}
-
根据当前进程的 task_struct,找到对应的调度实体 sched_entity 和 cfs_rq 队列
cfs_rq = cfs_rq_of(se); -
调用 entity_tick 函数
entity_tick 函数
kernelschedfair.c
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
update_curr(cfs_rq);
update_load_avg(curr, UPDATE_TG);
update_cfs_shares(curr);
.....
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr);
}

在 entity_tick 里面,调用 update_curr 它会更新当前进程的 vruntime,
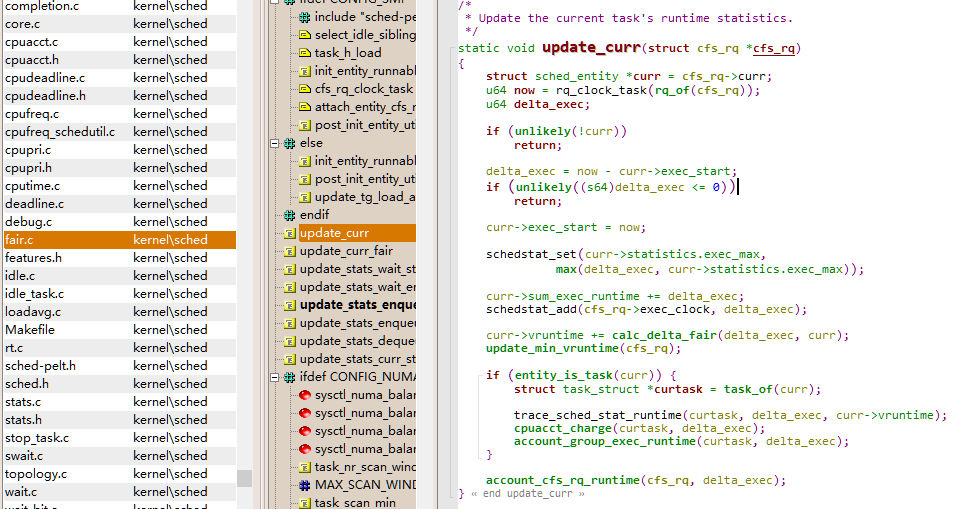
update_curr 函数
kernelschedfair.c
/*
* Update the current task's runtime statistics.
*/
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq->exec_clock, delta_exec);
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cpuacct_charge(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
然后调用 check_preempt_tick函数,检查是否是时候被抢占了 check_preempt_tick(cfs_rq, curr);
check_preempt_tick 函数
kernelschedfair.c
/*
* Preempt the current task with a newly woken task if needed:
*/
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
ideal_runtime = sched_slice(cfs_rq, curr);
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
/*
* The current task ran long enough, ensure it doesn't get
* re-elected due to buddy favours.
*/
clear_buddies(cfs_rq, curr);
return;
}
/*
* Ensure that a task that missed wakeup preemption by a
* narrow margin doesn't have to wait for a full slice.
* This also mitigates buddy induced latencies under load.
*/
if (delta_exec < sysctl_sched_min_granularity)
return;
se = __pick_first_entity(cfs_rq);
delta = curr->vruntime - se->vruntime;
if (delta < 0)
return;
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}

- 先是调用 sched_slice 函数计算出的 ideal_runtime
- ideal_runtime = sched_slice(cfs_rq, curr);
- ideal_runtime 是一个调度周期中,该进程应该运行的实际时间
- 再计算进程本次调度运行时间 delta_exec
- delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
- sum_exec_runtime 指进程总共执行的实际时间,prev_sum_exec_runtime 指上次该进程被调度时已经占用的实际时间。
- 每次在调度一个新的进程时都会把它的 se->prev_sum_exec_runtime = se->sum_exec_runtime
- 所以 sum_exec_runtime-prev_sum_exec_runtime 就是这次调度占用实际时间
如果delta_exec这个时间大于 ideal_runtime,则应该被抢占了。
如果delta_exec这个时间不大于 ideal_runtime,则还需校验红黑树中最小的进程的vruntime
__pick_first_entity 取出红黑树中最小的进程, se = __pick_first_entity(cfs_rq);
当前进程的 vruntime 大于红黑树中最小的进程的 vruntime,且差值大于 ideal_runtime,也应该被抢占了。
kernelschedfair.c 函数 check_preempt_tick 中
delta = curr->vruntime - se->vruntime;
if (delta < 0)
return;
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));

如果发现当前进程应该被抢占
不能直接把它踢下来,而是把它标记为应该被抢占,等待正在运行的进程调用 __schedule切换为其他进程
标记一个进程应该被抢占,是通过调用 resched_curr( 函数check_preempt_tick中调用),它会调用 set_tsk_need_resched,标记进程应该被抢占,但是此时此刻,并不真的抢占,而是打上一个标签 TIF_NEED_RESCHED。
resched_curr 函数
kernelschedcore.c
/*
* resched_curr - mark rq's current task 'to be rescheduled now'.
*
* On UP this means the setting of the need_resched flag, on SMP it
* might also involve a cross-CPU call to trigger the scheduler on
* the target CPU.
*/
void resched_curr(struct rq *rq)
{
struct task_struct *curr = rq->curr;
int cpu;
lockdep_assert_held(&rq->lock);
if (test_tsk_need_resched(curr))
return;
cpu = cpu_of(rq);
if (cpu == smp_processor_id()) {
set_tsk_need_resched(curr);
set_preempt_need_resched();
return;
}
if (set_nr_and_not_polling(curr))
smp_send_reschedule(cpu);
else
trace_sched_wake_idle_without_ipi(cpu);
}

set_tsk_need_resched 函数
includelinuxsched.h
static inline void set_tsk_need_resched(struct task_struct *tsk)
{
set_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
}

情况2:另外一个可能抢占的场景是当一个进程被唤醒的时候
例子
当一个进程在等待一个 I/O 的时候,会主动放弃 CPU。但是当 I/O 到来的时候,进程往往会被唤醒。当被唤醒的进程优先级高于 CPU 上的当前进程,就会触发抢占。
try_to_wake_up() 调用 ttwu_queue 将这个唤醒的任务添加到队列当中。
try_to_wake_up 函数
kernelschedcore.c
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
unsigned long flags;
int cpu, success = 0;
smp_mb__before_spinlock();
raw_spin_lock_irqsave(&p->pi_lock, flags);
if (!(p->state & state))
goto out;
trace_sched_waking(p);
success = 1;
cpu = task_cpu(p);
smp_rmb();
if (p->on_rq && ttwu_remote(p, wake_flags))
goto stat;
#ifdef CONFIG_SMP
smp_rmb();
smp_cond_load_acquire(&p->on_cpu, !VAL);
p->sched_contributes_to_load = !!task_contributes_to_load(p);
p->state = TASK_WAKING;
if (p->in_iowait) {
delayacct_blkio_end();
atomic_dec(&task_rq(p)->nr_iowait);
}
cpu = select_task_rq(p, p->wake_cpu, SD_BALANCE_WAKE, wake_flags);
if (task_cpu(p) != cpu) {
wake_flags |= WF_MIGRATED;
set_task_cpu(p, cpu);
}
#else /* CONFIG_SMP */
if (p->in_iowait) {
delayacct_blkio_end();
atomic_dec(&task_rq(p)->nr_iowait);
}
#endif /* CONFIG_SMP */
ttwu_queue(p, cpu, wake_flags);
stat:
ttwu_stat(p, cpu, wake_flags);
out:
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
return success;
}

ttwu_queue 再调用 ttwu_do_activate 激活这个任务
ttwu_queue 函数
kernelschedcore.c
static void ttwu_queue(struct task_struct *p, int cpu, int wake_flags)
{
struct rq *rq = cpu_rq(cpu);
struct rq_flags rf;
#if defined(CONFIG_SMP)
if (sched_feat(TTWU_QUEUE) && !cpus_share_cache(smp_processor_id(), cpu)) {
sched_clock_cpu(cpu); /* Sync clocks across CPUs */
ttwu_queue_remote(p, cpu, wake_flags);
return;
}
#endif
rq_lock(rq, &rf);
update_rq_clock(rq);
ttwu_do_activate(rq, p, wake_flags, &rf);
rq_unlock(rq, &rf);
}

ttwu_do_activate 调用 ttwu_do_wakeup。
ttwu_do_activate 函数
kernelschedcore.c
static void
ttwu_do_activate(struct rq *rq, struct task_struct *p, int wake_flags,
struct rq_flags *rf)
{
int en_flags = ENQUEUE_WAKEUP | ENQUEUE_NOCLOCK;
lockdep_assert_held(&rq->lock);
#ifdef CONFIG_SMP
if (p->sched_contributes_to_load)
rq->nr_uninterruptible--;
if (wake_flags & WF_MIGRATED)
en_flags |= ENQUEUE_MIGRATED;
#endif
ttwu_activate(rq, p, en_flags);
ttwu_do_wakeup(rq, p, wake_flags, rf);
}

ttwu_do_wakeup 里面调用了 check_preempt_curr 检查是否应该发生抢占
ttwu_do_wakeup 函数
kernelschedcore.c
/*
* Mark the task runnable and perform wakeup-preemption.
*/
static void ttwu_do_wakeup(struct rq *rq, struct task_struct *p, int wake_flags,
struct rq_flags *rf)
{
check_preempt_curr(rq, p, wake_flags);
p->state = TASK_RUNNING;
trace_sched_wakeup(p);
#ifdef CONFIG_SMP
if (p->sched_class->task_woken) {
/*
* Our task @p is fully woken up and running; so its safe to
* drop the rq->lock, hereafter rq is only used for statistics.
*/
rq_unpin_lock(rq, rf);
p->sched_class->task_woken(rq, p);
rq_repin_lock(rq, rf);
}
if (rq->idle_stamp) {
u64 delta = rq_clock(rq) - rq->idle_stamp;
u64 max = 2*rq->max_idle_balance_cost;
update_avg(&rq->avg_idle, delta);
if (rq->avg_idle > max)
rq->avg_idle = max;
rq->idle_stamp = 0;
}
#endif
}

如果应该发生抢占,也不是直接踢走当前进程,而是将当前进程标记为应该被抢占。
抢占的时机
真正的抢占还需要时机,也就是需要那么一个时刻,让正在运行中的进程有机会调用一下 __schedule。
用户态的抢占时机
时机1:对于用户态的进程来讲,从系统调用中返回的那个时刻,是一个被抢占的时机
64 位的系统调用的链路位 do_syscall_64->syscall_return_slowpath->prepare_exit_to_usermode->exit_to_usermode_loop
exit_to_usermode_loop 函数
archx86entrycommon.c
static void exit_to_usermode_loop(struct pt_regs *regs, u32 cached_flags)
{
while (true) {
/* We have work to do. */
local_irq_enable();
if (cached_flags & _TIF_NEED_RESCHED)
schedule();
......
}
}

在 exit_to_usermode_loop 函数中,上面打的标记起了作用,如果被打了 _TIF_NEED_RESCHED,调用 schedule 进行调度,调用的过程和13 进程调度二_主动调度 解析的一样,会选择一个进程让出 CPU,做上下文切换。
时机2:对于用户态的进程来讲,从中断中返回的那个时刻,也是一个被抢占的时机
arch/x86/entry/entry_64.S
common_interrupt:
ASM_CLAC
addq $-0x80, (%rsp)
interrupt do_IRQ
ret_from_intr:
popq %rsp
testb $3, CS(%rsp)
jz retint_kernel
/* Interrupt came from user space */
GLOBAL(retint_user)
mov %rsp,%rdi
call prepare_exit_to_usermode
TRACE_IRQS_IRETQ
SWAPGS
jmp restore_regs_and_iret
/* Returning to kernel space */
retint_kernel:
#ifdef CONFIG_PREEMPT
bt $9, EFLAGS(%rsp)
jnc 1f
0: cmpl $0, PER_CPU_VAR(__preempt_count)
jnz 1f
call preempt_schedule_irq
jmp 0b

中断处理调用的是 do_IRQ 函数,中断完毕后分为两种情况,一个是返回用户态,一个是返回内核态。
-
返回用户态 情况,retint_user 会调用 prepare_exit_to_usermode,最终调用 exit_to_usermode_loop,和上面的逻辑一样,发现有标记则调用 schedule()。
-
返回内核态 情况 在下面
内核态的抢占时机
时机1:对内核态的执行中,被抢占的时机一般发生在 preempt_enable() 中
在内核态的执行中,有的操作是不能被中断的,所以在进行这些操作之前,总是先调用 preempt_disable() 关闭抢占,当再次打开的时候,就是一次内核态代码被抢占的机会
preempt_enable()
includelinuxpreempt.h
#define preempt_enable()
do {
barrier();
if (unlikely(preempt_count_dec_and_test()))
__preempt_schedule();
} while (0)

preempt_enable() 会调用 preempt_count_dec_and_test(),判断 preempt_count 和 TIF_NEED_RESCHED 是否可以被抢占
如果可以被抢占,就调用 preempt_schedule->preempt_schedule_common->__schedule 进行调度
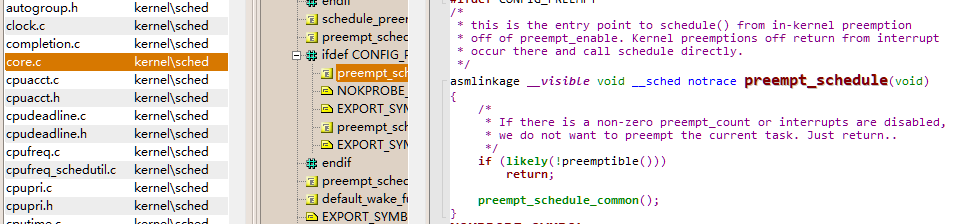
preempt_schedule 函数
kernelschedcore.c
/*
* this is the entry point to schedule() from in-kernel preemption
* off of preempt_enable. Kernel preemptions off return from interrupt
* occur there and call schedule directly.
*/
asmlinkage __visible void __sched notrace preempt_schedule(void)
{
/*
* If there is a non-zero preempt_count or interrupts are disabled,
* we do not want to preempt the current task. Just return..
*/
if (likely(!preemptible()))
return;
preempt_schedule_common();
}
**preempt_schedule_common 函数 **
kernelschedcore.c
static void __sched notrace preempt_schedule_common(void)
{
do {
/*
* Because the function tracer can trace preempt_count_sub()
* and it also uses preempt_enable/disable_notrace(), if
* NEED_RESCHED is set, the preempt_enable_notrace() called
* by the function tracer will call this function again and
* cause infinite recursion.
*
* Preemption must be disabled here before the function
* tracer can trace. Break up preempt_disable() into two
* calls. One to disable preemption without fear of being
* traced. The other to still record the preemption latency,
* which can also be traced by the function tracer.
*/
preempt_disable_notrace();
preempt_latency_start(1);
__schedule(true);
preempt_latency_stop(1);
preempt_enable_no_resched_notrace();
/*
* Check again in case we missed a preemption opportunity
* between schedule and now.
*/
} while (need_resched());
}

时机2:在内核态也会遇到中断,当中断返回的时候,返回的仍然是内核态,这个时候也是一个执行抢占的时机
arch/x86/entry/entry_64.S
common_interrupt:
ASM_CLAC
addq $-0x80, (%rsp)
interrupt do_IRQ
ret_from_intr:
popq %rsp
testb $3, CS(%rsp)
jz retint_kernel
/* Interrupt came from user space */
GLOBAL(retint_user)
mov %rsp,%rdi
call prepare_exit_to_usermode
TRACE_IRQS_IRETQ
SWAPGS
jmp restore_regs_and_iret
/* Returning to kernel space */
retint_kernel:
#ifdef CONFIG_PREEMPT
bt $9, EFLAGS(%rsp)
jnc 1f
0: cmpl $0, PER_CPU_VAR(__preempt_count)
jnz 1f
call preempt_schedule_irq
jmp 0b

中断返回的代码中,返回内核的情况,调用的是 preempt_schedule_irq
preempt_schedule_irq 函数
preempt_schedule_irq 调用 __schedule 进行调度
kernelschedcore.c
/*
* this is the entry point to schedule() from kernel preemption
* off of irq context.
* Note, that this is called and return with irqs disabled. This will
* protect us against recursive calling from irq.
*/
asmlinkage __visible void __sched preempt_schedule_irq(void)
{
enum ctx_state prev_state;
/* Catch callers which need to be fixed */
BUG_ON(preempt_count() || !irqs_disabled());
prev_state = exception_enter();
do {
preempt_disable();
local_irq_enable();
__schedule(true);
local_irq_disable();
sched_preempt_enable_no_resched();
} while (need_resched());
exception_exit(prev_state);
}

导图总结

参考资料:
趣谈Linux操作系统(极客时间)链接:
http://gk.link/a/10iXZ
欢迎大家来一起交流学习
最后
以上就是大胆橘子最近收集整理的关于一步一步学linux操作系统: 14 进程调度三完_抢占式调度的全部内容,更多相关一步一步学linux操作系统:内容请搜索靠谱客的其他文章。








发表评论 取消回复