由浅入深玩转快速排序算法
快速排序可以说是最快的通用排序算法,它甚至被誉为20世纪科学和工程领域的十大算法之一。在众多排序算法中其无论是时间复杂度还是空间复杂度都颇具优势。作为开发工程师,我们很有必要了解它的思想。接下来将由在下为大家一步步分析这一伟大排序算法的原理与实现思路。
主要从三个方向展开论述:
1、算法基本原理与实现:介绍两种常用的实现思路。
2、性能特点:介绍算法高效的秘诀与其弱点。
3、算法优化:介绍PHP7与Java等成熟语言对算法的优化应用
1
快速排序算法基本原理
快速排序是一种分治的排序算法,即将大数组拆分成小数组处理。通过一趟排序将待排数组分成两个子数组,使得一个子数组的元素均比另一个子数组的元素小。再分别将子数组进行上述排序,最终使得整个数组有序。其基本实现可以分为以下3步:
1、选中轴(pivot):从待排序的目标数组中挑选一个元素作为中轴元素。
2、分区(partition):把剩余的元素与中轴元素作比较,将小于等于中轴元素的放到中轴元素的左边,将大于中轴元素的放到中轴元素的右边。
3、 递归:以当前中轴元素的位置为界,将左子数组和右子数组看成两个新的数组并重复上述操作,直到子数组的元素个数小于等于1。
快速排序算法可以有多种实现方式,选择不同的中轴与选择相同的中轴时均有不同的实现方法。下面举出两个例子供大家参考,方便大家理解实现思路。
1.1 左右扫描,交换元素
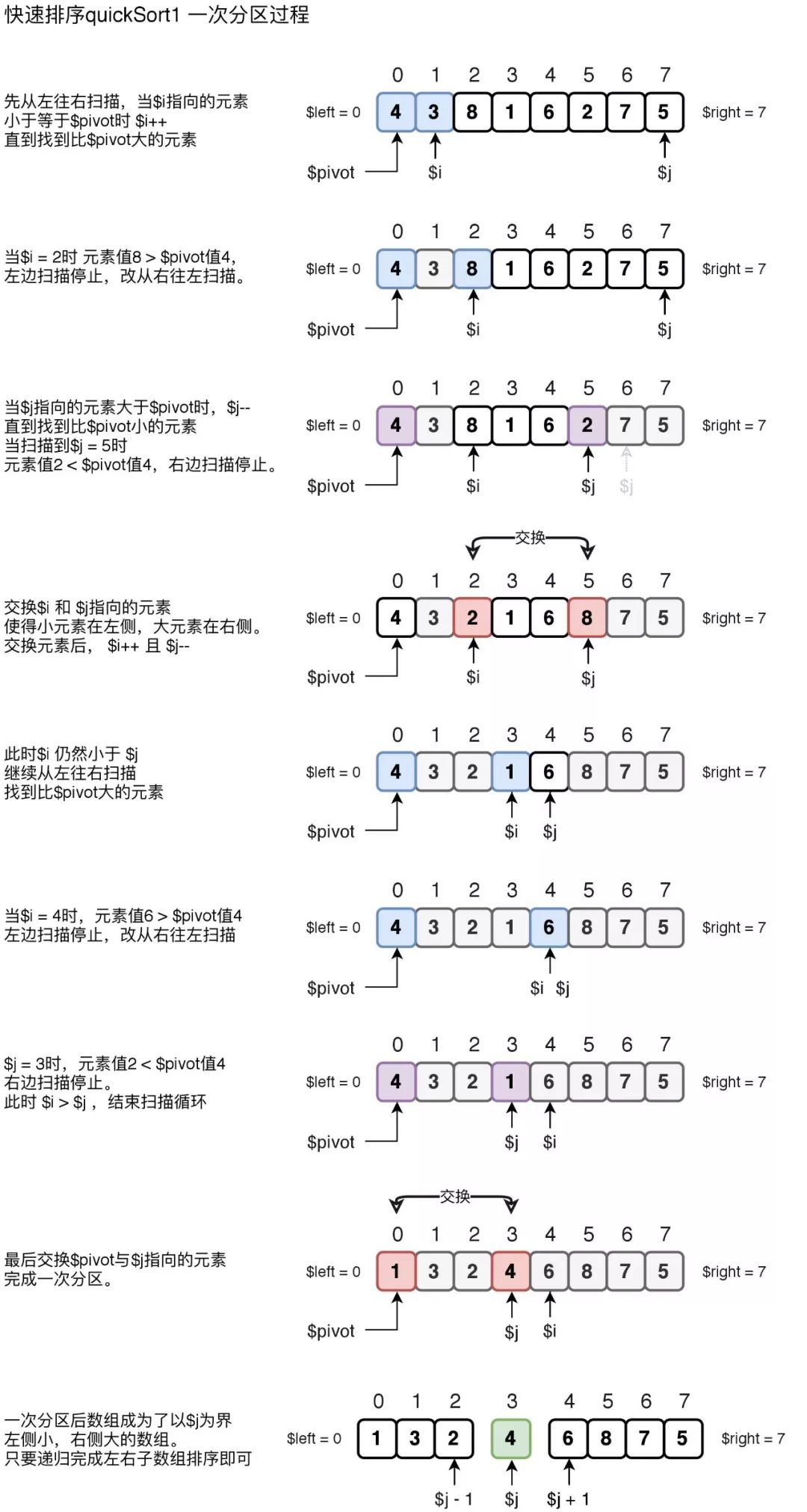
下图quickSort1是采用了此方案实现的快速排序的一次分区过程,待排序数组是$arr = [4, 3, 8, 1, 6, 2, 7, 5];
1.2 左右扫描,挖坑补坑
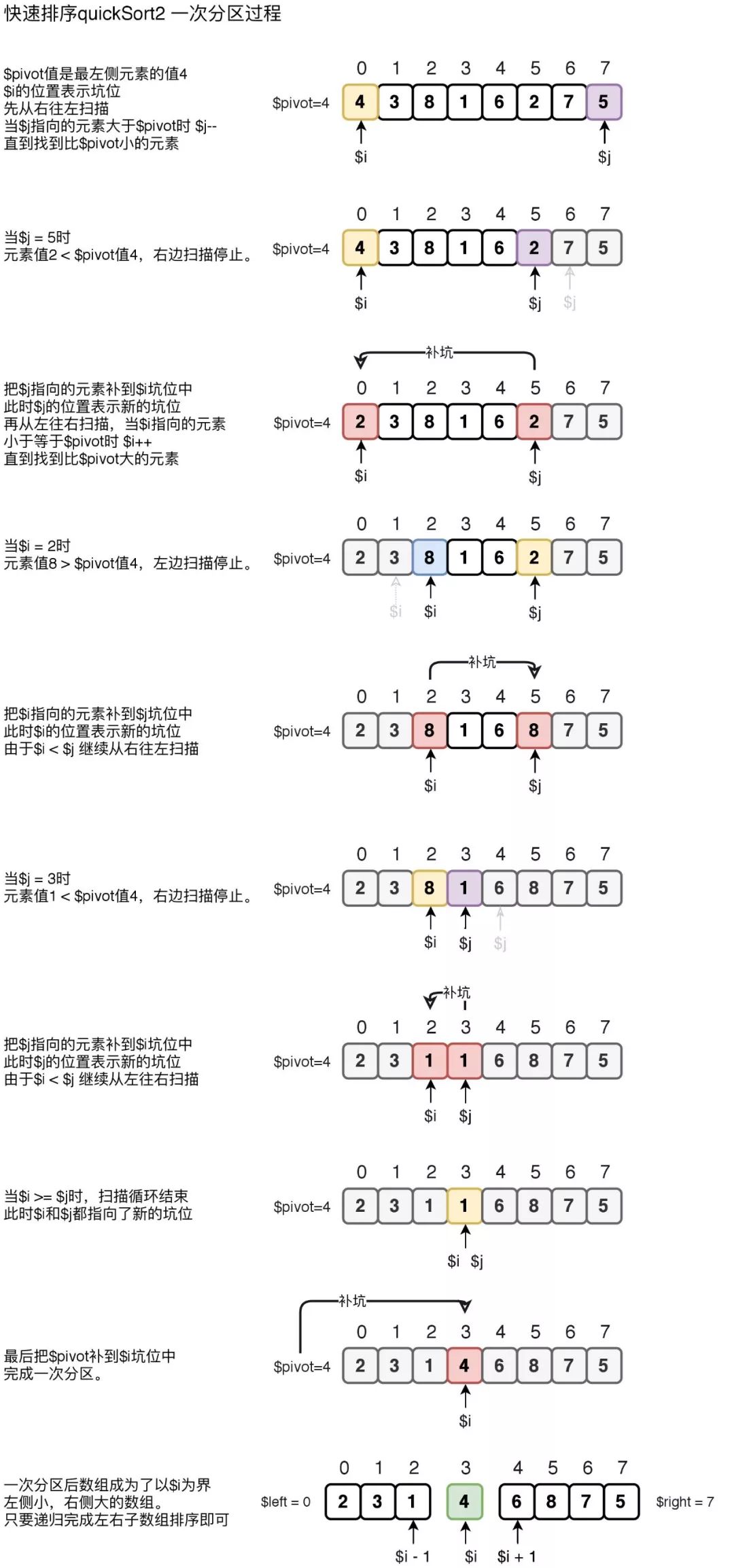
在第一个实现思路中,当在左侧找到大于中轴元素和在右侧找到小于中轴元素的两个元素位置时,需要对两个元素进行交换。其中涉及到一个新的临时变量的操作。下面的实现采用填坑的思路直接赋值,省去了临时变量的读写操作。
下图quickSort2是采用了一端挖坑一端补坑的快速排序的一次分区过程,待排序数组同样是$arr = [4, 3, 8, 1, 6, 2, 7, 5];
2
性能特点
快速排序之所以快速主要有两个原因:
1、内循环操作简洁
在分区方法的内循环中仅采用递增或递减的索引将数组元素与一个定值作比较。并且没有在内循环中移动数据,很难想象在排序算法中能有比这操作更简洁的内循环了。
2、比较次数少
快速排序的效率依赖于切分数组的效果,即依赖于中轴元素的值。其最佳的情况是每次都正好将数组对半切分。在这种情况下快速排序的时间复杂度为O(Nlog2N)。而在每个子数组里面的数据也不会与其他子数组的数据做重复比较,大幅提升了效率。
由此我们也很容易看出快速排序的缺点:在分区不平衡的时候可能会出现极低的效率。快速排序最坏情况的时间复杂度为O(N2)。
3
算法优化
3.1 解决分区不平衡
由于中轴元素的选择直接决定了快速排序的效率,为了使算法在数组逆序或将近有序等恶劣场景中都能达到高效率,我们可以采用以下办法解决分区“一边倒”的情况。
1、间接解决:在排序前使数组保持随机性,即先对待排序数组进行乱序操作,再做快速排序,降低分区不平衡的概率。
2、直接解决:采用三数取中法或三取样切分,随机选取中轴元素。
3.2 切换到插入排序
对于小数组排序,插入排序比快速排序更快。因此在排序元素数量较小的数组时应该切换到插入排序。如PHP7的sort()排序函数的实现:在数组长度为 5~16 时采用插入排序否则采用快速排序。
(https://github.com/php/php-src/blob/PHP-7.4/Zend/zend_sort.c)
3.3 三切分快速排序
在实际应用中经常会出现含有大量重复元素的数组,例如我们需要将大量用户数据按VIP等级排序或按生日日期排序。此时采用上述实现方案的经典快速排序则显得有点笨,因为当一个子数组中的元素都是重复时,我们的算法仍然会将它切分成更小的数组递归排序。在有大量重复元素的情况下,这无疑会做很多无用功,使得时间复杂度提高到平方级别(O(N2))。而三向切分快速排序,则是为此而生,专门应对有大量重复元素数组的排序情况,是一种能把时间复杂度从线性对数级别(O(Nlog2N)) 降到线性级别(O(N))的算法实现。
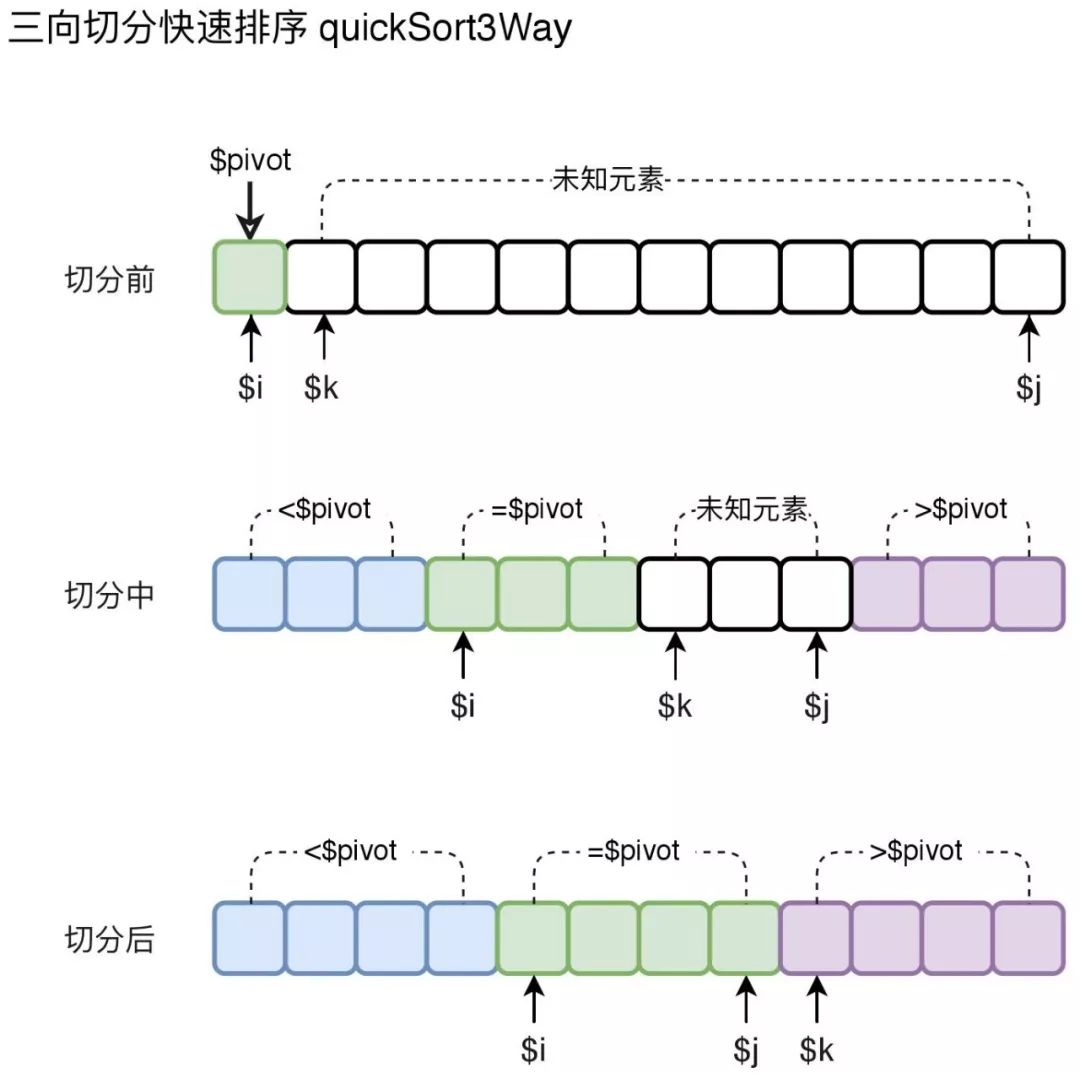
基本实现思路:从左往右扫描数组,利用三个变量$i,$j,$k把数组分成4部分。
如下图所示:
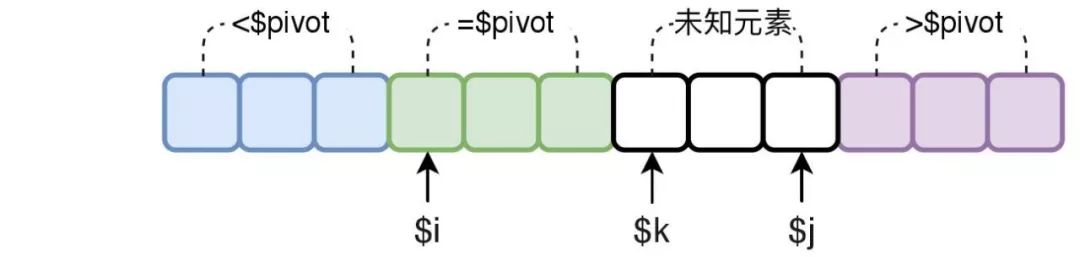
分区刚开始,选择数组最左侧的元素作为中轴元素。$i指向最左侧元素,$k指向最左侧元素的下一个元素,$j指向最右侧的元素。
如下图所示:
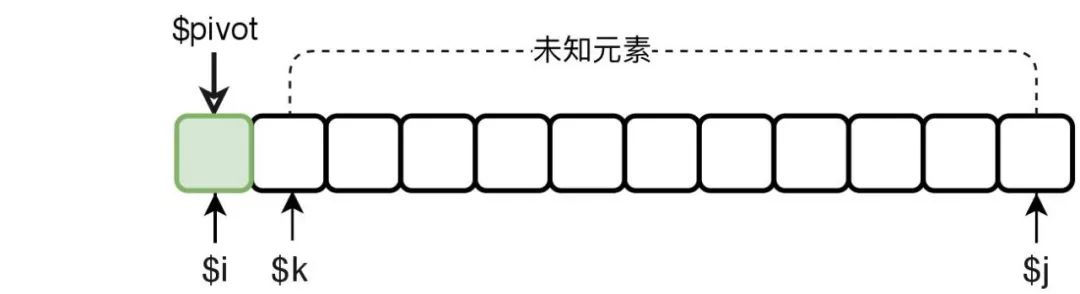
从左往右扫描数组,直到$k与$j相交($k > $j)。通过扫描,把未知元素按照其与中轴元素的大小关系放入不同的区间,不断减少未知元素的数量,以完成分区。
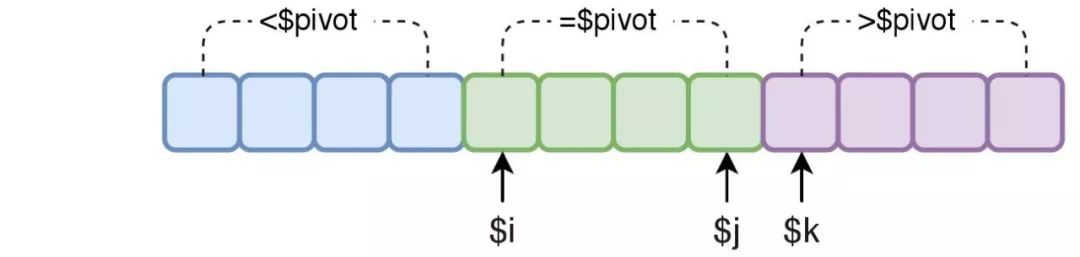
当一次扫描结束后$i和$j分别指向了【=$pivot】区间的起始和结束位置。最后分别递归小于中轴部分的数组和大于中轴部分的数组,即可完成排序。
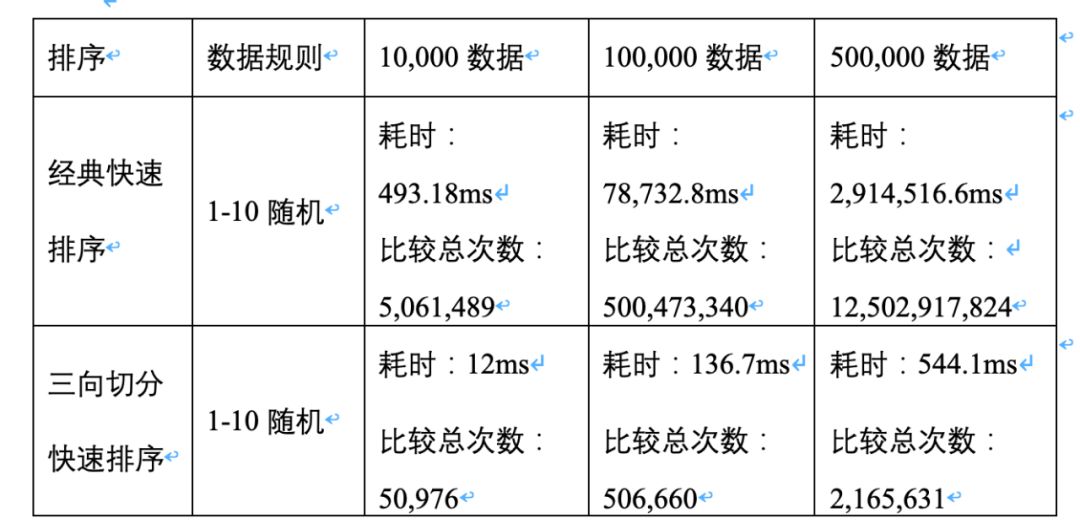
我们对有大量重复数据的数组进行排序,验证三向切分快速排序的效果。(此处的测试仅是为了体现算法实现思想的差异会出现不同的性能效果,并不能严谨说明两者的性能程度差距。)分别用1万,10万和50万数据量的数组进行测试对比,数据生成规则是1-10内随机生成,可以说数据重复概率极高。每个情况进行5次测试求平均值,得出以下数据表格:
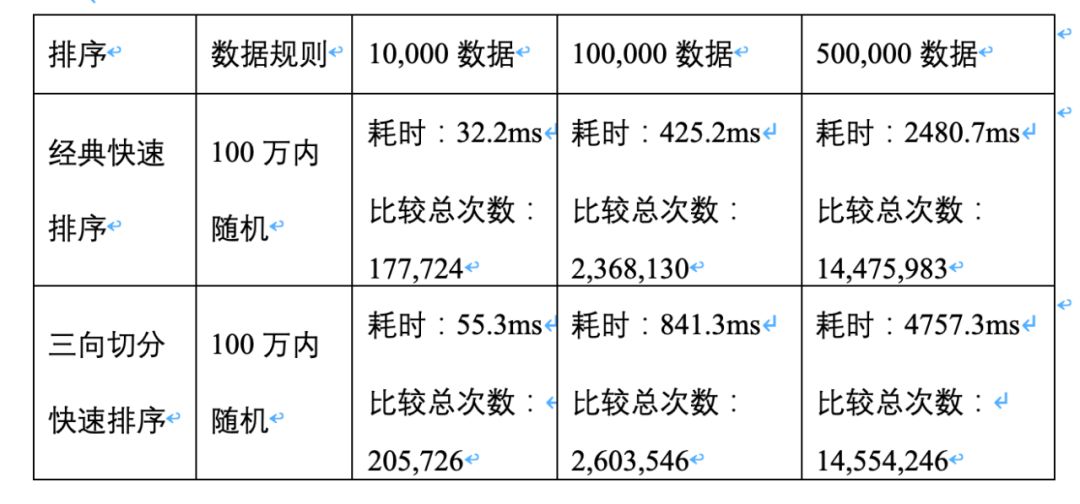
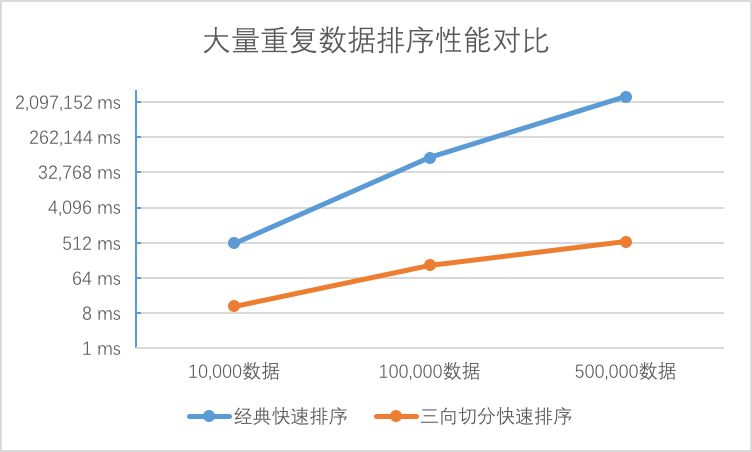
可见在有大量重复数据的排序中,三向切分秒杀了经典快速排序。表中所示在对50万级别的数据排序时,经典快速排序耗时高达48分钟(等了好久才等到这个数据),而三向切分快速排序仅用了0.5秒。
而在重复元素较少的数组中,三向切分的性能并无优势,相比经典快速排序需要消耗将近2倍的时间:
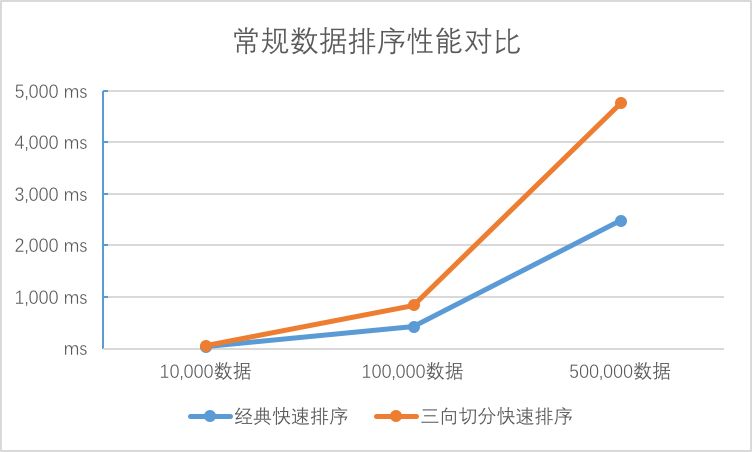
是否有一种实现方式既能兼顾有大量重复元素和低重复元素数组的排序呢?接下来,我们看看Java中Arrays.sort()的排序实现。
3.4 双轴快速排序
在JDK1.7中给出了双轴快速排序(DualPivotQuicksort)的思想,当然仅靠一个排序思想无法应对复杂的业务场景,为保证最高的排序效率,Java在实际排序中采用了一套相对成熟及复杂的方案,根据元素的数量及有序性采用了不同的排序方案。双轴快速排序在有大量重复元素的排序中表现良好,同时能兼顾大量非重复元素的数组排序,其在实现思路上,跟三向切分快速排序有类似之处。已经理解了上面介绍过的三向切分,再来理解双轴快速排序就不难了。大致实现思路如下图所示:
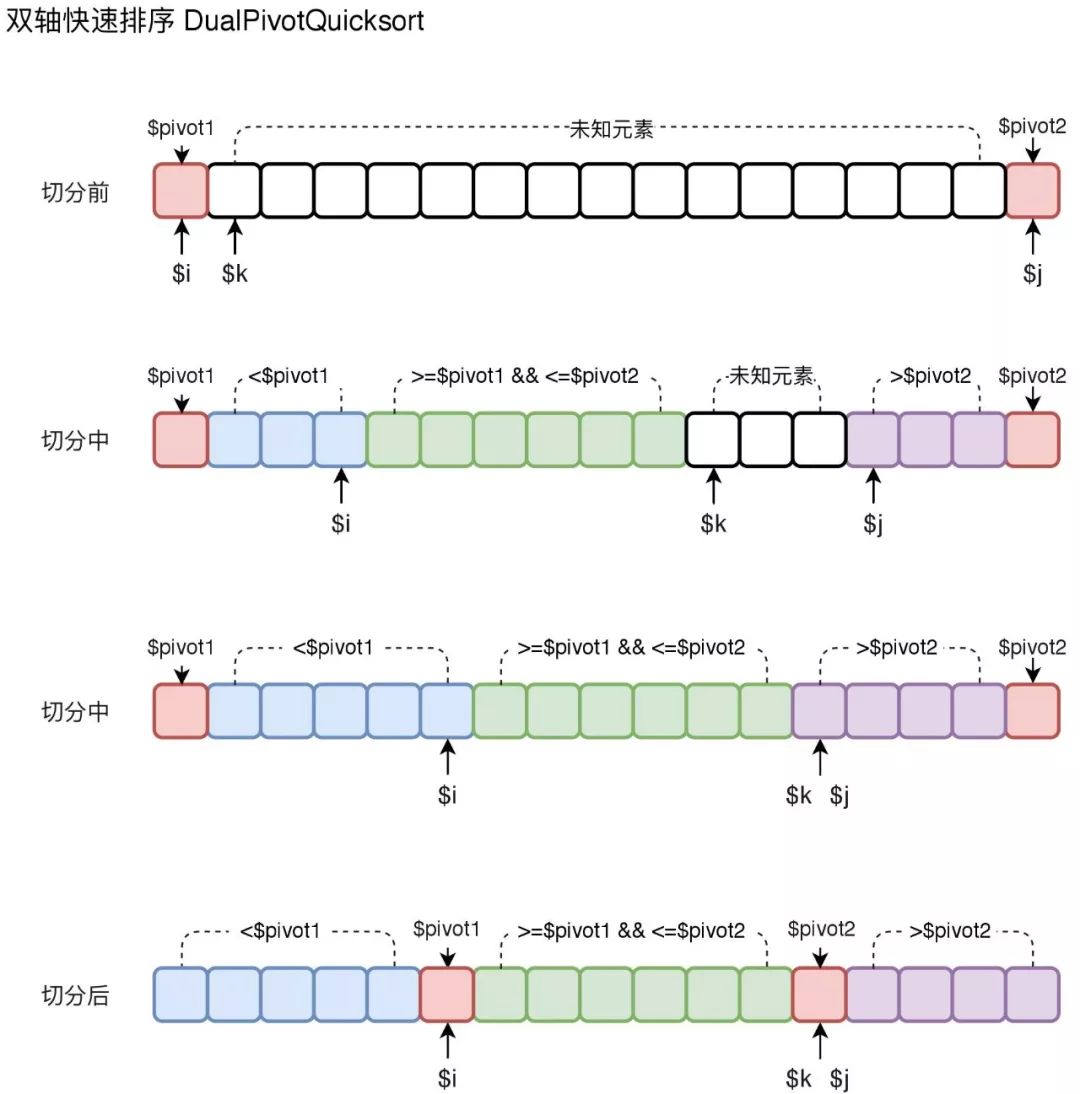
完成分区后,分别对双轴切分出来的三个区间进行递归排序即可。(受限于篇幅,以上所有算法实现只讲述思路并未贴出代码,如感兴趣的同学可以找作者要PHP版的实现代码。)
总结
本文主要讲述了快速排序的原理及实现思路,总结为以下三点:
1、基本原理与实现:可采用元素交换或挖坑补坑的方式实现快速排序。
2、算法性能特点:
快速高效的两个原因:其一内循环操作简洁;其二比较次数较少
性能弱点:中轴元素选择不当可能导致性能极其低下
3、算法优化:
解决分区不平衡的2种办法
对小数组排序采用插入排序
对有大量重复元素的数组采用三向切分快速排序
JDK1.7中双轴快速排序的实现思路
参考文献:
[1]《算法(第4版)》
[2]《QUICKSORTING - 3-WAY AND DUAL PIVOT》https://rerun.me/2013/06/13/quicksorting-3-way-and-dual-pivot/
[3]《Java中双基准快速排序方法的具体实现》http://www.mamicode.com/info-detail-2395124.html
排版 |川芮


最后
以上就是满意香菇最近收集整理的关于实现快速排序的算法_由浅入深玩转快速排序算法的全部内容,更多相关实现快速排序内容请搜索靠谱客的其他文章。








发表评论 取消回复