论文作者统计(pandas字符串操作)
github
涉及知识点如下:
1、data[‘categories’].apply(lambda x: ‘cs.CV’ in x)结果理解
2、sum函数的嵌套列表元素合并
3、dataframe和series中value_counts函数的使用
代码如下:
# 导入所需的package
import json #读取数据,我们的数据为json格式的
import pandas as pd #数据处理,数据分析
import matplotlib.pyplot as plt #画图工具
# 选择类别为cs.CV下面的论文
data2 = data[data['categories'].apply(lambda x: 'cs.CV' in x)]
# 拼接所有作者
all_authors = sum(data2['authors_parsed'], [])
知识点1:data[‘categories’].apply(lambda x: ‘cs.CV’ in x)结果理解
lambda是一个匿名函数。函数体为 ‘cs.CV’ in x,即对data[‘categories’]中的每行元素通过apply进行判别,结果为True或False
从而实现对类别的选择
知识点2:sum函数的嵌套列表元素合并
sum(data2[‘authors_parsed’], [])
其中data2[‘authors_parsed’],是一个嵌套结构,最外层的每一个元素均由列表构成,列表中的元素为论文作者。
sum函数有两个参数,sun(iterable,start),start为求和的初始值,iterable为可迭代对象,sum会把可迭代对象内元素加到初始值上。也就是返回结果为start+iterable中的所有元素
例:
sum([[1,2],[3,4]], [5])
out:[5]+[1,2]+[3,4]
[5,1,2,3,4]
sum([[1,2],[3,4]], [[5]])
out:[[5]]+[1,2]+[3,4]
[[5],1,2,3,4]
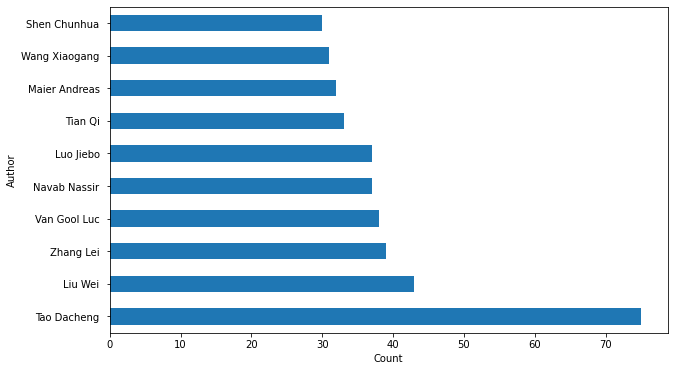
首先来完成姓名频率的统计。
# 拼接所有的作者
authors_names = [' '.join(x) for x in all_authors]
authors_names = pd.DataFrame(authors_names)
# 根据作者频率绘制直方图
plt.figure(figsize=(10, 6))
authors_names[0].value_counts().head(10).plot(kind='barh')
# 修改图配置
names = authors_names[0].value_counts().index.values[:10]
_ = plt.yticks(range(0, len(names)), names)
plt.ylabel('Author')
plt.xlabel('Count')
知识点3、dataframe和series中value_counts函数的使用
作用是计算dataframe或series中各字符串出现的次数,默认对频率降序排列完整语法和参数为
Series.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
normalize代表计数项归一化,sort代表排序默认降序,ascending表示升序排列,bins指的是对数值型数据的分段计数,dropna表示不包括对NA的计数
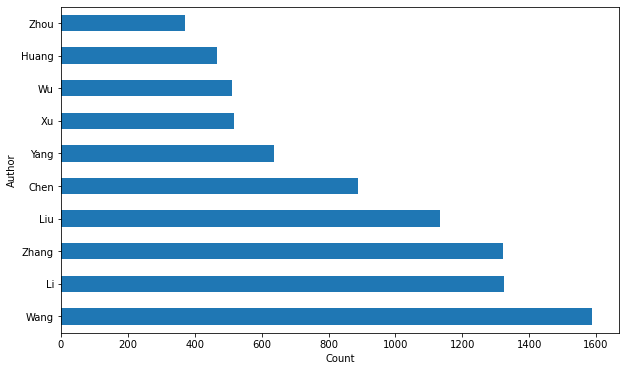
统计姓名的姓
authors_lastnames = [x[0] for x in all_authors]
authors_lastnames = pd.DataFrame(authors_lastnames)
plt.figure(figsize=(10, 6))
authors_lastnames[0].value_counts().head(10).plot(kind='barh')
names = authors_lastnames[0].value_counts().index.values[:10]
_ = plt.yticks(range(0, len(names)), names)
plt.ylabel('Author')
plt.xlabel('Count')
最后
以上就是舒心蜜蜂最近收集整理的关于论文作者统计(pandas字符串操作)的全部内容,更多相关论文作者统计(pandas字符串操作)内容请搜索靠谱客的其他文章。








发表评论 取消回复