一、前言
在文章《Kubernetes生产实践系列之二十八:Kubernetes基础技术之容器关键技术介绍》中,对于Docker容器技术依赖的namespace、cgroup和UnionFS技术进行了基本的介绍,本文基于Centos进行上述关键技术的实践分析。
操作系统版本情况:
CentOS Linux release 7.5.1804 (Core)
Docker的版本情况:
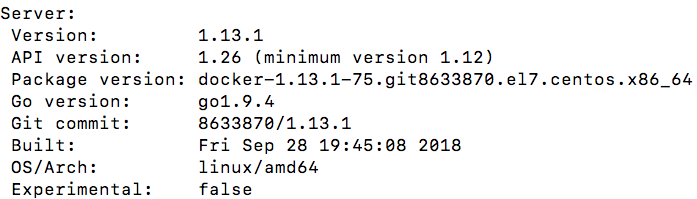
转载自https://blog.csdn.net/cloudvtech
二、namespace的实践
2.1 查看系统是否支持相关的namespace技术
cat /boot/config-3.10.0-957.el7.x86_64 | grep CONFIG_*_NS
CONFIG_UTS_NS=y
CONFIG_IPC_NS=y
CONFIG_USER_NS=y
CONFIG_PID_NS=y
CONFIG_NET_NS=y对于选定的容器fluentd-s3-t69tt
docker ps | grep fluentd-s3-t69tt
e5f276b4ffe1 d7fdad56bf1b "tini -- /fluentd/en…" 2 weeks ago Up 2 weeks k8s_fluentd-s3_fluentd-s3-t69tt_third-party_5ad2831a-ce36-11ea-9f78-d26db868d6e6_0
101b326ce184 registry-vpc.cn-shanghai.aliyuncs.com/acs/pause-amd64:3.0 "/pause" 2 weeks ago Up 2 weeks k8s_POD_fluentd-s3-t69tt_third-party_5ad2831a-ce36-11ea-9f78-d26db868d6e6_0
容器ID为e5f276b4ffe1,对应的外部PID:
docker inspect -f {{.State.Pid}} 15132
15132查看主机上PID之下namespaces的情况:
ls -l /proc/15132/ns

通过lsns可以反向查看ns对应的进程情况:
lsns | grep 4026532499
4026532499 uts 3 15132 root tini -- /fluentd/entrypoint.sh通过nsenter可以进入某个进程的ns:
[root@iZukkkkf6gqdhf0dbbht8rtbmbZ ~]# nsenter -u -t 15132
[root@fluentd-s3-t69tt ~]# hostname
fluentd-s3-t69tt
nsenter的命令参考如下:
nsenter [options] [program [arguments]]
options:
-t, --target pid:指定被进入命名空间的目标进程的pid
-m, --mount[=file]:进入mount命令空间。如果指定了file,则进入file的命令空间
-u, --uts[=file]:进入uts命令空间。如果指定了file,则进入file的命令空间
-i, --ipc[=file]:进入ipc命令空间。如果指定了file,则进入file的命令空间
-n, --net[=file]:进入net命令空间。如果指定了file,则进入file的命令空间
-p, --pid[=file]:进入pid命令空间。如果指定了file,则进入file的命令空间
-U, --user[=file]:进入user命令空间。如果指定了file,则进入file的命令空间
-G, --setgid gid:设置运行程序的gid
-S, --setuid uid:设置运行程序的uid
-r, --root[=directory]:设置根目录
-w, --wd[=directory]:设置工作目录如果没有给出program,则默认执行$SHELL。
使用nsenter进入某个进程的某一类namespace之后,就能使用主机上的工具操作该进程在该namespace下的资源,比如进入net namespace之后,可以使用tcpdump对容器内部网卡进行流量监控。
2.2 UTS namespace
UTS namespace可以让各个容器拥有独立的主机名和域名,可以在docker内网以名字形式被稳定的发现
#容器内的hostname
[root@iZukkkkf6gqdhf0dbbht8rtbmbZ ~]# docker exec -it e5f276b4ffe1 bash
root@fluentd-s3-t69tt:/home/fluent# hostname
fluentd-s3-t69tt
root@fluentd-s3-t69tt:/home/fluent# cat /etc/hostname
fluentd-s3-t69tt
root@fluentd-s3-t69tt:/home/fluent# exit
exit
#主机的hostname
[root@iZukkkkf6gqdhf0dbbht8rtbmbZ ~]# hostname
iZukkkkf6gqdhf0dbbht8rtbmbZ
可以看到容器e5f276b4ffe1拥有独立的/etc/hostname
2.3 User namespace
这个namespace可以在容器内部定义root用户,但是映射到主机层面却是一般的用户,进一步完善容器内进程的权限体验。
User namespace在老的CentOS版本中是体验功能,需要修改kernel启动参数进行激活,在本文的测试环境“CentOS Linux release 7.5.1804 (Core) ”中是默认激活的,但是还是需要进行一些系统配置。
参考文档:《Isolate containers with a user namespace》
- 修改max_user_namespaces
在系统默认的情况下,max_user_namespaces的值是0:
ls /proc/sys/user/max_* -l
-rw-r--r-- 1 root root 0 8月 14 10:33 /proc/sys/user/max_ipc_namespaces
-rw-r--r-- 1 root root 0 8月 14 10:33 /proc/sys/user/max_mnt_namespaces
-rw-r--r-- 1 root root 0 8月 14 10:33 /proc/sys/user/max_net_namespaces
-rw-r--r-- 1 root root 0 8月 14 10:33 /proc/sys/user/max_pid_namespaces
-rw-r--r-- 1 root root 0 8月 13 18:16 /proc/sys/user/max_user_namespaces
-rw-r--r-- 1 root root 0 8月 14 10:33 /proc/sys/user/max_uts_namespaces
cat /proc/sys/user/max_*
63370
63370
63370
63370
0
63370
需要通过如下方式修改:
echo "user.max_user_namespaces = 2147483647" > /etc/sysctl.conf 然后重启机器,并确认:
cat /proc/sys/user/max_user_namespaces
2147483647
- 增加一个可以访问docker daemon运行docker命令的用户
useradd dockerowner
groupadd docker
gpasswd -a dockerowner docker- 将用户dockerowner作为启动docker容器的非root宿主机用户
在文件/etc/sysconfig/docker加入:
OPTIONS=' --userns-remap=dockerowner'
echo "dockerowner:231000:65536" > /etc/subgid
echo "dockerowner:231000:65536" > /etc/subuid
service docker restart- 切换到dockerowner用户并启动容器
su -l dockerowner
docker run -it centos bash
[root@910322a27d8d /]# id
uid=0(root) gid=0(root) groups=0(root)可以看到在容器内部ID是0,但是这个ID事实上是无法操作从外部映射进来的系统目录的,因为这个ID对应的外部宿主机用户是dockerowner,只是一个普通用户:
id dockerowner
uid=1001(dockerowner) gid=1001(dockerowner) 组=1001(dockerowner),1002(docker)察看该容器对应的uid map和对应的目录权限:
docker inspect 910322a27d8d | grep Pid
"Pid": 2053,
cat /proc/2053/uid_map
0 231000 65536
ls /var/lib/docker/231000.231000/
containers image network overlay2 plugins swarm tmp trust volumesuid_map里面的信息表明容器内的ID 0是由宿主机的ID 231000映射过来的
2.4 PID namespace
通过PID namespace可以让容器内进程拥有与宿主机隔离的PID tree,借助于namespace,一个容器内的进程拥有两个PID,分别对应容器内和宿主机上的namespace。
启动一个容器并查看内部进程列表:
[root@k8s-master-03 ~]# docker run -it 172.2.2.11:5000/centos bash
[root@6f9142729858 /]# ps -efl
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 1 0 0 80 0 - 3002 do_wai 05:51 ? 00:00:00 bash
0 R root 17 1 0 80 0 - 11146 - 05:54 ? 00:00:00 ps -efl
可以看到bash成为了容器内部的1号进程,而该进程对应的外部PID如下:
docker inspect 6f9142729858| grep Pid" -i
"Pid": 20699,
#容器内部shell对应宿主机PID
[root@k8s-master-03 ~]# ps -ef | grep 20699
231072 20699 20682 0 05:51 pts/0 00:00:00 bash
root 20908 19571 0 05:57 pts/1 00:00:00 grep --color=auto 20699
#容器shim PID
[root@k8s-master-03 ~]# ps -ef | grep 20682
root 20682 4613 0 05:51 ? 00:00:00 /usr/bin/docker-containerd-shim-current 6f91427298585a4724ee359fc1152e148738d24c4d8bdf11529ade99981fcb36 /var/run/docker.231072.231072/libcontainerd.231072.231072/6f91427298585a4724ee359fc1152e148738d24c4d8bdf11529ade99981fcb36 /usr/libexec/docker/docker-runc-current
231072 20699 20682 0 05:51 pts/0 00:00:00 bash
root 20910 19571 0 05:57 pts/1 00:00:00 grep --color=auto 20682
#containerd PID
[root@k8s-master-03 ~]# ps -ef | grep 4613
root 4613 4602 0 8月13 ? 00:00:54 /usr/bin/docker-containerd-current -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --metrics-interval=0 --start-timeout 2m --state-dir /var/run/docker/libcontainerd/containerd --shim docker-containerd-shim --runtime docker-runc --runtime-args --systemd-cgroup=true
root 20682 4613 0 05:51 ? 00:00:00 /usr/bin/docker-containerd-shim-current 6f91427298585a4724ee359fc1152e148738d24c4d8bdf11529ade99981fcb36 /var/run/docker.231072.231072/libcontainerd.231072.231072/6f91427298585a4724ee359fc1152e148738d24c4d8bdf11529ade99981fcb36 /usr/libexec/docker/docker-runc-current
root 20913 19571 0 05:58 pts/1 00:00:00 grep --color=auto 4613
#Docker daemon PID
[root@k8s-master-03 ~]# ps -ef | grep 4602
root 4602 1 0 8月13 ? 00:01:35 /usr/bin/dockerd-current --add-runtime docker-runc=/usr/libexec/docker/docker-runc-current --default-runtime=docker-runc --exec-opt native.cgroupdriver=systemd --userland-proxy-path=/usr/libexec/docker/docker-proxy-current --init-path=/usr/libexec/docker/docker-init-current --seccomp-profile=/etc/docker/seccomp.json --selinux-enabled --log-driver=journald --signature-verification=false --userns-remap=dockerowner --storage-driver overlay2
root 4613 4602 0 8月13 ? 00:00:54 /usr/bin/docker-containerd-current -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --metrics-interval=0 --start-timeout 2m --state-dir /var/run/docker/libcontainerd/containerd --shim docker-containerd-shim --runtime docker-runc --runtime-args --systemd-cgroup=true
root 20916 19571 0 05:58 pts/1 00:00:00 grep --color=auto 4602
容器里面PID 1的bash进程对应的是宿主机上的PID进程20699:

在这里简要说明一下容器的启动流程:
- Docker Engine(PID 4602)准备镜像,并调用containerd进程进行容器启动工作
- containerd(PID 4613)进程启动containerd-shim(PID 20682)
- containerd-shim启动runc
- runc启动容器(PID 20699)
- runc马上exit
- containerd-shim变成容器里面进程的parent
2.5 network namespace
network namespace为容器创建了独立的网络协议栈、端口、IP等环境:
[root@6f9142729858 /]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
45: eth0@if46: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe11:2/64 scope link
valid_lft forever preferred_lft forever
可以通过nsenter查看容器进程对应的network ns的信息:
[root@k8s-master-03 netns]# nsenter -n -t 20699
[root@k8s-master-03 netns]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
45: eth0@if46: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe11:2/64 scope link
valid_lft forever preferred_lft forever
nsenter进入该namespace之后还可以使用主机上的所有网络工具比如netstat、tcpdump等:
[root@k8s-master-03 netns]# netstat -anp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 1 1 172.17.0.2:42782 18.225.36.18:80 LAST_ACK -
tcp 1 1 172.17.0.2:52526 202.202.1.140:80 LAST_ACK -
tcp 1 1 172.17.0.2:36476 162.243.159.138:80 LAST_ACK -
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node PID/Program name Path
(SIOCGIFHWADDR: No such device)
[root@k8s-master-03 netns]# tcpdump -i eth0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
三、cgroup的实践
3.1 查看系统是否支持cgroup技术
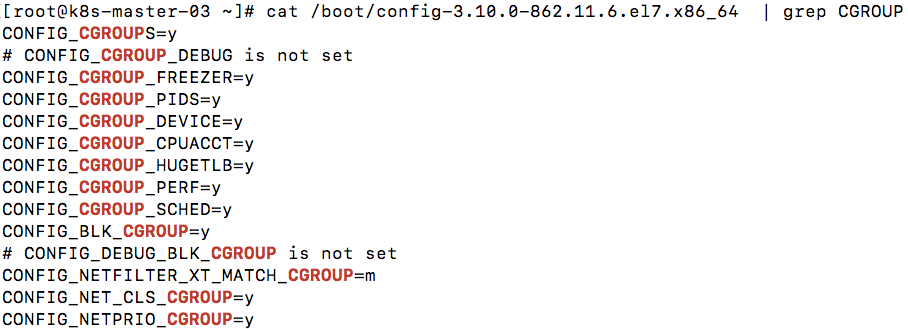
查看cgroups支持的subsystem:
lssubsys -am
cpuset /sys/fs/cgroup/cpuset
cpu,cpuacct /sys/fs/cgroup/cpu,cpuacct
memory /sys/fs/cgroup/memory
devices /sys/fs/cgroup/devices
freezer /sys/fs/cgroup/freezer
net_cls,net_prio /sys/fs/cgroup/net_cls,net_prio
blkio /sys/fs/cgroup/blkio
perf_event /sys/fs/cgroup/perf_event
hugetlb /sys/fs/cgroup/hugetlb
pids /sys/fs/cgroup/pids
cgroups支持的命令有:
yum install libcgroup libcgroup-tools
cgclassify cgclear cgconfigparser cgcreate cgdelete cgexec cgget cgrulesengd cgset cgsnapshot
3.2 查看cgroup在文件系统的展示
mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
3.3 docker使用cgroups进行资源限制
docker run -it -m 512m --cpu-period=100000 --cpu-quota=50000 centos bash
运行之后在容器内可以看到独立的cgroups配置:
内存限制:
[root@56a4ce0723b9 /]# cat /sys/fs/cgroup/memory/memory.limit_in_bytes
536870912
CPU限制:
[root@56a4ce0723b9 /]# ls /sys/fs/cgroup/
blkio cpu cpuacct cpuacct,cpu cpuset devices freezer hugetlb memory net_cls net_prio net_prio,net_cls perf_event pids systemd
[root@56a4ce0723b9 /]# cat /sys/fs/cgroup/cpu/tasks
1
17
[root@56a4ce0723b9 /]# cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
50000
[root@56a4ce0723b9 /]# cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
100000
这两个限制对应的宿主机的系统目录:
ls /sys/fs/cgroup/cpu,cpuacct/system.slice/docker-56a4ce0723b9140c9add2a03177aca6389338e22b65ee331bed1fbb92ad66f55.scope/
cgroup.clone_children cgroup.procs cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.event_control cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
/sys/fs/cgroup/memory/system.slice/docker-56a4ce0723b9140c9add2a03177aca6389338e22b65ee331bed1fbb92ad66f55.scope/
cgroup.clone_children memory.kmem.limit_in_bytes memory.kmem.tcp.usage_in_bytes memory.memsw.max_usage_in_bytes memory.soft_limit_in_bytes tasks
cgroup.event_control memory.kmem.max_usage_in_bytes memory.kmem.usage_in_bytes memory.memsw.usage_in_bytes memory.stat
cgroup.procs memory.kmem.slabinfo memory.limit_in_bytes memory.move_charge_at_immigrate memory.swappiness
memory.failcnt memory.kmem.tcp.failcnt memory.max_usage_in_bytes memory.numa_stat memory.usage_in_bytes
memory.force_empty memory.kmem.tcp.limit_in_bytes memory.memsw.failcnt memory.oom_control memory.use_hierarchy
memory.kmem.failcnt memory.kmem.tcp.max_usage_in_bytes memory.memsw.limit_in_bytes memory.pressure_level notify_on_release
3.4 使用宿主机系统命令查看cgroups
[root@k8s-master-03 ~]# systemd-cgls
├─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 21
├─user.slice
│ └─user-0.slice
│ ├─session-30.scope
│ │ ├─23107 sshd: root@pts/3
│ │ ├─23109 -bash
│ │ ├─24360 systemd-cgls
│ │ └─24363 less
│ └─session-29.scope
│ ├─23028 sshd: root@pts/1
│ ├─23030 -bash
│ └─23989 /usr/bin/docker-current run -it -m 512m --cpu-period=100000 --cpu-quota=50000 172.2.2.11:5000/centos bash
└─system.slice
├─docker-56a4ce0723b9140c9add2a03177aca6389338e22b65ee331bed1fbb92ad66f55.scope
│ └─24023 bash
├─docker.service
│ ├─ 4602 /usr/bin/dockerd-current --add-runtime docker-runc=/usr/libexec/docker/docker-runc-current --default-runtime=docker-runc --exec-opt native.cgroupdriver=systemd --userlan
│ ├─ 4613 /usr/bin/docker-containerd-current -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --metrics-interval=0 --start-timeout 2m --state-dir /var/run/docker/lib
│ └─24006 /usr/bin/docker-containerd-shim-current 56a4ce0723b9140c9add2a03177aca6389338e22b65ee331bed1fbb92ad66f55 /var/run/docker.231072.231072/libcontainerd.231072.231072/56a4ce
├─crond.service通过systemd-cgtop 可以查看各个cgroups的资源使用情况:
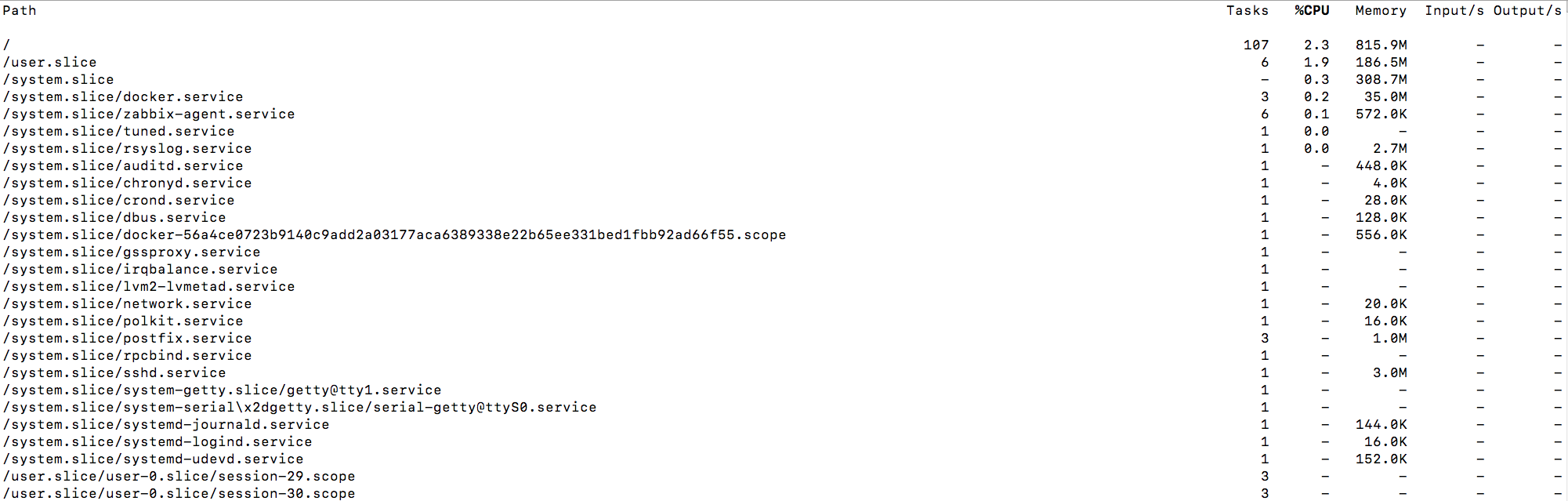
其实cgroups除了支持CPU和内存资源,还支持block IO、网络以及一些系统设备device的资源使用限制,docker run命令支持的cgroups功能有:
| Option | Description |
|---|---|
-m, --memory="" | Memory limit (format: <number>[<unit>]). Number is a positive integer. Unit can be one of b, k, m, or g. Minimum is 4M. |
--memory-swap="" | Total memory limit (memory + swap, format: <number>[<unit>]). Number is a positive integer. Unit can be one of b, k, m, or g. |
--memory-reservation="" | Memory soft limit (format: <number>[<unit>]). Number is a positive integer. Unit can be one of b, k, m, or g. |
--kernel-memory="" | Kernel memory limit (format: <number>[<unit>]). Number is a positive integer. Unit can be one of b, k, m, or g. Minimum is 4M. |
-c, --cpu-shares=0 | CPU shares (relative weight) |
--cpus=0.000 | Number of CPUs. Number is a fractional number. 0.000 means no limit. |
--cpu-period=0 | Limit the CPU CFS (Completely Fair Scheduler) period |
--cpuset-cpus="" | CPUs in which to allow execution (0-3, 0,1) |
--cpuset-mems="" | Memory nodes (MEMs) in which to allow execution (0-3, 0,1). Only effective on NUMA systems. |
--cpu-quota=0 | Limit the CPU CFS (Completely Fair Scheduler) quota |
--cpu-rt-period=0 | Limit the CPU real-time period. In microseconds. Requires parent cgroups be set and cannot be higher than parent. Also check rtprio ulimits. |
--cpu-rt-runtime=0 | Limit the CPU real-time runtime. In microseconds. Requires parent cgroups be set and cannot be higher than parent. Also check rtprio ulimits. |
--blkio-weight=0 | Block IO weight (relative weight) accepts a weight value between 10 and 1000. |
--blkio-weight-device="" | Block IO weight (relative device weight, format: DEVICE_NAME:WEIGHT) |
--device-read-bps="" | Limit read rate from a device (format: <device-path>:<number>[<unit>]). Number is a positive integer. Unit can be one of kb, mb, or gb. |
--device-write-bps="" | Limit write rate to a device (format: <device-path>:<number>[<unit>]). Number is a positive integer. Unit can be one of kb, mb, or gb. |
--device-read-iops="" | Limit read rate (IO per second) from a device (format: <device-path>:<number>). Number is a positive integer. |
--device-write-iops="" | Limit write rate (IO per second) to a device (format: <device-path>:<number>). Number is a positive integer. |
--oom-kill-disable=false | Whether to disable OOM Killer for the container or not. |
--oom-score-adj=0 | Tune container’s OOM preferences (-1000 to 1000) |
--memory-swappiness="" | Tune a container’s memory swappiness behavior. Accepts an integer between 0 and 100. |
--shm-size="" | Size of /dev/shm. The format is <number><unit>. number must be greater than 0. Unit is optional and can be b (bytes), k (kilobytes), m (megabytes), or g (gigabytes). If you omit the unit, the system uses bytes. If you omit the size entirely, the system uses 64m. |
转载自https://blog.csdn.net/cloudvtech
四、UnionFS(Overlayfs2)的实践
4.1 验证docker的文件系统情况
测试系统的docker使用的存储驱动是overlayfs2:
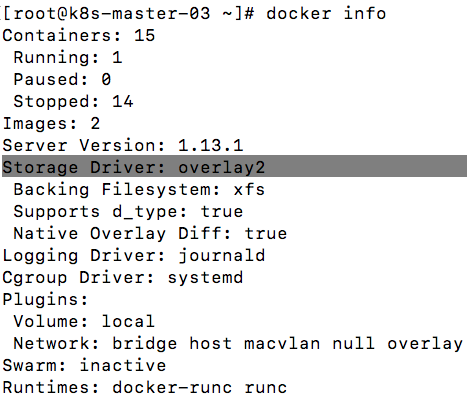
通过docker inspect命令,可以看到容器启动之后依赖的GraphDriver是overlayfs2:
"GraphDriver": {
"Name": "overlay2",
"Data": {
"LowerDir": "/var/lib/docker/231072.231072/overlay2/b6fc62363c5f880e3df7a24a6bac28aaf386521fcbd062e09ef33a7807134fcc-init/diff:/var/lib/docker/231072.231072/overlay2/d1ec1e71dd83de4b13c4e532cff27202be0c2713830830a9767ef3b35448d034/diff",
"MergedDir": "/var/lib/docker/231072.231072/overlay2/b6fc62363c5f880e3df7a24a6bac28aaf386521fcbd062e09ef33a7807134fcc/merged",
"UpperDir": "/var/lib/docker/231072.231072/overlay2/b6fc62363c5f880e3df7a24a6bac28aaf386521fcbd062e09ef33a7807134fcc/diff",
"WorkDir": "/var/lib/docker/231072.231072/overlay2/b6fc62363c5f880e3df7a24a6bac28aaf386521fcbd062e09ef33a7807134fcc/work"
}
},
对应的目录下情况:
ls /var/lib/docker/231072.231072/overlay2/b6fc62363c5f880e3df7a24a6bac28aaf386521fcbd062e09ef33a7807134fcc -l
总用量 8
drwxr-xr-x 3 231072 231072 17 8月 14 09:17 diff
-rw-r--r-- 1 root root 26 8月 14 09:17 link
-rw-r--r-- 1 root root 57 8月 14 09:17 lower
drwxr-xr-x 1 231072 231072 17 8月 14 09:17 merged
drwx------ 3 231072 231072 18 8月 14 09:17 work
如果在容器里面加入一个文件,看到的变化如下:
[root@56a4ce0723b9 /]# touch mytest
#在宿主机运行
[root@k8s-master-03]ls /var/lib/docker/231072.231072/overlay2/b6fc62363c5f880e3df7a24a6bac28aaf386521fcbd062e09ef33a7807134fcc/diff/
mytest run
4.2 docker文件不同类型系统的分析
Docker最早使用的是AUFS, 但是它不再mainline kernel里面,所以使用的适合要打patch,之后Redhat开发了Device Mapper driver,后面又出现了BTRFS以及overlayfs。
- AUFS,会将多个目录(每个目录叫做branch)组织在一起,目录里面至少有一个只读,最多有一个可读可写,但是在进行可写open的时候,需要进行全量copy,所以大文件打开特别慢;使用whiteout文件来标识被删除的文件;AUFS在创建容器的时候可以快速mount,读写是主机原生速度,但是在写打开大文件或者查找多层级多目录的mount的时候会很慢
- DeviceMapper,这个系统可以组非常复杂的包括RAID、加密设备、快照等工作,docker使用的是DeviceMapper的基本block IO功能外加thin provisioning功能,不同于AUFS的CoW是发生在文件级别,DeviceMapper的CoW是发生在磁盘block层面,每个容器都有自己独立的block设备,所以借助DeviceMapper可以随时进行镜像快照;最好将数据和metadata存储在真是的物理设备,而不是虚拟文件设备
- overlayfs,类似于AUFS,单overlayfs只有两个branch(layer),每个layer也可以是overlay,宿主机上文件布局如上文所示(lower-id/merged/upper/work);overlayfs是正式进入kernel tree;由于overlayfs的层级少,它的速度要比AUFS更快
如果要部署高资源密度的PaaS平台,使用AUFS或者overlayfs(阿里云托管的Kubernetes服务使用的就是overlayfs2),如果要读写大文件,使用BTRFS或者DeviceMapper,但是最终还是要根据自己的业务场景去测试和选择。
转载自https://blog.csdn.net/cloudvtech
最后
以上就是瘦瘦红酒最近收集整理的关于Kubernetes生产实践系列之二十九:Kubernetes基础技术之容器关键技术实践的全部内容,更多相关Kubernetes生产实践系列之二十九内容请搜索靠谱客的其他文章。






![[linux语法手册中文版]-IPC_NAMESPACES(7)](https://www.shuijiaxian.com/files_image/reation/bcimg8.png)

发表评论 取消回复