支持向量机可谓是机器学习道路上的第一个拦路虎,不仅证明复杂,而且很多入门资源也并不适合新手,本人足足花了半个多月的时间,才对整体的数学推导有了一些掌握,写个博客,加深记忆。文章有什么不好理解的请提交评论。
提前说明
下面的截的图里w(带T上标的)跟正文中的w都表示法向量。
1. 什么是支持向量机
支持向量机是机器学习领域的一种分类算法,通常用来解决二分类问题。
2. 核心思想
以简单的二分类为例,传统的分类器,比如感知器、逻辑回归都是找一个超平面将正例与反例分开。支持向量机也是如此。
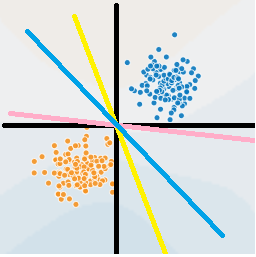
但有一点不同,支持向量机除了能找到超平面分开正反例,还能保证该超平面是最好的分界面,如下图,
下面三条线哪一条能最好地将正反例分开,显然是中间的蓝线,因为数据集的局限性和难以避免的噪声因素,训练集外的样本可能比图中的样本更靠近中间,中间的蓝线比其他两条线更难受此影响。
因此,这也是支持向量机要解决的核心思想,找到最优的超平面来分割样本。
3. 如何找到这样的最优超平面
首先,我们给出表示超平面的线性方程:
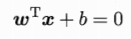
(这里的w表示法向量,控制超平面的方向;b表示截距,控制超平面到原点的距离。)
为了找到这样一个超平面,我们要让离他最近的样本点到超平面的距离尽可能地大。因此首先我们需要一个点到超平面的距离的表示方法。
函数间隔的定义
先给出函数间隔的定义,后面要用到。通常的,一个点距离超平面的远近可以表示分类预测的确信程度,在超平面wx+b=0确定的情况下,|wx+b|能相对表示样本点x到超平面的远近。而预测值wx+b的符号和真实标记y的符号是否一致表示分类是否正确,可用y(wx+b)表示分类的正确性和确信度,这就是函数间隔的概念。
但函数间隔并不是一个确定的值,不能用来表示点到超平面的距离。比如把w和b放大到2倍,2*(wx+b)=0,还是原来那个超平面,但函数间隔|2*(wx+b)|却扩大了两倍。
因此要引入几何间隔的公式,
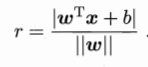
几何间隔的大小不会受到w和b缩放的影响,因为下方的||w||也会等比例缩放,跟上面的抵消了。
接下来,我们要做的就是找一个超平面,使离超平面最近的点到超平面的距离尽可能大。(这些点被称为支持向量)
显然正例和反例支持向量到这样一个超平面的距离是相等的,我们把这个距离设为R。还记得前面说的超平面不变的情况下,函数间隔可以任意缩放吗?因此我们索性直接把R缩放到1,这样求起来也比较方便。
对于每一个样本点,他的每一个正确的样本点一定是分布在支持向量两端的。(wx+b>=+1;或者wx+b<=-1;)
把满足wx+b>=+1的样本点标记为正例,y=+1;
把满足wx+b<=-1的样本点标记为反例,y=-1;
合起来,负号跟负号约掉,可以直接写成:y(wx+b)>=1。
函数间隔被缩放为1,因此两个支持向量到超平面的距离之和为:
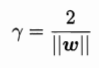
我们要做的就是在满足样本被正确分类的情况下,使几何间隔最大化。
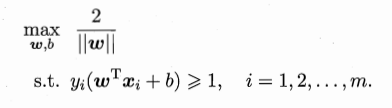
显然,最大化1/||w||等价于最小化||w||的平方,为了计算方便,上面的公式可重写成:
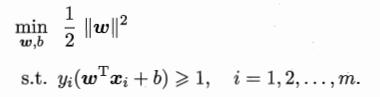
这也是SVM的基本型。
回答一下标题的问题,如何找到这样的最优超平面?
答:找到满足上面公式的的w和b,便能确定这样唯一的最优超平面。
4.如何找到满足上面公式的w和b
上面的公式本身是一个凸二次规划(QP)问题,能直接用现成的的优化计算包求解,但这里给出一种更为高效的方法。
利用拉格朗日对偶性得出对偶问题,然后通过求解对偶问题来获得最终的解,这样有很多好处,后面再解释。
学过高数的都知道拉格朗日乘子法这个概念:这里为每一条约束y(wx+b)>=1添加拉格朗日乘子a:
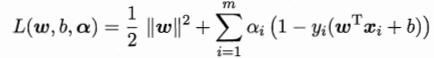
而其对w和b进行求偏导的结果也都为0,可以得出(可以自己计算一下):
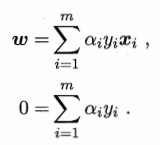
把第一个关于w的公式带入原式,可以正好将原式w和b约掉,化简得到:
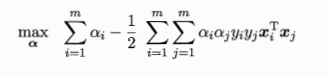
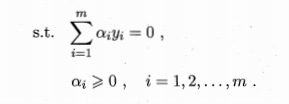
第二个式子作为其约束条件,这样就得出了原来问题的对偶问题。可以看到,对偶问题中,只要解出来对应的ai,就能求出w和b,得出最终的判别模型。
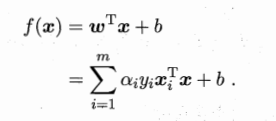
5.最大软间隔支持向量机
好了,考虑一下下面的情况
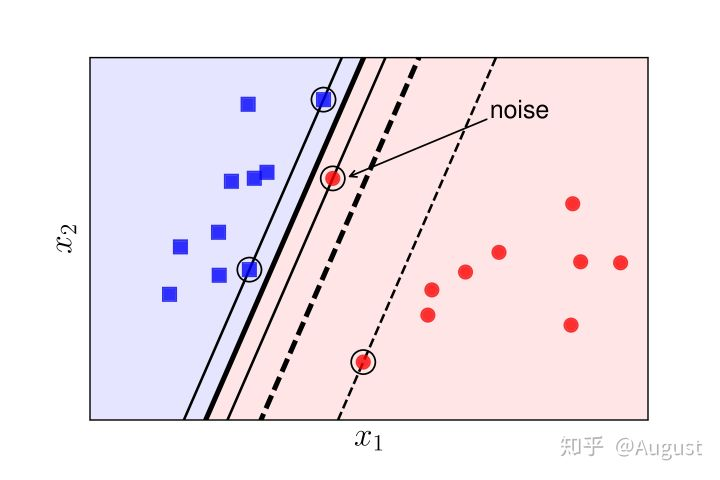
按照前面讲到的硬间隔最大化支持向量机算法,我们会得到图中的黑线作为超平面,但这种分类真的好吗?红点看上去很像是一个噪音点,如果按照黑线划分,很容易造成过拟合,显然我们应该想办法排除掉这样的噪音,最后用图中的虚线作为分界面是最好的。
接下来就需要介绍如何实现这样的功能了:
普通的约束条件要求y(wx+b)>=1,表示正确分类的点在支持向量两边。图中的噪音点显然在两个支持向量内部,满足0<y(wx+b)<1,因此我们可以引入一个松弛变量,约束条件变为:
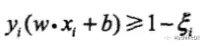
这样的约束条件可以让分类器对噪音点更加包容,防止过拟合。但我们当然要将包容程度控制到最小,因此引入松弛变量的同时,增加一个惩罚参数C。原函数变成。
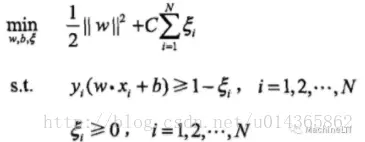
C是人工决定的参数,显然C越大,对噪音包容程度越小。
之后再利用前面讲到的拉格朗日乘子法把原函数转换成对偶问题。对w,b,松弛变量求偏导,最终结果为。
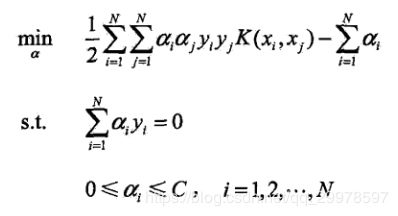
可以看到跟硬间隔支持向量机的区别就是多了一个C,对a的限制加强。
6.非线性支持向量机
前面讲的都是找一个线性的超平面,把正反例分开,但假如样本不能被线性划分呢?这里就要用到一个概念,低维空间线性不可分的样本到了高维空间更有可能线性可分。
这里介绍一个核函数的概念,简单来说,核函数可以返回样本在高维空间的内积。
这里,转换成对偶问题求解的优越性再次体现了,我们观察一下对偶问题的函数。发现函数中有样本内积,因此我们可以直接引入核函数。常用的有多项式核,高斯核等等。这样就能进行非线性划分了。推导过程跟前面的差不多,非常方便。
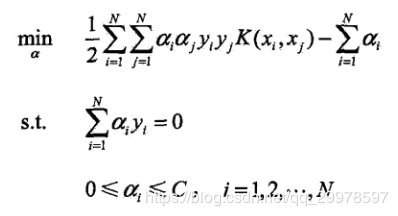
7.如何求出ai
我们通过拉格朗日对偶性将关于w和b的原问题转换成了关于ai的对偶问题,接下来就是要求出拉格朗日乘子ai的值。
为了解出上面的对偶问题,要用到SMO算法。
算法的思想是这样的:每一次优化两个拉格朗日系数a1,a2,固定其他的拉格朗日系数为常数,这样就能简化目标函数为只关于a1,a2的二元函数。
1.比如说选择了a1,a2,那么满足
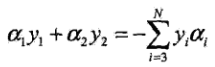
下面的式子其他的ai都固定为常数,可以去掉。
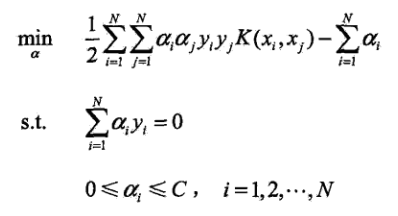
整理得到
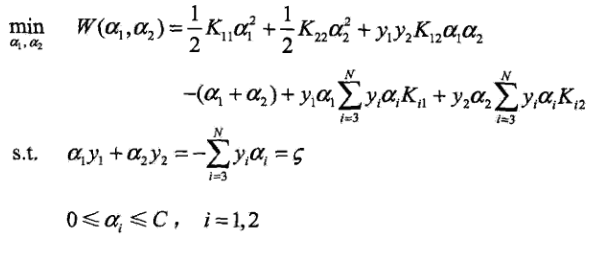
接下来对于二元函数,我们可以画出他约束条件的图形表示。
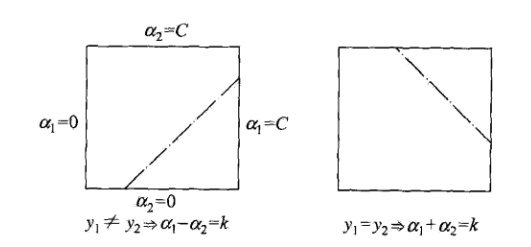
这里直接给出a2的计算公式,《统计学习方法》书上有详细的证明过程。
注意:a(old)的初值为0。
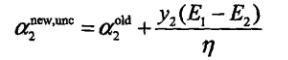
然后可以得到a1:
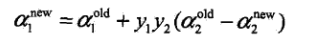
每次更新完两个参数a1,a2,都要更新b和Ei的值(说实话,对b的计算还有一点模糊,直接给出结论):
- 对0<a1<C的情况:
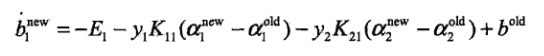
- 对0<a2<C的情况:
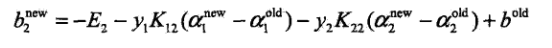
- 否则:
b=上面两个平均值
得到新的b,利用这个更新E1,E2。
所有的a计算结束之后,便可以根据下面的目标函数来进行分类判断,可以看出,根据KKT条件,非支持向量的a都等于0,因此最终的判断结果只跟支持向量有关。
8.顺便贴上用程序实现该算法的大致流程
- 从训练集中读入数据,然后初始化svm。(包括x,y,len(x),高斯核参数sigma,惩罚参数C,松弛变量toler,核函数对应核矩阵,截距b=0,拉格朗日系数ai=0,预测值与真实值得差值Ei,支持向量的标号记录supportvecIndex)
- 开始训练,先设置结束条件,迭代次数达到iter,或者一次迭代没有参数改变,也就是
a1_new=a1_old,a2_new=a2_old。 - 用SMO算法求出a,先选择第一个不满足KKT条件的a1,然后利用启发式找到a2。根据a1和a2的标签是否一致生成不同的L和H,a2_new=a2_old+y2*(E1-E2)/(K11+K22-K12),a2_new如果越过(L,H)则取值为L或H;接下来自然得到a1_new=a1_old+y1y2(a2_old-a2_new);
接下来到了确定b,
然后得到新的b,利用这个更新E1,E2。if(0<a1_new<C) b=-1 * E1 - y1 * k11 * (a1_new - a1_old) - y2 * k21 * (a2_new - a2_old) + self.b elif(0<a2_new<C) b=-1 * E2 - y1 * k12 * (a1_new - a1_old)- y2 * k22 * (a2_new - a2_old) + self.b else b=上面两个平均值 - 全部计算完毕,然后统计一下ai大于0的样本点,他们就是支持向量。
- 支持向量都有了,根据目标函数f(x)=sign(连加i从1到N aiyiKij+b)j为预测样本的标号。
9.结语
终于把有关SVM的内容理了一遍,SVM作为机器学习道路上的一条拦路虎,可以说是一门劝退算法。不过硬着头皮,一步步推导,啃下这个硬骨头,对你机器学习的基础是很有帮助的,再回头看别的算法,会不会有一些更深的理解?努力吧。
最后
以上就是踏实墨镜最近收集整理的关于对支持向量机的数学推导(个人理解的内容)的全部内容,更多相关对支持向量机内容请搜索靠谱客的其他文章。








发表评论 取消回复