近期趁着闲下来整理一下之前做的各种东西。
首先是这么一个猫脸识别器:基于Google提供、Tensorflow框架下的object detection API,只需准备几百张自己的数据集,在Google提供的训练好的模型上进一步训练,可以在短时间内得到一个性能相对较好(准确率95%左右)、最终调用接口也十分方便的自定义识别器。基于已有模型、实现对新物体识别的训练方法叫做Transfer Learning。
个人认为Google这个接口十分良心,直接方便了广大工程师,可以快速地完成自己的特定应用,例如在摄像头中监控特定目标是否出现等等。而且这个识别器既包含分类(Classification)的功能也包含了精确定位位置(Detection)的功能,下一步大概就是Segmentation了吧(笑)。
再说回猫脸识别。调查猫脸识别的时候,我们发现CSDN上倒是有基于opencv的代码,但是在Cats v.s. Dogs的数据集上跑了一下效果并不好,并且各种参数十分莫名根本不知道该怎么调。该数据集本来是一个猫脸狗脸识别大赛的数据集,对于我们的应用刚好合适。Google的API有整只猫的识别,但是没有猫脸和猫眼睛的识别,于是就想到了在已有模型上进行Transfer Learning,可以快速达到目标。
主要参考了以下内容:
[1] Google自己github上的说明,此说明写的非常详细,只看这份说明就可以完成所有的操作。
https://github.com/tensorflow/models/tree/master/research/object_detection.
[2] 英文不够好导致不能清楚理解的朋友可以跟我一一样参考一下这篇中文博客~一篇讲的还可以但不够仔细的linux上的实现。
https://blog.csdn.net/c2a2o2/article/details/78436735.
[3] 原博文找不到了,在原模型基础上学习识别Racoon(小浣熊!),github上的代码架构十分清晰,但是README写的十分简略。
https://github.com/datitran/raccoon_dataset.
我自己的github代码里有较为详细的说明,如果使用的话需要修改路径为自己的路径:
https://github.com/Orienfish/cat_face_detection
那我们正式开始。
整体的实现可以分为几个以下步骤:
一、环境搭建
安装Tensorflow Object Detection API的环境,具体一步一步跟着[1]中Installation的安装步骤走就没问题。我遇到的问题主要有二:
1、Protobuf的版本要求3.0.0以上,如果直接使用pip install可能安装较低版本,需要手动去官网上安装新版本。
2、cocoapi(已有的模型如果是通过coco数据集训练出来的,可能需要用到,我是这么理解的,不知道对不对)的路径需要加到环境变量中。使用如下语句可以把cocoapi的路径添加到环境路径中,我把这句加到了最终脚本中,这样就不用每次手动设置了。
export PATH=$PATH:/home/robot/cocoapi/PythonAPI
二、数据准备
由于是Transfer Learning,所以数据准备不需要太多,几百张就足够达到不错的效果。数据标准使用LabelImg,具体就是无脑操作,用框框手动把目标框出来,打上标记。由于我比较懒,这一部分工作都是学弟做的,他给我的时候已经是.xml文件。我们一共标记了300张图片,其中240张用于训练,60张用于测试。
完成了这一步之后,通过[1]中给出的xml_to_csv.py和generate_tfrecord.py将.xml转成.csv最终转成tfrecord文件方便输入Tensorflow搭建的框架。(突然有一个问题,为什么一定是.xml格式,为什么中间一定要有一个.csv格式过渡,为什么一定要用tfrecord格式输入Tensorflow?)这部分功能可以通过以下语句实现:

以上完成训练数据准备。
三、训练配置与训练
训练的一些设置,例如路径的设置,训练次数等基本参数,都需要手动修改一个.config文件。这一部分在[1]中Configure the Object Training Pipeline也有详细的说明。需要注意的是以下几个参数:
1、train_config中的fine_tune_checkpoint:用于指出已有模型的路径。Google提供的已有模型可以在model zoo里找到并下载,部分model的性能列表如下。这里我们选择速度快、准确率相对偏低的ssd_mobilenet_v1_coco。之后的from_detection_checkpoint用于选择是基于分类的模型还是识别的模型,一般都设为True,选择效果更好的识别的模型。
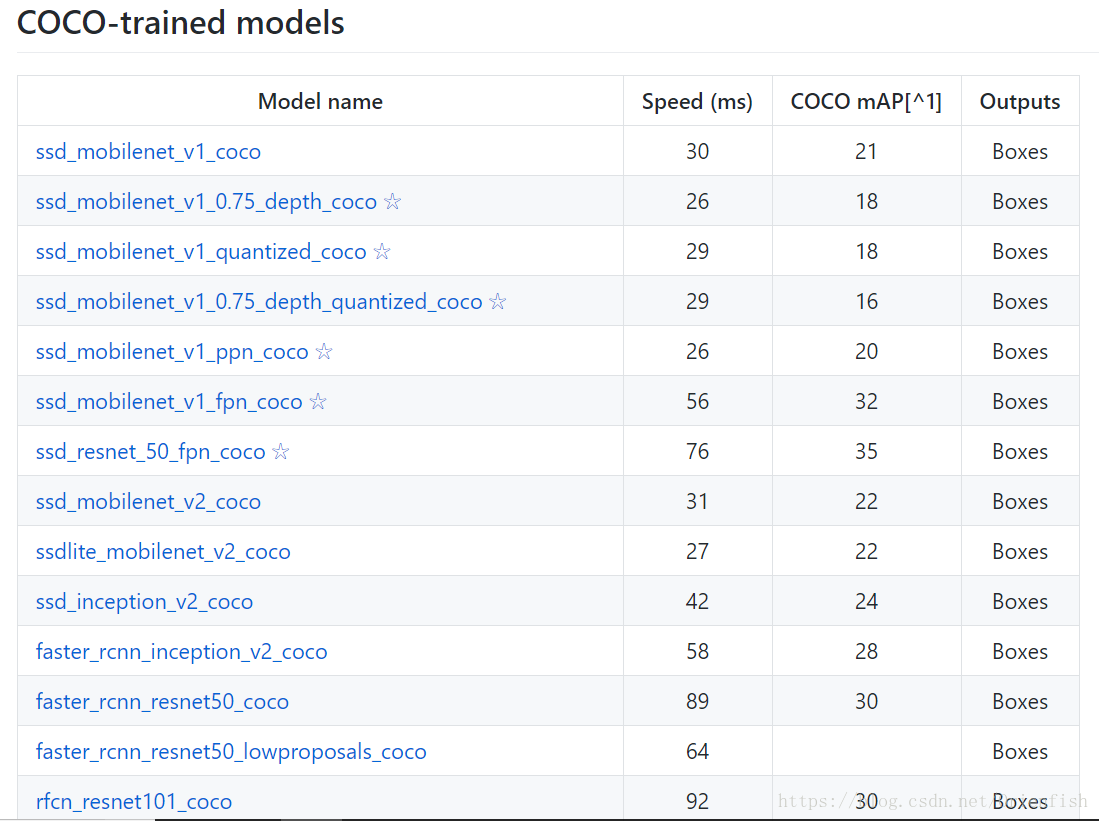
2、train_config中的num_steps:训练次数,本应用中发现20k次就足以,训练20k次耗时4h30min。
3、train_input_reader和eval_input_reader中的input_path和label_map_path:准备好的数据的路径和label map。所谓label map就是下面这么个东西,反映从id到label的映射关系。

4、eval_config中的num_examples:测试集图片的数量,改变数据量的时候一定记得要改!!
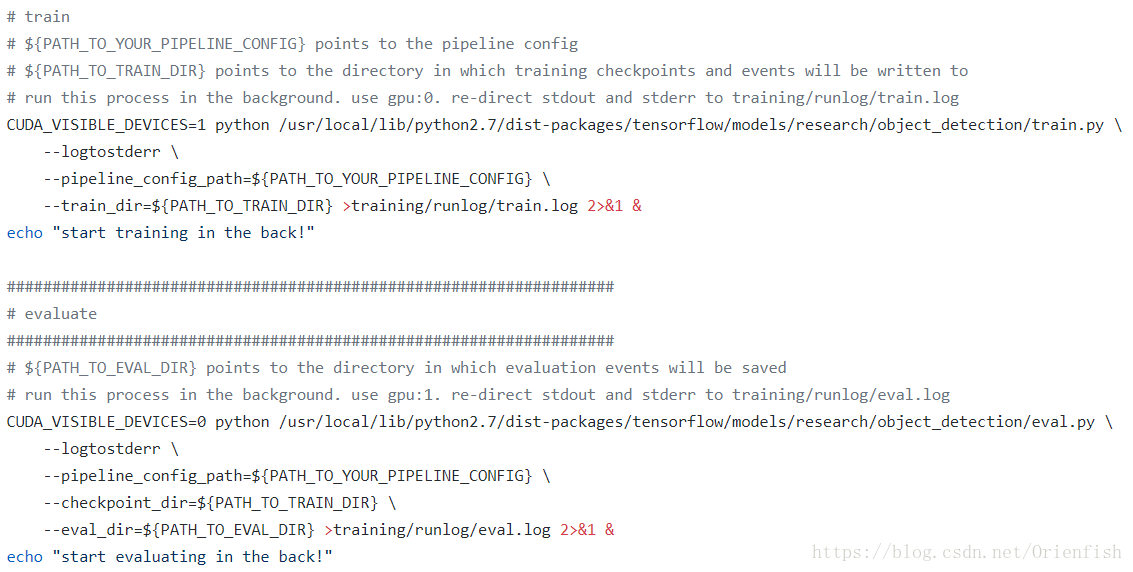
训练的过程也十分简单。并行运行训练、测试、tensorboard三个进程即可,训练和测试的代码都已写好,只要调用就行。唯一需要注意的是需要设置一下训练和测试占用的GPU资源,如果不设置,官方代码就会直接占用它能看到的所有GPU资源……
为了方便我把训练的语句写成了脚本run.sh,这样就不用每次敲巨长的命令来启动训练了。为了并行运行三个进程,每运行一个就放到后台去,同时拿一个文件记录log(要不然怎么挂了你都不知道)。然后检测当训练进程结束后就杀死检测的进程。启动训练和测试的脚本代码如下。
tensorboard上记录的训练曲线如下所示,橙色是训练的曲线,蓝色是测试的曲线。
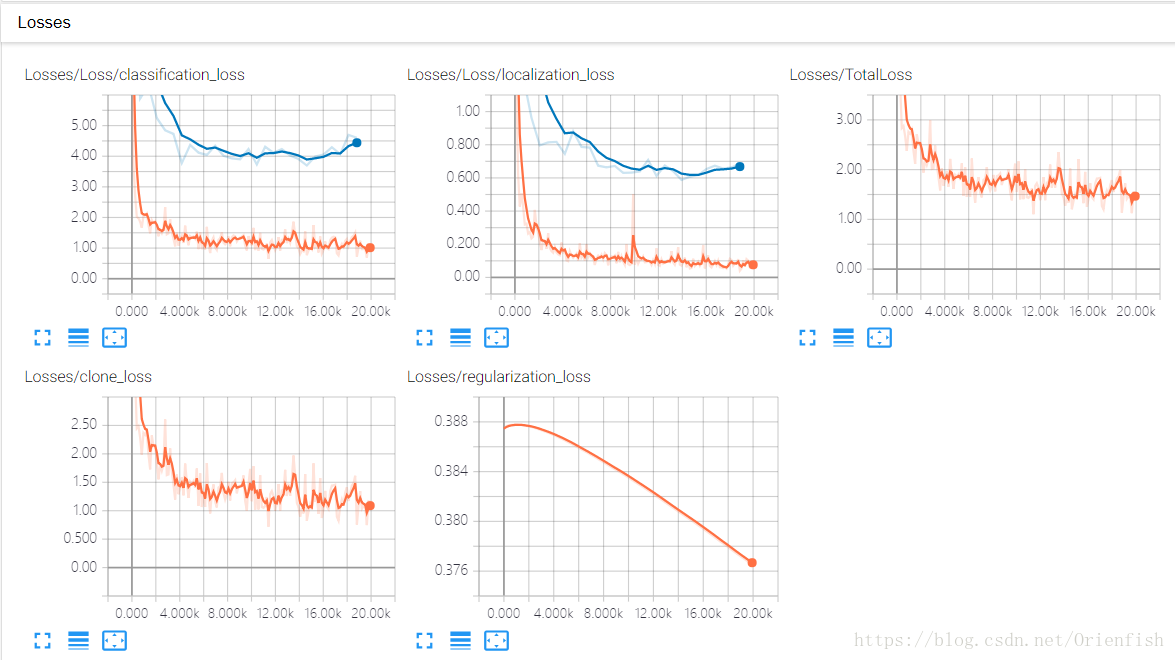
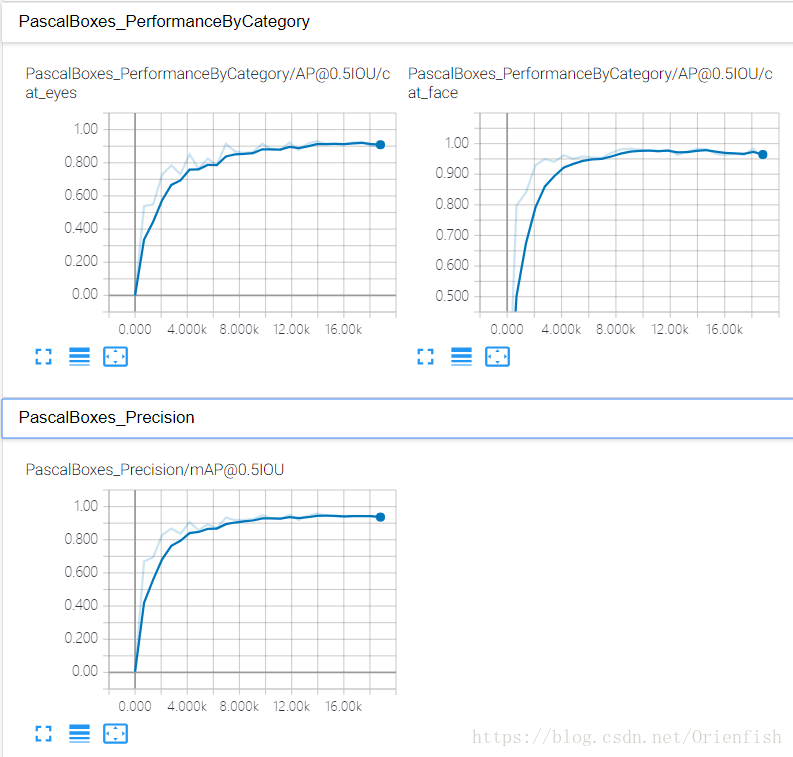
最终的准确率在95%左右,看losses曲线有过拟合的现象,但是尝试修改了l2 regularize的权重,并无明显效果。这是未来改进的方向。
完成训练和测试并没有结束。还要把训练的模型导出,对接之后应用的接口,并进行简单的测试。这就有了export_and_test.sh脚本。本来想把这个脚本和run.sh写成一整个脚本的,但后来发现,使用时往往需要通过训练结果选取测试准确率最高的模型导出,而这个模型在训练结束前是不知道的。所以不得已将脚本分成了两部分,并且在调用export_and_test.sh前需要手动修改checkpoint到想要导出的模型编号,如下图。

四、调用
调用的方法可以参考[1]中object_detection_tutorial.ipynb,我的调用代码就是从jupyter下载.py代码后修改而成。(说起来刚学会用github还不会用jupyter呢,尴尬)使用CPU识别一次的时间大约为0.7s,使用GPU则为0.4s,调整图片大小对耗时影响不大。
好的,说完了整个实现的步骤,我们来看一看实现的效果!
正常的效果是下面这个样子的!
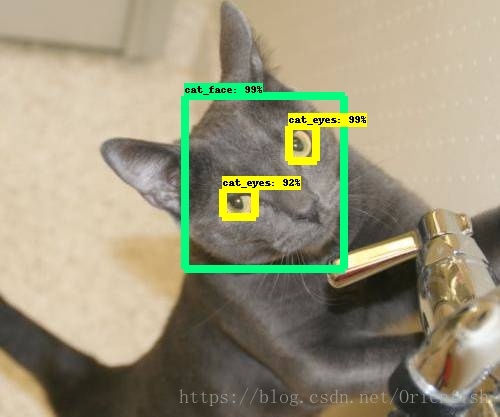
但是有一些不规则的较难情况就无法识别出来,比如侧脸(如下图),这需要增加训练数据来改善,毕竟这才用了240张图片来训练。

最后,来总结一下整个过程中学到的小知识们~
1、改善过拟合的思路有四个:
- 在训练中加入dropout
- 在训练中加入batch normalization
- 在训练中加入regularization
- 数据增强data augmentation,就是增加图片的噪音
2、python中==和!=用来判断值是否相等,这与c是一样的。
同时python中还有一个表达式is和is not,这个是用来判断两者是否是同一个对象,并非两者的值是否相等。
本来这两种表达是毫不相干的,但有一种表达是if a is not None: ……导致不明白的话会有些混淆。
3、脚本语言中对于空格的要求十分严格,例如赋值时等号两边不能有空格,同时if语句括号中诸多空格需要特别注意,如果多一个或者少一个都会报错。

最后
以上就是清脆蚂蚁最近收集整理的关于基于Google object detection API的猫脸识别器的全部内容,更多相关基于Google内容请搜索靠谱客的其他文章。








发表评论 取消回复