本文的创新在于,使用神经网络框架来代替MF中的内积,将MF和MLP的线性以及非线性特点相结合,使用预训练参数来初始化模型,进一步提升模型性能。本文思路清晰,逻辑严谨,细节说明很到位,实验对比完整且比较有说服力,很值得学习。因此我将笔记整理出来分享一下,如果有不对的地方,多多包涵,敬请批评指出。
目录
- 摘要
- 引言
- 本文的贡献
- 矩阵分解的限制
- 神经协同过滤框架
- NCF优化方法
- 通用矩阵分解
- 多层感知机(MLP)
- 通用矩阵分解和多层感知机的融合(NeuMF)
- 预训练
- 实验数据
- 评价指标
- 对比算法
- 实验设置
- 实验结果
- 原论文开源代码地址
- 结果复现
摘要
本文致力于使用基于神经网络的技术来解决推荐中的关键问题–协同过滤-基于隐式反馈(保持原评分-显式反馈,将原评分大于0的置1-隐式反馈)。本文提出了一种简称NCF(Neural network based Collaborative Filtering)的通用神经框架来代替内积,以从数据中学习任意的函数。为了更好地建模非线性关系,本文提出利用多层感知机来学习user-item交互函数。
- Jaccard coefficient
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ = ∣ A ∩ B ∣ ∣ A ∣ + ∣ B ∣ − ∣ A ∩ B ∣ J(A, B)=frac{|A cap B|}{|A cup B|}=frac{|A cap B|}{|A|+|B|-|A cap B|} J(A,B)=∣A∪B∣∣A∩B∣=∣A∣+∣B∣−∣A∩B∣∣A∩B∣
- Jaccard distance
d j ( A , B ) = 1 − J ( A , B ) = ∣ A ∪ B ∣ − ∣ A ∩ B ∣ ∣ A ∪ B ∣ = A Δ B ∣ A ∪ B ∣ d_{j}(A, B)=1-J(A, B)=frac{|A cup B|-|A cap B|}{|A cup B|}=frac{A Delta B}{|A cup B|} dj(A,B)=1−J(A,B)=∣A∪B∣∣A∪B∣−∣A∩B∣=∣A∪B∣AΔB
Jaccard 距离越大,样本相似度越低
引言
推荐->矩阵分解->矩阵分解扩展方法->矩阵分解的不足之处(内积)->神经网络的表现
本文研究基于隐式反馈:
y u i = { 1 , if interaction (user u , item i ) is observed; 0 , otherwise. y_{u i}=left{begin{array}{ll}1, & text { if interaction (user } u, text { item } i) text { is observed; } \ 0, & text { otherwise. }end{array}right. yui={1,0, if interaction (user u, item i) is observed; otherwise.
本文的贡献
- 本文提出了一种神经网络结构来建模users和items的潜在特征,并且还设计了一种基于神经网络的通用框架(NCF)来实现协同过滤。
- 本文证明了MF是NCF的一个特例,利用一个多层感知机来赋予NCF更高层次的非线性能力。
- 本文通过在两个真实数据集上的扩展实验,证明了NCF算法的有效性。
矩阵分解的限制
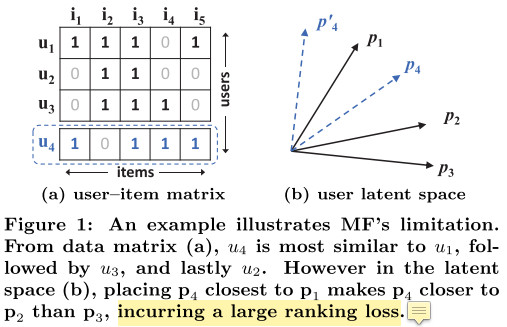
1(a)采用Jaccard coefficient计算相似度,为了解决这个限制,本文通过DNNs来学习这个交互函数。
神经协同过滤框架
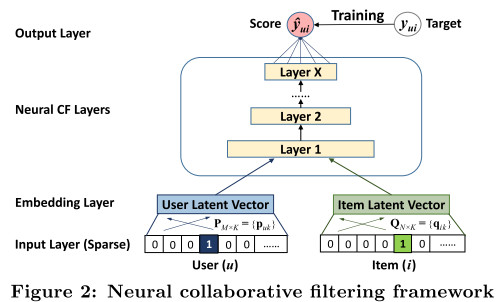
输入是user和item的one-hot向量,然后再通过Embedding层得到user和item的潜在特征向量,然后再后续操作。
而本文提出了一种新的神经矩阵分解模型,该模型集成了NCF框架下的MF和MLP,结合了MF的线性能力以及MLP的非线性能力。
本文采用的是point-wise,未来工作可能会使用pair-wise。
NCF优化方法
- square loss
L s q r = ∑ ( u , i ) ∈ Y ∪ Y − w u i ( y u i − y ^ u i ) 2 L_{s q r}=sum_{(u, i) in mathcal{Y} cup mathcal{Y}^{-}} w_{u i}left(y_{u i}-hat{y}_{u i}right)^{2} Lsqr=(u,i)∈Y∪Y−∑wui(yui−y^ui)2
其中 w u i w_{u i} wui表示样本权重,通常MF中 w u i = 1 w_{u i}=1 wui=1
- probabilistic approach
似然函数
p ( Y , Y − ∣ P , Q , Θ f ) = ∏ ( u , i ) ∈ Y y ^ u i ∏ ( u , j ) ∈ Y − ( 1 − y ^ u j ) pleft(mathcal{Y}, mathcal{Y}^{-} mid mathbf{P}, mathbf{Q}, Theta_{f}right)=prod_{(u, i) in mathcal{Y}} hat{y}_{u i} prod_{(u, j) in mathcal{Y}^{-}}left(1-hat{y}_{u j}right) p(Y,Y−∣P,Q,Θf)=(u,i)∈Y∏y^ui(u,j)∈Y−∏(1−y^uj)
取概率的负对数
L = − ∑ ( u , i ) ∈ Y log y ^ u i − ∑ ( u , j ) ∈ Y − log ( 1 − y ^ u j ) = − ∑ ( u , i ) ∈ Y ∪ Y − y u i log y ^ u i + ( 1 − y u i ) log ( 1 − y ^ u i ) begin{aligned} L &=-sum_{(u, i) in mathcal{Y}} log hat{y}_{u i}-sum_{(u, j) in mathcal{Y}^{-}} log left(1-hat{y}_{u j}right) \ &=-sum_{(u, i) in mathcal{Y} cup mathcal{Y}^{-}} y_{u i} log hat{y}_{u i}+left(1-y_{u i}right) log left(1-hat{y}_{u i}right) end{aligned} L=−(u,i)∈Y∑logy^ui−(u,j)∈Y−∑log(1−y^uj)=−(u,i)∈Y∪Y−∑yuilogy^ui+(1−yui)log(1−y^ui)
其实这就是二分类任务中常用的交叉熵,也常被成为log loss
通用矩阵分解
y ^ u i = a out ( h T ( p u ⊙ q i ) ) hat{y}_{u i}=a_{text {out}}left(mathbf{h}^{T}left(mathbf{p}_{u} odot mathbf{q}_{i}right)right) y^ui=aout(hT(pu⊙qi))
a o u t a_{out} aout是激活函数,本文使用sigmoid,如果将 a o u t a_{out} aout取自己, h T {h}^{T} hT是一个全为1的向量,那么这就是MF
多层感知机(MLP)
为了更好地建模user和item,不能只是简单地将两个向量进行拼接,因为这样并不能起到user和item之间的特征交互作用,为了解决这个问题,在拼接后的向量添加全连接层,因此使用多层感知机结构。
z 1 = ϕ 1 ( p u , q i ) = [ p u q i ] ϕ 2 ( z 1 ) = a 2 ( W 2 T z 1 + b 2 ) … … ϕ L ( z L − 1 ) = a L ( W L T z L − 1 + b L ) y ^ u i = σ ( h T ϕ L ( z L − 1 ) ) begin{aligned} mathbf{z}_{1} &=phi_{1}left(mathbf{p}_{u}, mathbf{q}_{i}right)=left[begin{array}{c} mathbf{p}_{u} \ mathbf{q}_{i} end{array}right] \ phi_{2}left(mathbf{z}_{1}right) &=a_{2}left(mathbf{W}_{2}^{T} mathbf{z}_{1}+mathbf{b}_{2}right) \ & ldots ldots \ phi_{L}left(mathbf{z}_{L-1}right) &=a_{L}left(mathbf{W}_{L}^{T} mathbf{z}_{L-1}+mathbf{b}_{L}right) \ hat{y}_{u i} &=sigmaleft(mathbf{h}^{T} phi_{L}left(mathbf{z}_{L-1}right)right) end{aligned} z1ϕ2(z1)ϕL(zL−1)y^ui=ϕ1(pu,qi)=[puqi]=a2(W2Tz1+b2)……=aL(WLTzL−1+bL)=σ(hTϕL(zL−1))
隐层激活函数可选:sigmoid,tanh,relu
-
sigmoid :sigmoid将数值规约到[0, 1],但容易遇到饱和问题,当神经元的输出值接近0或者1的时候就会停止学习
-
tanh:虽然tanh被大量使用,但它也只是一定程度上缓解了sigmoid的问题,因为它可以被视为另一种重新调整的sigmoid( t a n h ( x / 2 ) = 2 σ ( x ) − 1 ) tanh(x/2) = 2σ(x) − 1) tanh(x/2)=2σ(x)−1))
-
relu:我们更倾向于选择relu作为激活函数,relu从生物学角度来说是可行的,并且被证明是不饱和的
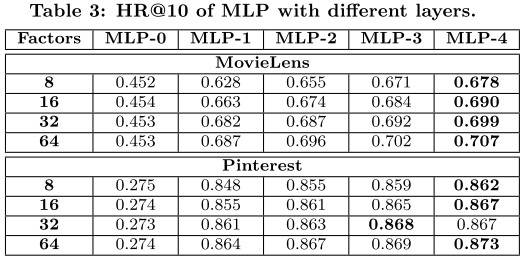
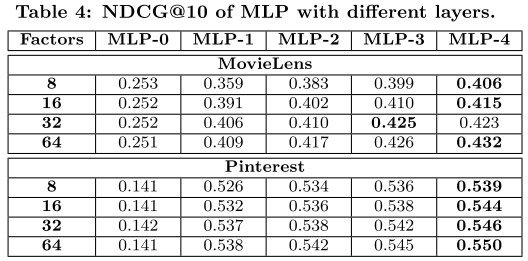
至于隐层神经元个数设置,本文采用金字塔结构,即 [32, 16, 8, 4, 2, 1]
通用矩阵分解和多层感知机的融合(NeuMF)
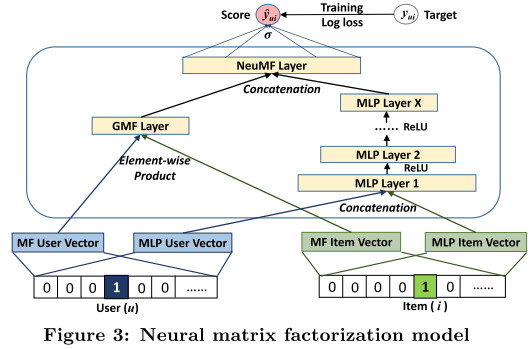
一种直接的方法是GMF和MLP共享Embedding,但这样可能会限制融合的作用,因此本文采用了不用大小的Embedding size,模型输出为:
ϕ G M F = p u G ⊙ q i G ϕ M L P = a L ( W L T ( a L − 1 ( … a 2 ( W 2 T [ p u M ] + b 2 ) … ) ) + b L ) y ^ u i = σ ( h T [ ϕ G M F ϕ M L P ] ) begin{aligned} phi^{G M F} &=mathbf{p}_{u}^{G} odot mathbf{q}_{i}^{G} \ phi^{M L P} &=a_{L}left(mathbf{W}_{L}^{T}left(a_{L-1}left(ldots a_{2}left(mathbf{W}_{2}^{T}left[mathbf{p}_{u}^{M}right]+mathbf{b}_{2}right) ldotsright)right)+mathbf{b}_{L}right) \ hat{y}_{u i} &=sigmaleft(mathbf{h}^{T}left[begin{array}{c} phi^{G M F} \ phi^{M L P} end{array}right]right) end{aligned} ϕGMFϕMLPy^ui=puG⊙qiG=aL(WLT(aL−1(…a2(W2T[puM]+b2)…))+bL)=σ(hT[ϕGMFϕMLP])
预训练
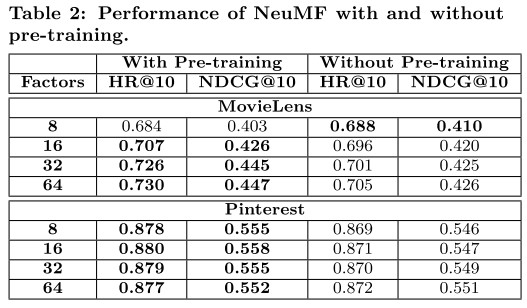
由于NeuMF的目标函数具有非凸的性质,使用梯度下降求解只能找到局部最优解,因此参数初始化显得格外重要;因为NeuMF集成了GMF和MLP模型,因此本文提出使用GMF和MLP模型的参数作为NeuMF模型的初始化参数。
首先使用随机初始化的方式生成GMF和MLP的参数,然后训练直至收敛,使用Adam(它通过对频繁的参数执行较小的更新而对不频繁的参数进行较大的更新来调整每个参数的学习率,更快的收敛)优化。初始化NeuMF时使用GMF和MLP中相应部分的参数来初始化即可,不过初始化参数h时使用以下方法:
h ← [ α h G M F ( 1 − α ) h M L P ] mathbf{h} leftarrowleft[begin{array}{c} alpha mathbf{h}^{G M F} \ (1-alpha) mathbf{h}^{M L P} end{array}right] h←[αhGMF(1−α)hMLP]
其中参数 α = 0.5 alpha=0.5 α=0.5,使用预训练的初始化权重之后,NeuMF使用SGD进行参数优化。
实验数据
-
MovieLens:http://grouplens.org/datasets/movielens/1m/
-
Pinterest:https://sites.google.com/site/xueatalphabeta/ academic-projects
评价指标
-
HR( H i t R a t i o Hit Ratio HitRatio)
-
NDCG( N o r m a l i z e d D i s c o u n t e d C u m u l a t i c e G a i n Normalized Discounted Cumulatice Gain NormalizedDiscountedCumulaticeGain)
对比算法
- ItemPop
- ItemKNN
- BPR
- eALS
实验设置
- 使用深度学习框架Theano-Keras
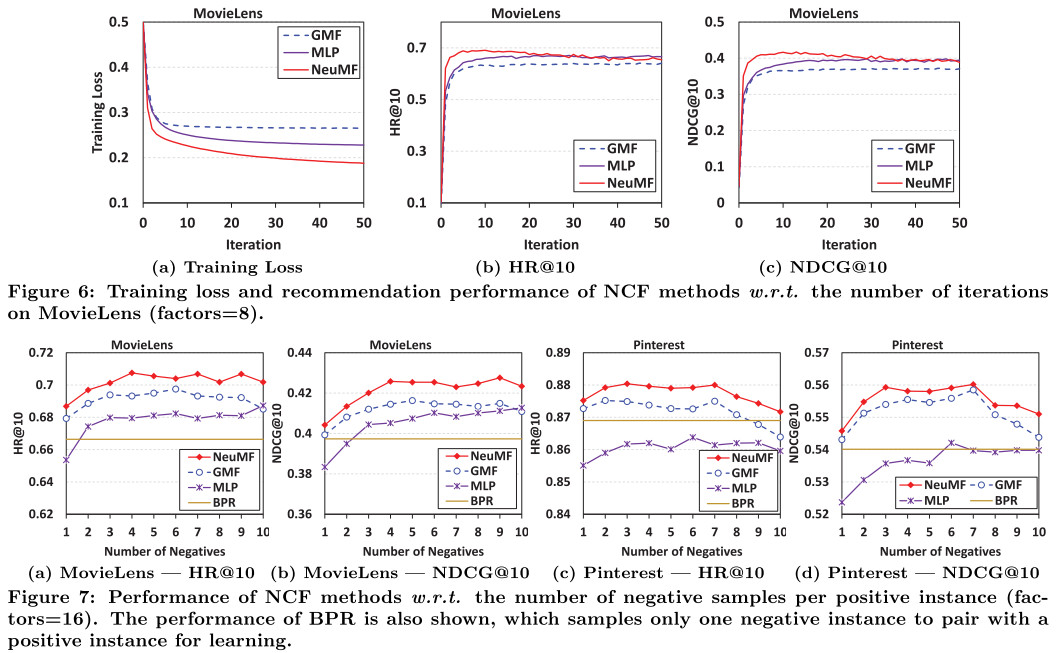
- 负采样比例1:4
- 参数随机初始化-均值为1标准差为0.01的正太(高斯)分布
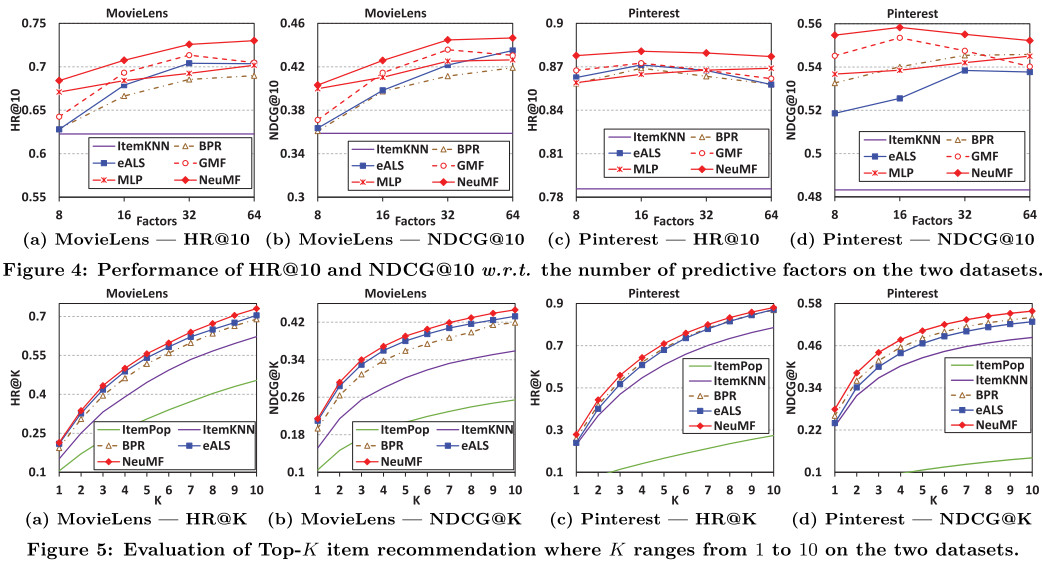
实验结果
原论文开源代码地址
https://github.com/hexiangnan/neural_collaborative_filtering
结果复现
- GMF
python GMF.py --dataset ml-1m --epochs 20 --batch_size 256 --num_factors 8 --regs [0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
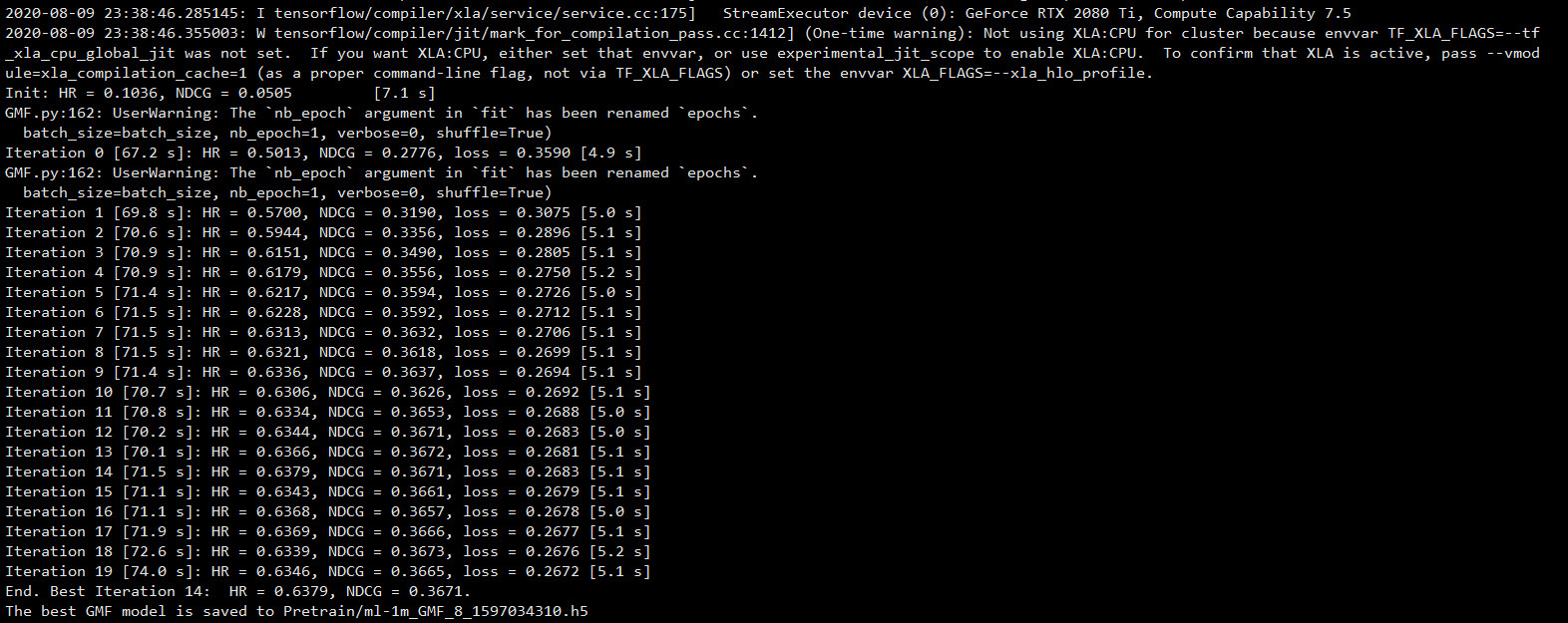
- MLP
python MLP.py --dataset ml-1m --epochs 20 --batch_size 256 --layers [64,32,16,8] --reg_layers [0,0,0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
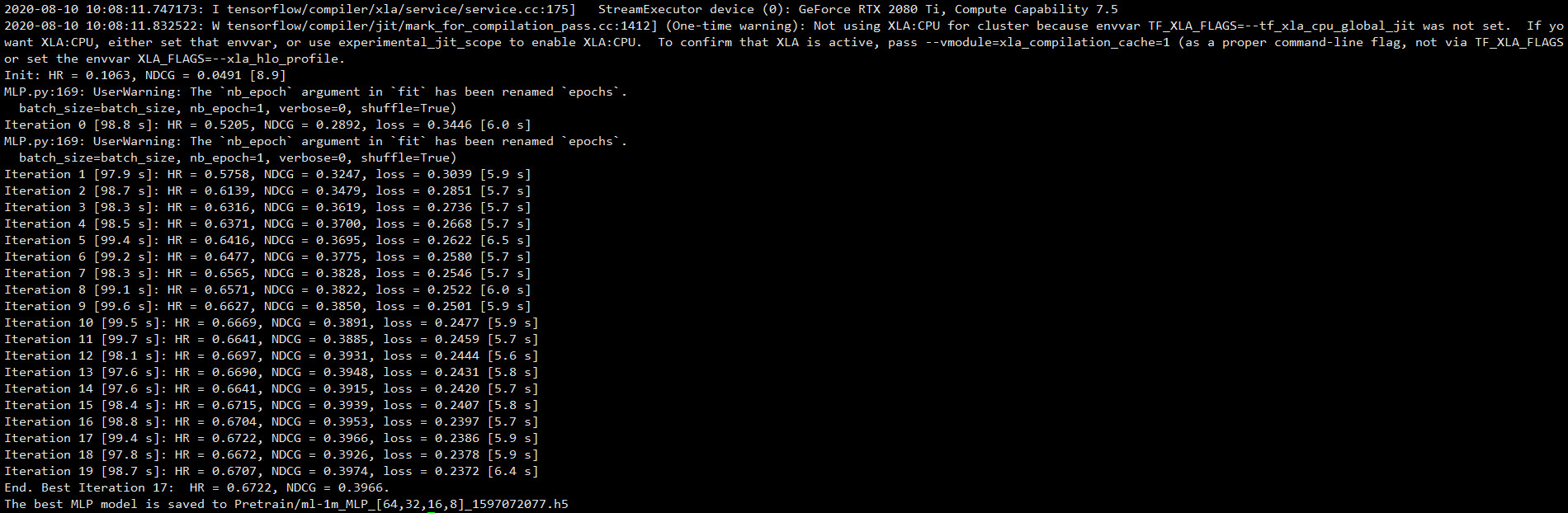
- NeuMF-With-Pretrain
python NeuMF.py --dataset ml-1m --epochs 20 --batch_size 256 --num_factors 8 --layers [64,32,16,8] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1 --mf_pretrain Pretrain/ml-1m_GMF_8_1501651698.h5 --mlp_pretrain Pretrain/ml-1m_MLP_[64,32,16,8]_1501652038.h5
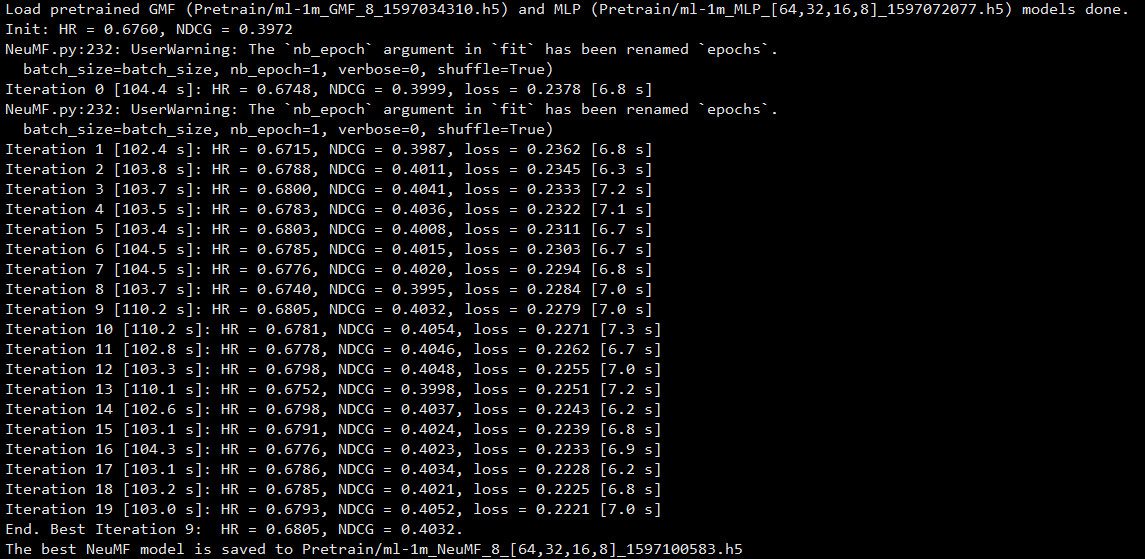
- NeuMF-Without-Pretrain
python NeuMF.py --dataset ml-1m --epochs 20 --batch_size 256 --num_factors 8 --layers [64,32,16,8] --reg_mf 0 --reg_layers [0,0,0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
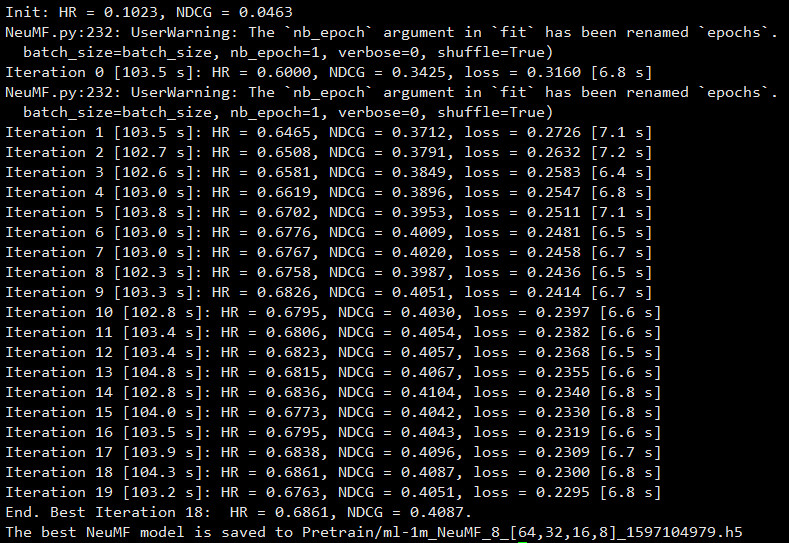
最后
以上就是笨笨白昼最近收集整理的关于《Neural Collaborative Filtering》论文阅读笔记的全部内容,更多相关《Neural内容请搜索靠谱客的其他文章。







![[论文阅读&翻译]Item-to-Item Collaborative Filtering](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)
发表评论 取消回复