一、背景知识 —— aarch64的函数栈
1. 栈生长方向与push/pop操作
栈是一种运算受限的线性表, 入栈的一端为栈顶,另一端则为栈底, 其生长方向和操作顺序理论上没有限定. 而在aarch64平台上:
- 栈是向低地址方向增长的(STACK_GROWS_DOWNWARD)
- 栈的PUSH/POP通常要先移动SP:
- PUSH操作为PRE_DEC,即 PUSH操作为 sp = sp -4; store;
- POP操作为 POST_INC,即POP操作为 read; sp=sp+4;
2. 返回地址的存储
x86平台是call指令时自动push函数返回地址到栈; ret指令自动pop函数返回地址出栈; 这两步操作都是在callee执行前硬件自动完成的.
而在arm/aarch64平台发生函数调用时(blx),硬件负责将函数的返回地址设置到通用寄存器LR(/X30)中, callee中的代码负责将LR保存到栈中(需保存的寄存器参考AAPCS标准)
3. 函数栈分配
在不考虑动态分配的情况下, 函数中使用的栈大小在编译阶段就已经确定了(见备注1), 一个aarch64中的典型的程序栈如下所示:
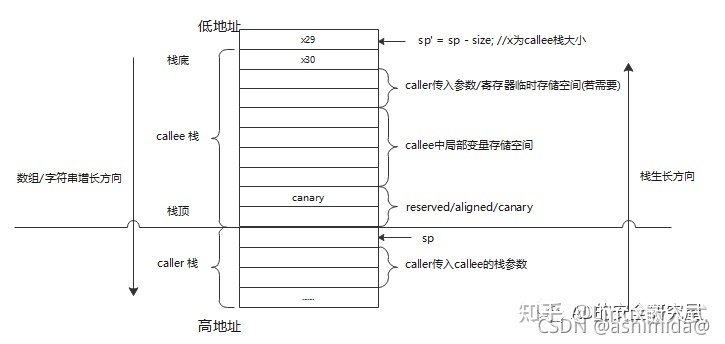
和x86/arm平台的不同在于:
- x86和arm平台的函数返回地址通常都存于callee栈的栈顶(或者说caller栈的栈底):
- x86平台是硬件完成的push/pop操作,故返回地址先入栈
- arm平台callee函数的首指令通常是先push通用寄存器, 函数返回前最后语句pop通用寄存器如:
000005fc <test>:
5fc: b590 push {r4, r7, lr} /* 先push通用寄存器和函数返回地址 */
5fe: b089 sub sp, #36 ; 0x24 /* 再为局部变量预留存储空间 */
600: af00 add r7, sp, #0
602: 6078 str r0, [r7, #4]
......
634: 3724 adds r7, #36 ; 0x24
636: 46bd mov sp, r7
638: bd90 pop {r4, r7, pc}
在此两个平台中若发生了栈溢出则直接可以覆盖到当前函数的返回地址.
- 而aarch64通常是先预留栈再保存函数返回地址,如:
0000000000400654 <test>:
/* 预留栈 || 在栈底保存函数返回地址 */
400654: a9bc7bfd stp x29, x30, [sp, #-64]! /* sp = sp - 64; sp[0] = x29; sp[1] = x30; */
400658: 910003fd mov x29, sp
40065c: b9001fe0 str w0, [sp, #28]
400660: b9801fe1 ldrsw x1, [sp, #28]
......
400680: a8c47bfd ldp x29, x30, [sp], #64 /* x29 = sp[0]; x30 = sp[1]; sp = sp +64; */
400684: d65f03c0 ret
最终的函数栈如上图所示, 由于变量是向高地址方向生长的,故:
- 在x86/arm平台的栈上溢(向高地址溢出)通常可直接修改当前函数(这里的callee)的返回地址
- 在aarch64平台的栈上溢(向高地址溢出)则通常只能修改到父函数(caller)的返回地址
二、stack canary简介
stack canary是一个比较久远的安全特性,linux内核在2.6版本便已经引入, 在5.0又引入了增强的per-task stack canar, 其原理比较简单,即:
1. 每个函数执行前先向栈帧顶部插入一个canary值(如下图)以确保顺序的栈上溢在破坏到父函数栈帧前必须要先破坏canary
2. 每个函数返回时检测当前栈帧中的canary是否被修改,若被修改则代表发生了溢出(报错)
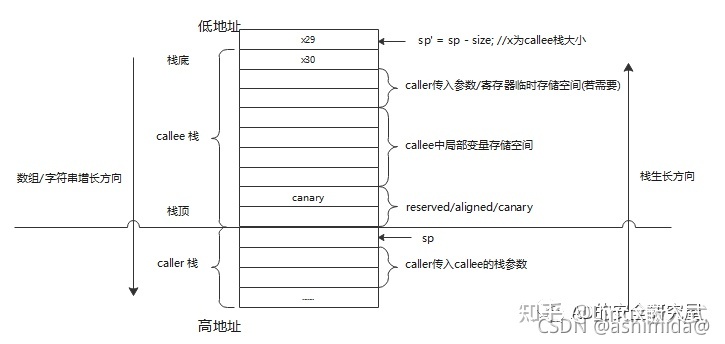
stack canary并不能检测到所有的栈溢出问题, 只有在满足:
- 攻击者不知当前插入当函数栈中canary的值(无infoleak)
- 攻击者只能顺序的覆盖栈中数据,无法跳过canary覆盖数据
两个前提条件时才能检测到栈溢出,故其并非一种理论上安全的防御方式,也只能针对顺序覆盖的栈溢出提供一定的缓解.
三、stack canary基本思路与业界实现
虽然原理简单,但实现上还是要解决两个主要问题:
1. 作为对比基准的canary来自哪里?
函数入口需要向函数栈push一个原始的canary,函数出口需要将函数栈中的canary(后续称为stack_canary)和原始值做对比,在此过程中原始值需要保持不变并且可以被代码获取到:
1.1 原始值来自全局变量
默认stack canary使用全局符号(变量) __stack_chk_guard 作为原始的canary(后续称为全局canary), 在gcc/clang中均使用相同的名字.
* 全局canary的优点在于:
- 实现简单,开启stack_canary保护的代码中只需要定义一个全局变量__stack_chk_guard 并在初始化时为其赋值一个随机数即可
* 全局canary的缺点在于:
- 所有进程间共享同一个全局canary,只要某进程/线程中发生了infoleak,那么整个canary机制就可以被绕过了.
- 全局canary(__stack_chk_guard)的值在运行期间难以改变,否则会导致已有的函数返回时直接crash
1.2 原始值来自per-cpu变量
per-cpu 变量的引入是为了实现per-task的stack canary, 每个cpu上同时只能运行一个进程/线程, per cpu变量可以随进程的切换而切换,故通过一个per-cpu变量完全可以为每个进程/线程解引用到不同的canary地址(后续称为per-cpu canary),以实现per-task的canary.
* per-cpu canary的优点在于:
- 每个进程/线程拥有自己的canary, 可减少infoleak的影响
* per-cpu canary的缺点在于:
- 需要依赖于硬件平台的一个per-cpu变量(如aarch64 用户态tpidr_el0,内核态sp_el0)
- 需要编译器增加对应支持
2. 每个函数中push/pop/check canary的代码谁来写?
通常stack canary的桩代码都是由编译器来插入的,但对具体硬件平台, 不同编译器的支持也有所不同
2.1 gcc/llvm 均支持全局canary:
gcc/llvm中编译选项-fstack-protector/-fstack-protector-strong均已支持, 开启后函数出入口会从全局变量__stack_chk_guard中获取全局canary
2.2 gcc/llvm 均支持aarch64的per-cpu canary:
- gcc通过-mstack-protector-guard*系列选项可以指定某系统寄存器作为stack canary per cpu的资源(后面称为sysreg)
- clang 主线目前也已支持-mstack-protector-guard* 系列选项,但目前尚无可用发行版[1]
- clang --target=--target=aarch64-linux-android 中支持per cpu的stack canary,但其只能使用默认的 tpidr_el0系统寄存器作为索引, 偏移值也是默认的0x40
-mstack-protector-guard*系列包含三个选项:
* -mstack-protector-guard=sysreg: 使用系统寄存器作为per cpu canary的索引
* -mstack-protector-guard-reg=sp_el0: 作为索引的系统寄存器名(必须是系统寄存器,代码中最终会生成msr/mrs作为访问指令)
* -mstack-protector-guard-offset=16: 偏移地址,最终canary来自 *(sp_el0 + offset)
2.3 arm linux内核可通过gcc plugin支持 per-cpu canary:
arm linux kernel 通过一个gcc plugin(arm_ssp_per_task_plugin)基于per-cpu 寄存器sp实现了 per-task canary功能
四、编译器中全局canary的实现
这里以aarch64平台,gcc + -fstack-protector-strong为例,其实现逻辑如下(源码分析见备注2):
- 函数入口将全局canary => stack_canary(stack_canary地址为编译期间预留在当前函数栈顶的)
- 函数出口对比全局canary和stack_canary是否还一致,一致则跳转到4)
- 检测到栈溢出, 调用__stack_chk_fail函数
- 函数返回
在aarch64的汇编代码如下:
//aarch64-linux-gnu-gcc -g -fstack-protector-strong test.c -S -o ./gcc/test.s
1 test:
2 stp x29, x30, [sp, -64]! /* 分配函数栈帧 */
3 mov x29, sp
4 str w0, [sp, 28]
5 adrp x0, __stack_chk_guard /* 获取全局canary *__stack_chk_guard */
6 add x0, x0, :lo12:__stack_chk_guard
7 ldr x1, [x0]
8 str x1, [sp, 56] /* 全局canary => stack_canary(位于栈顶) */
9 ....... /* 函数体 */
10 adrp x0, __stack_chk_guard /* 函数返回前再次获取全局canary */
11 add x0, x0, :lo12:__stack_chk_guard
12 ldr x0, [x0]
13 ldr x2, [sp, 56] /* 读取stack_canary */
14 eor x0, x2, x0 /* 对比stack_canary是否被破坏 */
15 cmp x0, 0
16 beq .L3 /* 未破坏跳转到函数返回 */
17 bl __stack_chk_fail /* 被破坏则跳转到 __stack_chk_fail */
18
19 .L3:
20 ldp x29, x30, [sp], 64
21 ret
五、编译器中per-cpu canary的实现
per-cpu canary时编译器会通过 *(reg + offset)的方式获取当前cpu上的canary(如下面例子中的 * (sp_el0 + 16), 而程序自身需要确保线程切换时per-cpu的canary也要随之切换, 在aarch64下的汇编代码如下(源码分析见备注2):
/*
-mstack-protector-guard=sysreg: 使用系统寄存器作为per cpu canary的索引
-mstack-protector-guard-reg=sp_el0: 作为索引的系统寄存器名(必须是系统寄存器,代码中最终会生成msr/mrs作为访问指令)
-mstack-protector-guard-offset=16: 偏移地址,最终canary来自 *(sp_el0 + offset)
*/
//aarch64-linux-gnu-gcc -g -fstack-protector-strong -mstack-protector-guard=sysreg -mstack-protector-guard-reg=sp_el0 -mstack-protector-guard-offset=16 test.c -S -o ./gcc/test.s
1 test:
2 stp x29, x30, [sp, -64]! /* 分配函数栈帧 */
3 mov x29, sp
4 str w0, [sp, 28]
5 mrs x0, sp_el0 /* x1 = *(sp_el0 + 16); 为per cpu canary值 */
6 add x0, x0, 16
7 ldr x1, [x0]
8 str x1, [sp, 56] /* per cpu canary => stack_canary */
9 ......
10 mrs x0, sp_el0 /* 再次获取per cpu的canary */
11 add x0, x0, 16
12 ldr x0, [x0]
13 ldr x1, [sp, 56] /* 再次获取stack_canary */
14 eor x0, x1, x0 /* 对比匹配则正常结束,不匹配跳转到__stack_chk_fail */
15 cmp x0, 0
16 beq .L2
17 bl __stack_chk_fail
18 .L2:
19 ldp x29, x30, [sp], 64
20 ret
六、linux内核对stack canary的支持
linux内核中与stack canary相关的配置项主要有三个,分别是:
1) CONFIG_STACKPROTECTOR:
平台无关的编译选项,其决定是否开启 stack canary保护, 开启则默认指定编译选项 -fstack-protector,使用__stack_chk_guard 作为全局canary对比
2) CONFIG_STACKPROTECTOR_STRONG
平台无关的编译选项,其决定是否开启strong保护,开启则额外指定编译选项 -fstack-protector-strong.
3) CONFIG_STACKPROTECTOR_PER_TASK
平台相关的编译选项, 其决定是否开启内核per-task的stack canary保护(此时需编译器的per-cpu canary和对应硬件平台支持)
七、aarch64平台内核stack canary的实现
1. 全局canary的实现
CONFIG_STACKPROTECTOR =y
CONFIG_STACKPROTECTOR_STRONG =y
CONFIG_STACKPROTECTOR_PER_TASK=n
全局canary对于内核来说并没有太多的工作,只需要在系统启动时设置好__stack_chk_guard并定义检测失败的回调__stack_chk_fail 即可,插桩代码均由编译器实现(见四), 代码如下:
./arch/arm64/kernel/process.c
#if defined(CONFIG_STACKPROTECTOR) && !defined(CONFIG_STACKPROTECTOR_PER_TASK)
#include <linux/stackprotector.h>
/* 这里__stack_chk_guard被定义为一个变量, 实际上定义为__ro_after_init可能更好, 此变量可写通常也不会有太大问题,因为对此变量的修改通常会直接导致内核检测到栈溢出而crash */
unsigned long __stack_chk_guard __read_mostly;
EXPORT_SYMBOL(__stack_chk_guard);
#endif
./arch/arm64/include/asm/stackprotector.h
static __always_inline void boot_init_stack_canary(void)
{
#if defined(CONFIG_STACKPROTECTOR)
unsigned long canary;
get_random_bytes(&canary, sizeof(canary)); /* 获取一个半随机数 */
canary ^= LINUX_VERSION_CODE;
canary &= CANARY_MASK;
current->stack_canary = canary;
if (!IS_ENABLED(CONFIG_STACKPROTECTOR_PER_TASK))
__stack_chk_guard = current->stack_canary; /* 如果没指定 per thread,则初始化全局canary */
#endif
.......
}
./kernel/panic.c
__visible noinstr void __stack_chk_fail(void)
{
instrumentation_begin();
panic("stack-protector: Kernel stack is corrupted in: %pB",
__builtin_return_address(0));
instrumentation_end();
}
EXPORT_SYMBOL(__stack_chk_fail);
2. per-task canary的实现
CONFIG_STACKPROTECTOR =y
CONFIG_STACKPROTECTOR_STRONG =y
CONFIG_STACKPROTECTOR_PER_TASK=y
per-task canary时内核除了初始化外还需要负责为每个进程生成随机的canary,并负责在进程切换时同步per-cpu的寄存器与进程的关系,此时内核新增的配置项和数据结构如下:
./arch/arm64/kernel/asm-offsets.c
#ifdef CONFIG_STACKPROTECTOR
DEFINE(TSK_STACK_CANARY, offsetof(struct task_struct, stack_canary)); /* task_struct中增加per thread的canary */
#endif
./arch/arm64/Kconfig
config STACKPROTECTOR_PER_TASK
def_bool y
depends on STACKPROTECTOR && CC_HAVE_STACKPROTECTOR_SYSREG
./arch/arm64/Makefile
ifeq ($(CONFIG_STACKPROTECTOR_PER_TASK),y)
prepare: stack_protector_prepare
/* 增加编译选项 -mstack-protector-guard=sysreg -mstack-protector-guard-reg=sp_el0 -mstack-protector-guard-offset=TSK_STACK_CANARY*/
stack_protector_prepare: prepare0
$(eval KBUILD_CFLAGS += -mstack-protector-guard=sysreg ## per-task编译选项支持
-mstack-protector-guard-reg=sp_el0
-mstack-protector-guard-offset=$(shell
awk '{if ($$2 == "TSK_STACK_CANARY") print $$3;}'
include/generated/asm-offsets.h))
endif
根据编译选项可知,per-task模式下内核指定编译器通过 *(sp_el0 + TSK_STACK_CANARY) 来解引用per-cpu canary, sp_el0在内核中用来存储当前进程task_struct的指针,即对于内核来说对 *(sp_el0 + TSK_STACK_CANARY) 的解引用即相当于访问 current->stack_canary.
由于sp_el0在内核中是随着进程切换而切换的(见__switch_to),故stack canary特性并不需要做额外的操作,其只需要在每个线程创建时为其生成新的canary即可:
static struct task_struct *dup_task_struct(struct task_struct *orig, int node)
{
......
#ifdef CONFIG_STACKPROTECTOR /* 这里不是CONFIG_STACKPROTECTOR_PER_TASK是因为x86平台此特性兼容的历史原因,这里欠缺一点优雅 */
tsk->stack_canary = get_random_canary(); /* fork线程时总是新生成一个随机数作为新线程的canary */
#endif
......
}
故在aarch64内核中 per-task canary的思路可整理如下:
- 内核自身sp_el0记录task_struct(即current)地址,并随进程切换而切换
- 在task_struct中增加一个成员stack_canary, 则此成员总是可以通过 (sp_el0 + TSK_STACK_CANARY)找到
- 进程创建时总是为其生成一个新的canary记录到 current->stack_canary
- 编译器开启per-cpu canary支持,基准的canary值总是来自sp_el0 + TSK_STACK_CANARY,也就是 current->stack_canary
八、ARM平台内核stack canary的实现
ARM平台全局canary的实现和aarch64基本相同,都是基于变量"__stack_chk_guard"完成的,但由于在arm平台gcc并不支持-mstack-protector-guard系列选项,故ARM平台的per cpu canary是通过gcc plugin完成的, 在arm平台:
- sp 栈顶总是存放当前进程的thread_info, 故可以编译器通过 sp+offset的方式来解引用per-cpu的canary
- 内核本身会维护sp与当前进程关系,在thread_info中添加stack_canary成员即可被编译器插装代码解引用
./arch/arm/kernel/asm-offsets.c
#ifdef CONFIG_STACKPROTECTOR_PER_TASK
DEFINE(TI_STACK_CANARY, offsetof(struct thread_info, stack_canary));
#endif
DEFINE(THREAD_SZ_ORDER, THREAD_SIZE_ORDER);
./scripts/Makefile.gcc-plugins
gcc-plugin-$(CONFIG_GCC_PLUGIN_ARM_SSP_PER_TASK) += arm_ssp_per_task_plugin.so
ifdef CONFIG_GCC_PLUGIN_ARM_SSP_PER_TASK
DISABLE_ARM_SSP_PER_TASK_PLUGIN += -fplugin-arg-arm_ssp_per_task_plugin-disable
endif
./arch/arm/Makefile
stack_protector_prepare: prepare0
$(eval SSP_PLUGIN_CFLAGS :=
-fplugin-arg-arm_ssp_per_task_plugin-tso=$(shell ## awk asm-offsets.h文件,输出THREAD_SZ_ORDER 对应的 THREAD_SIZE_ORDER,也就是 1或2,代表每个进程栈占用几个4K页
awk '{if ($$2 == "THREAD_SZ_ORDER") print $$3;}'
include/generated/asm-offsets.h)
-fplugin-arg-arm_ssp_per_task_plugin-offset=$(shell ## offset设置为TI_STACK_CANARY的偏移
awk '{if ($$2 == "TI_STACK_CANARY") print $$3;}'
include/generated/asm-offsets.h))
$(eval KBUILD_CFLAGS += $(SSP_PLUGIN_CFLAGS))
$(eval GCC_PLUGINS_CFLAGS += $(SSP_PLUGIN_CFLAGS))
endif
此插件需要两个参数:
- tso: 代表当前内核每个进程栈的大小,1代表4KB,2代表8KB
- offset:为canary在per thread中的偏移
插件主要代码如下:
static unsigned int arm_pertask_ssp_rtl_execute(void)
{
rtx_insn *insn;
for (insn = get_insns(); insn; insn = NEXT_INSN(insn)) { /* 遍历rtl指令序列 */
const char *sym;
rtx body;
rtx mask, masked_sp;
if (!INSN_P(insn))
continue;
body = PATTERN(insn);
if (GET_CODE(body) != SET || GET_CODE(SET_SRC(body)) != SYMBOL_REF)
continue;
sym = XSTR(SET_SRC(body), 0);
if (strcmp(sym, "__stack_chk_guard")) /* 找到引用__stack_chk_guard的这条指令*/
continue;
mask = GEN_INT(sext_hwi(sp_mask, GET_MODE_PRECISION(Pmode))); /* mask是栈基地址掩码,这里生成代表此掩码的结点 */
masked_sp = gen_reg_rtx(Pmode); /* 生成一个rtx表达式,此变量后续会被赋值为 sp */
/* 在解引用__stack_chk_guard的指令前面插入一条指令, 此指令类似 masked_sp = sp & mask;, 即获得thread_info基地址 */
emit_insn_before(gen_rtx_set(masked_sp, gen_rtx_AND(Pmode, stack_pointer_rtx, mask)), insn);
/* 生成一条 plus指令, 即 tmp = masked_sp + canary_offset; 并将对符号__stack_chk_guard的引用替换为对 变量tmp的引用 */
SET_SRC(body) = gen_rtx_PLUS(Pmode, masked_sp, GEN_INT(canary_offset));
}
return 0;
}
此插件的作用是将指定了-fstack-protector的源码中所有对 __stack_chk_guard的引用,都替换为对 ((sp & mask) + offset)的引用, sp&mask在linux内核中为当前进程thread_info的基地址, 需同时在thread_info中新增一个字段代表per-task canary:
./arch/arm/kernel/asm-offset.c
int main(void)
{
/* arm平台可能同时存在task_struct->canary和thread_info->canary两个结构体,前者用来兼容x86平台代码,后者用来实现per thread canary */
#ifdef CONFIG_STACKPROTECTOR
DEFINE(TSK_STACK_CANARY, offsetof(struct task_struct, stack_canary));
#endif
#ifdef CONFIG_STACKPROTECTOR_PER_TASK
DEFINE(TI_STACK_CANARY, offsetof(struct thread_info, stack_canary));
#endif
}
而内核同样仅需要在内核初始化和线程fork时为其新生成一个随机的canary即可,代码同arm64实现
备注:
一、gcc中aarch64平台函数栈实现
通常不考虑动态分配的情况下一个函数执行过程中使用到的栈大小在编译阶段就已经确定了, pass_expand => expand_used_vars 中会为当前函数中用到的所有局部/临时变量分配栈空间, 而在rtl最后的会在当前的pro/epilogue中插入预留函数栈的代码:
//pass_ira => ira(dump_file); => ira_build (); => ira_costs (void) => calculate_elim_costs_all_insns => set_initial_elim_offset => aarch64_layout_frame
static void aarch64_layout_frame (void)
{
.......
if (cfun->machine->frame.emit_frame_chain)
{
/* FP and LR are placed in the linkage record. */
cfun->machine->frame.reg_offset[R29_REGNUM] = 0;
cfun->machine->frame.wb_candidate1 = R29_REGNUM;
cfun->machine->frame.reg_offset[R30_REGNUM] = UNITS_PER_WORD;
cfun->machine->frame.wb_candidate2 = R30_REGNUM;
offset = 2 * UNITS_PER_WORD;
}
.......
}
//pass_thread_prologue_and_epilogue::execute => rest_of_handle_thread_prologue_and_epilogue => thread_prologue_and_epilogue_insns
void thread_prologue_and_epilogue_insns (void)
{
rtx_insn *prologue_seq = make_prologue_seq (); /* 函数的prologue中插入预留栈空间的代码,最终反汇编代码如 stp x29, x30, [sp, -48]! */
rtx_insn *epilogue_seq = make_epilogue_seq (); /* 函数的epilogue中插入恢复栈空间的代码,最终反汇编代码如 ldp x29, x30, [sp], 48 */
}
以prologue为例:
//make_prologue_seq => targetm.gen_prologue => gen_prologue => aarch64_expand_prologue
void aarch64_expand_prologue (void)
{
......
unsigned reg1 = cfun->machine->frame.wb_candidate1; /* reg1 = R29_REGNUM */
unsigned reg2 = cfun->machine->frame.wb_candidate2; /* reg2 = R30_REGNUM */
if (callee_adjust != 0)
/*
(insn/f 30 0 0
(parallel [
(set (reg/f:DI 31 sp) (plus:DI (reg/f:DI 31 sp) (const_int -48 [0xffffffffffffffd0])))
(set/f (mem:DI (plus:DI (reg/f:DI 31 sp) (const_int -48 [0xffffffffffffffd0])) [0 S8 A8]) (reg:DI 29 x29))
(set/f (mem:DI (plus:DI (reg/f:DI 31 sp) (const_int -40 [0xffffffffffffffd8])) [0 S8 A8]) (reg:DI 30 x30))
])
)
对应汇编代码如:
stp x29, x30, [sp, -48]!
*/
aarch64_push_regs (reg1, reg2, callee_adjust); /* 发射预留sp的代码,callee_adjust是当前函数分析过程中为局部/临时变量需要预留空间的大小 */
......
}
二、gcc中aarch64平台Stack Canary的实现(原始patch见[3])
stack canary的代码是在一个函数从gimple指令序列转换为rtl指令序列的过程中(pass_expand)实现的,主要包括三个步骤:
1. 函数局部变量栈分配时为canary分配存储空间(stack_canary)
//pass_expand::execute => expand_used_vars
static rtx_insn * expand_used_vars (void)
{
/* 开启flag_stack_protect则所有栈变量都延迟展开(在canary分配后才展开 */
......
create_stack_guard (); /* 在当前函数栈中先为canary预留一个临时变量的存储空间 */
......
expand_stack_vars (NULL, &data); /* 展开所有的栈变量 */
}
2. 在函数开头(prologue)将全局canary保存到栈中(stack_canary)
//pass_expand::execute => stack_protect_prologue
static void stack_protect_prologue (void)
{
tree guard_decl = targetm.stack_protect_guard (); /* 获取全局变量"__stack_chk_guard"的变量树结点(没有则创建) */
rtx x, y;
crtl->stack_protect_guard_decl = guard_decl;
x = expand_normal (crtl->stack_protect_guard); /* 获取代表stack_canary临时变量的rtx表达式 */
......
y = expand_normal (guard_decl); /* 获取代表全局变量"__stack_chk_guard"的rtx表达式 */
if (targetm.have_stack_protect_set ())
/* target_gen_stack_protect_set, x是代表stack_canary的rtx表达式, y是代表全局__stack_chk_guard的rtx表达式, 此函数负责生成prologue的插桩代码 */
if (rtx_insn *insn = targetm.gen_stack_protect_set (x, y)) {
emit_insn (insn); /* 将gen_stack_protect_set生成的指令发射到指令序列中并返回 */
return;
}
.......
}
其中targetm.gen_stack_protect_set会根据当前编译选项决定具体插入何种代码:
//targetm.gen_stack_protect_set => target_gen_stack_protect_set => gen_stack_protect_set, 此代码是平台相关,编译器自动生成的
/* ../../../gcc-9.2.0/gcc/config/aarch64/aarch64.md:6888 */
rtx gen_stack_protect_set (rtx operand0, rtx operand1)
{
rtx_insn *_val = 0;
start_sequence ();
rtx operands[2];
operands[0] = operand0;
operands[1] = operand1;
......
if (aarch64_stack_protector_guard != SSP_GLOBAL)
{
/* 对于非global模式(也就是指定了per cpu的寄存器), 这里先不管参数指定的寄存器,而是使用一个伪寄存器来生成指令, 这里会让op1从代表__stack_chk_guard的rtx表达式
替换为一个代表 *( reg + offset) 的表达式,其中offset是参数-mstack-protector-guard-offset指定的偏移 */
rtx tmp_reg = gen_reg_rtx (mode);
if (mode == DImode) {
emit_insn (gen_reg_stack_protect_address_di (tmp_reg));
emit_insn (gen_adddi3 (tmp_reg, tmp_reg,
GEN_INT (aarch64_stack_protector_guard_offset)));
}
......
operands[1] = gen_rtx_MEM (mode, tmp_reg);
}
/*
这里的逻辑就是生成 set op0, op1的代码(op1 -> op0), 而在sysreg和global模式下由于op1不同,最终生成代码也不同:
* global模式下生成的伪代码如: set (mem stack_canary), __stack_chk_guard
(set
(mem/v/f/c:DI //这是tmp guard的地址
(plus:DI (reg/f:DI 85 virtual-stack-vars)
(const_int -8 [0xfffffffffffffff8]) ) [1 D.4511+0 S8 A64])
(unspec:DI [ //这是全局stack guard的地址
(mem/v/f/c:DI (reg/f:DI 91) [1 __stack_chk_guard+0 S8 A64]) ] UNSPEC_SP_SET)
)
* sysreg模式下生成的伪代码如: set (mem stack_canary), (set (mem (set Rx, plus(Rx, offset)))
(insn 4 3 5 (set (reg:DI 91)
(unspec:DI [
(const_int 0 [0])
] UNSPEC_SSP_SYSREG)) "test.c":13:1 -1
(nil))
(insn 5 4 6 (set (reg:DI 91)
(plus:DI (reg:DI 91)
(const_int 22 [0x16]))) "test.c":13:1 -1
(nil))
(insn 6 5 0 (parallel [
(set (mem/v/f/c:DI (plus:DI (reg/f:DI 85 virtual-stack-vars)
(const_int -8 [0xfffffffffffffff8])) [1 D.4511+0 S8 A64])
(unspec:DI [
(mem:DI (reg:DI 91) [0 S8 A8])
] UNSPEC_SP_SET))
(set (scratch:DI)
(const_int 0 [0]))
]) "test.c":13:1 -1
(nil))
*/
emit_insn ((mode == DImode ? gen_stack_protect_set_di : gen_stack_protect_set_si) (operands[0], operands[1]));
}
//最终在final输出汇编代码时,才会在指令模板中将伪寄存器Rx替换为真正参数-mstack-protector-guard-reg指定的硬件寄存器,如:
output_1076 (rtx *operands ATTRIBUTE_UNUSED, rtx_insn *insn ATTRIBUTE_UNUSED)
{
#line 6925 "../../../gcc-9.2.0/gcc/config/aarch64/aarch64.md"
{
char buf[150];
snprintf (buf, 150, "mrst%%x0, %s", /* 生成指令,将参数指定的控制寄存器复制到硬件寄存器x0中 */
aarch64_stack_protector_guard_reg_str);
output_asm_insn (buf, operands);
return "";
}
}
3. 在函数结尾(epilogue)检查stack_canary是否与全局canary一致,不一致则报错
//pass_expand::execute =>expand_function_end => stack_protect_epilogue ();
void stack_protect_epilogue (void)
{
tree guard_decl = crtl->stack_protect_guard_decl;
rtx_code_label *label = gen_label_rtx ();
rtx x, y;
rtx_insn *seq = NULL;
x = expand_normal (crtl->stack_protect_guard); /* 获取代表当前栈中stack_canary的rtx表达式 */
......
y = expand_normal (guard_decl); /* 获取代表当前全局变量"__stack_chk_guard"的rtx表达式 */
if (targetm.have_stack_protect_test ()) /* true */
seq = targetm.gen_stack_protect_test (x, y, label); /* 生成对比stack_canary和__stack_chk_guard的代码,若二者相等(没有溢出),则跳转到 label(见gen_stack_protect_test) */
}
......
emit_insn (seq); /* 发射生成的指令序列 */
......
expand_call (targetm.stack_protect_fail (), NULL_RTX, /*ignore=*/true); /* 发射对函数 "__stack_chk_fail" 的调用 */
......
emit_label (label); /* 最后发射标签指令,若检测没有溢出,则会绕过__stack_chk_fail的调用直接跳转到此标签 */
}
其中 targetm.gen_stack_protect_test => gen_stack_protect_test 生成的指令序列:
- 在global的情况下是从__stack_chk_guard中获取对比基准数据
- 在sysreg模式下是从用户指定的控制寄存器+偏移中获取基准数据,其和2中流程类似.
最后
以上就是感动猎豹最近收集整理的关于Linux 内核安全增强—— stack canary的全部内容,更多相关Linux内容请搜索靠谱客的其他文章。
![Kconfig [@rt-thread]](https://www.shuijiaxian.com/files_image/reation/bcimg8.png)







发表评论 取消回复