随着基因测序价格以超摩尔定律的势态下降,其被广泛应用于基因组学研究、临床诊断以及多种疾病个性化治疗等领域。对此,业内人士认为,当今基因测序行业面临最大的挑战已不再是基因测序技术,而是处理巨大的数据量以及如何从巨大数据中获取临床指导。据雷锋网了解,生物信息分析服务是目前业界公认的最具发掘潜力以及盈利能力的环节,但目前国内还处于起步阶段。
那么,基因数据与其他数据有何异同?处理基因数据又何难点和挑战?基因数据的未来是怎样的?本次公开课,雷锋网AI掘金志栏目邀请了华大基因研发中心副总监金鑫,带来《基因大数据简史——起源、现状和未来》的主题演讲。
嘉宾介绍:
华大股份研发中心副总监、BGI Online平台负责人金鑫,华大基因的青年科学家。

金鑫曾参与了一系列重大科研项目攻坚,包括国际千人基因组计划、中丹糖尿病基因组计划、人类泛基因组图谱计划、高原基因组计划,及自闭症基因组计划等。早在2009年,金鑫就以在校生的身份在《Nature》子刊《Nature Biotechnology》发表《构建人类泛基因组序列图谱》,并首次提出了“人类泛基因组”概念。
公开课视频:
(注:本次公开课中,金鑫博士展示有趣的案例,并回答多个网友精彩问题,所以推荐优先观看视频。)
以下是金鑫博士演讲内容,雷锋网(公众号:雷锋网)做了不改变原意的编辑:
我是金鑫,来自华大基因,我现在是华大股份研发中心副总监,同时也是BGI Online和大数据专项的负责人。今天我想跟大家分享的题目是基因数据起源、传承与演化。
我们都说基因是上帝的语言,在说基因之前,我先给大家看一块石碑,这块石碑叫罗塞塔石碑,已经保存了2200多年,大约是公元前197年制作的,其上面刻有多种语言:希腊文字、埃及象形文字、也有当时埃及的民间文字、罗马文字。实际上,石碑是迄今为止已知的保存信息最长久的一种载体。

我们身体里有很多细胞,每个细胞里都有一个完整的基因组,基因组上所承载信息的载体是ATCG这四个非常简单的基本单元,我们称之为碱基。从地球上有生命起,绝大部分已知的地球生物都是通过DNA的形式来承载我们生命的全部秘密,但所谓的承载和传递并不是只做一次记录,更多的是通过不断的复制把它传递下去,而且传递过程并不是非常精确的完整复制过程,这使得如今整个地球上的物种成千上万、丰富多彩。
基因的起源
很多年前,人类就开始了读基因天书的努力。
在20世纪,人类有三大科学创举:1945年的曼哈顿原子弹计划、1969年的阿波罗登月计划和2000年前后完成的人类基因组计划。
从一开始,我们就是人类基因组计划中的一份子,当时一共有6个国家参加,美、英、法、德、日、中,中国是唯一一个参与人类基因组计划的发展中国家。1999年9月9日,华大基因为完成人类基因组计划中国部分那个1%而成立的。当时要去读取人的基因数据,需要做一个完整的人类基因参考序列,就像一个地图导航坐标系一样,这其实是非常困难的。6个国家成百上千科学家花费了13年时间和30亿美金才完成了第一个人的基因组测序,当然,这个过程中,也带来很多相关学科、技术和产业的发展。我想给大家讲的是,2000年之前,读一个人的基因数据要耗巨资需要十几年的时间。
如今,是一个数据的时代,一个互联网的时代,一个智能的时代,而所有这一切的核心是我们今天讲的数据。
相比其他数据,基因数据的产生有很多特别的地方,基因数据的获取需要一个特别的设备——基因测序仪。2015年10月份,中国第一款的国产自主知识产权的基因测序仪问世,这就是华大研发的。
其实,过去几十年,如同很多的高精尖医疗设备和其他大型设备一样,基因测序仪其实大部分依赖进口。而如今,全球只有两个国家三家公司能够量产临床级别的基因测序仪,两个国家是美国和中国,三家公司是illumina、赛默飞世尔和中国的华大基因。
很多人都非常熟悉摩尔定律,价格不变时,集成电路上容纳晶体管数量18个月增加一倍。而在2007年前后,基因测序技术的大突破使得基因测序成本飞速下降,下降速度甚至超过了摩尔定律的斜率。
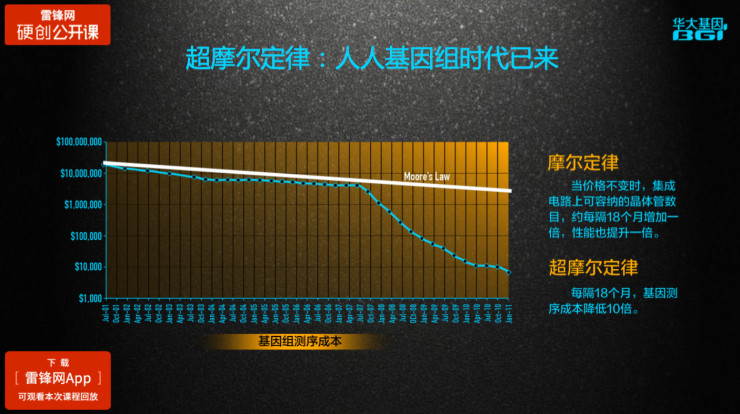
这个图是截止到2011年的1月份的,而如今,这条线已经基本上跟坐标轴的最底部平齐,也就是说读取一个人的基因数据成本已经低于一千美金了。我们相信随着技术的进一步提升、生产进一步规模化,我们还有机会把它变得更便宜。
基因数据与很多其他数据有一个很大的不同点:获取单位数据成本依然较高。淘宝有电商数据、百度有搜索数据、滴滴打车有出行数据,这些是在大家使用的过程伴生的,我们可以认为这些数据产生的边际成本几乎为0,但是基因数据的产生需要专门的操作,通过抽血或取唾液,从中提出DNA,经过专门的基因测序设备,最终才能够得到基因数据。所以,如果基因数据要像其他数据一样被人人所接触、为人人的健康服务,那么其获取成本应进一步降低,获取速度进一步加快。
2003年,我们完成了第一个人基因组测序,从2006年左右开始,有人获得了自己完整的基因组数据,其中就有DNA双螺旋结构发现者沃森。2008年左右,第一次获取了亚洲人的基因数据图谱,后来日本人、韩国人、非洲人等的基因数据也不断被解码出来,但当时,有自己个人基因组数据的人几乎没有,2010年开始,有非常多大型科研项目启动,全球很多人有了自己的基因数据。保守估计,有自己基因数据的人已经超过了数百万,我觉得这是令人非常兴奋的事情,因为对于基因数据,我们曾经是一无所知的,但是从过去十年开始,基因数据非常快速地被获取和积累起来。
传承
英国皇室家庭曾经有人携带一个非常严重的遗传病的基因——血友病,这种基因的突变会导致其凝血能力发生障碍,同时皇室家族又讲究血统的纯正,所以血友病在这个家族代代相传,如今这一代的英国皇室已经基本上没有人是血友病致病基因的携带者了,但是欧洲很多其他的皇室家族中依然有血友病基因存在,这就是基因数据代代相传。把自己的基因传递下去,其实是每一个个体、每一个物种的最基本本能,基因传递了我们所有的各种各样的特征,也包括了致病基因。
遗传是代代相传,但同时也有一母生九子,九子各不同,生命传递的过程中有变异存在的可能性,而这个变异所带来的风险其实是每个人都可能会遇到的每个人都可能会遇到的。
我们之前做过一个自闭症科研项目,其中选取的自闭症样本都是父母双方正常,但是他们的孩子却很明确地判定是自闭症,基因检测发现父母双方没有任何奇怪的基因。关于孩子发生严重的疾病原因,后来有很多专家说是父母双方将其基因传递给子代时,后代的基因更多来自于父方。男性跟女性的生殖策略是非常不同的,女性一生中卵子的数目是确定的,大约每月排出一个卵子直到绝经,但是男性从有生育能力开始就在大量的复制精子,以量取胜,成千上万、甚至上亿颗精子不断的被生产出来,而精子复制过程中发生新突变的可能性比卵子要大很多。
我们曾经做过一个观测,我们找到了很多家庭,把这个父亲的年龄作为一个自变量,观测父亲年龄跟孩子基因中发生新变异的数量的关系,发现一个明显的正相关关系,据当时估算,父亲的年龄每增加一岁,孩子就有可能会增加一个左右的新突变。人类基因组数量很大,基因突变可能发生在任何的位置,可能在绝大部分位置的小突变,不会有什么问题,但是如果不幸,突变发生在很重要位置上,那么孩子就有患病的风险。
那么,为什么生命数据要这样呢?为了把基因数据传递下去,相对更精确得复制、产生的错误更少一些不是更好吗?
如果我们从整个物种的角度讲,对此的考虑就可能会很不一样。在某种程度上,新突变增加了物种基因多样性。如果基因多样性变得单一,那么物种继续发展下去就变得比较困难。
举一个非常简单的例子,广东、广西和海南省地中海基因携带率相对较高,这是有原因的,这是人类生存过程一种与环境的妥协,地中海贫血基因一开始是在地中海沿岸发现的,而地中海贫血大都发生在这个维度上,原因是这样的,很久之前,在这种维度的自然和气象环境之下,疟疾高发,一旦患病非常严重会导致死亡,而地中海贫血致病基因携带者对疟疾有一定的抗性,在人类还没有别的手段控制疟疾时,这种基因携带者有生存优势,最终,导致地中海贫血致病基因在这些地区大量传开了。
如今,我们经常会被问到,是不是携带某种坏基因?但什么是好基因,什么是坏基因呢?从根本上讲,基因没有好坏之分,只有多样性。这种多样性导致有些人由于基因突变看起来与我们不一样,但这其实为人类生存赢得一种新的可能性,比如环境、气象和地质条件发生大规模的变化,或整个食物结构发生巨变等,这时如果说人类基因都非常相似的话,那人类这个物种生存的可能性就会大大降低。
基因科技&未来
那么,对于严重遗传病、肿瘤、传染病等,科技能做什么呢?
从生育角度,像地中海贫血这样的遗传病可以在宝宝出生之前进行产前检查,尤其是在高发地区,甚至在备孕之前就可以去做基因检测,进行相应的准备并接受指导。如果检查结果是父母双方携带同样的遗传病致病基因,可以进行相应的干预,比如植入胚胎,选择没有携带致病突变或说不会引起疾病的基因拷贝的胚胎做植入,如果成功受孕,宝宝就肯定是健康的。另外还有不孕不育的问题,一部分不育是因为习惯性流产,其中一大部分与基因有关,可以通过基因检测发现和预防。
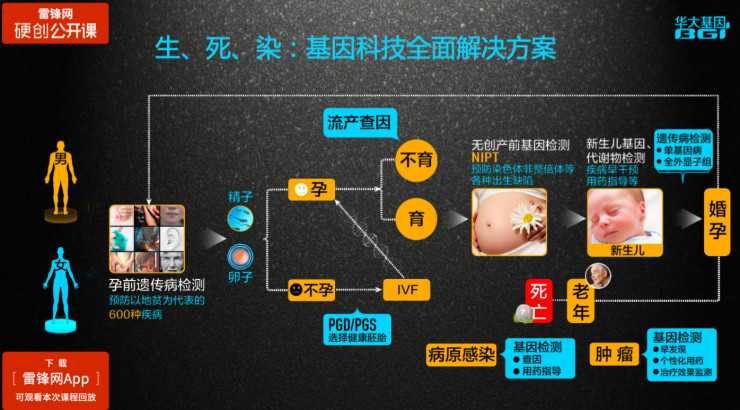
如今,我们做的最多的是无创产前检查,用于筛查21-三体综合症。未来,我相信每个宝宝出生时都会做一个基因检测,读取其基因数据,用于疾病预防和用药指导。
如今,我们还面临很多其它挑战,比如肿瘤。肿瘤最重要的是预防,当处于肿瘤中晚期发现时,治疗办法是非常有限的,如果能早发现、早期筛查并且辅以个性化药物的话,能有效控制病情甚至未来可能治愈。我们现在知道肿瘤是一种基因病,是环境和基因共同导致的。基因检测不仅仅意味着早期筛查,同时这项技术对药物研发也有重要作用,比如对肿瘤细胞进行基因检测,找到其特异性的标靶序列,把这些序列添加到经过加工的免疫细胞上,将这个免疫细胞注入身体中,这种技术能在一定程度上治疗肿瘤。
大家可能对SARS记忆犹新,在非典病人的组织液、血液等提取病原体,进行基因检测,能确定病原体类型。如今,我们基本能做到,对于绝大部分已知的病原微生物,我们不仅可以知道它是什么,而且可以知道其有没有抗药性、对某种抗生素是否有抗性等。
那么,基因技术能做什么?
精准医疗人人都在讲,但精准医疗的基础是基因数据。2016年,这三家公司都积累了100多万人的部分基因数据,所谓部分基因数据,是通过基因芯片技术,读取部分数据得到某方面的基因信息。
华大基因也积累了很多数据,到2016年4月份时,仅仅无创产筛这个项目就做了100万人,但我们是通过全基因组数据测序获取数据的,所以尽管样本量差不多,我们的数据量级是远远超过他们的。而到现在,华大基因的数据量至少已经翻倍了。
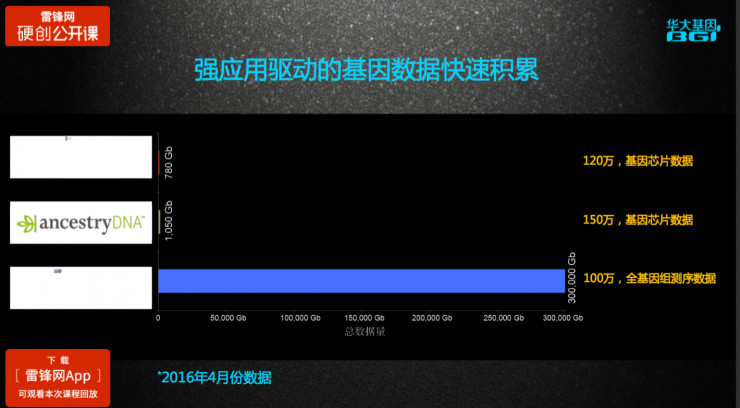
2001~2015年,基因数据产生是大型研究机构推动的,2015年之后,研究机构和企业有了很多基因检测的应用,从研究项目驱动转为研究项目和应用共同驱动,基因数据的积累速度肯定会加速的。
但随着基因数据积累,读懂基因这本天书的重要性和难点就凸显出来了。
对于人类基因组,我们可能认识了不少单词,粗略地理解了语法,但还完全不懂断句,所以我们对整篇文章一无所知,我们对基因的了解还处在非常早期阶段,我们可以从简单的物种开始做起,比如最简单的生命、病毒等,但依然有非常多的挑战,但我认为,大数据和人工智能/机器学习将会为其带来突破。

基因数据与其它数据有区别,获取数据的成本比较高,同时数据量大。若用现在的技术,若要将基因数据读得准确,需要读很多份并组合起来,才能知道其排列,一般要读30次,肿瘤研究中,有时候会测几百次甚至几千次。每个人的基因数据至少有100G的原始数据,如果把全中国人的基因数据全都读出来,怎么存、怎么处理就是一个很大的问题。
我们知道了基因数据,也知道其最终的表现,随着数据增多,我们就有可能理解基因数据,这其中会用到人工智能技术。但以我们目前处理信息和数据的能力,理解、解读、归纳和总结基因数据的挑战非常大。但如今人工智能技术有很大的突破,加上愈来愈便宜的数据产出,我们认为这件事未来是美好的。
科学发现推动了技术发明,技术发明带动了产业发展,三个齿轮互相联动,科学发现是核心。本质上,我们要把科学问题转化成技术问题,技术问题转化为经济问题。马斯克最近说到99%的科研论文都是没用的,他表达的意思与此类似,科研只是进行了探索和验证,最终还需要工程上的落地。
那华大做了什么呢?我们希望将单个基因读取的成本降至极限,这意味着每个人有更大可能性获取自己的基因数据,同时基因数据与个人的关系也会更大。同时,我们在云端做基因数据分析——即华大基因BGI平台,希望把基因数据分析的成本降至极限,通过与阿里云合作,基因数据分析的成本已经降至100元以内了。
物理、数学中都有很多定理和公式,但生物学中没有,希望随着生命数据积累越来越多和分析技术的逐步提升,生命科学也能有一个核心公式。
| 本文作者:张利 |
最后
以上就是醉熏花生最近收集整理的关于华大基因BGI Online负责人金鑫主讲:基因大数据的起源、现状与未来| 硬创公开课...的全部内容,更多相关华大基因BGI内容请搜索靠谱客的其他文章。








发表评论 取消回复