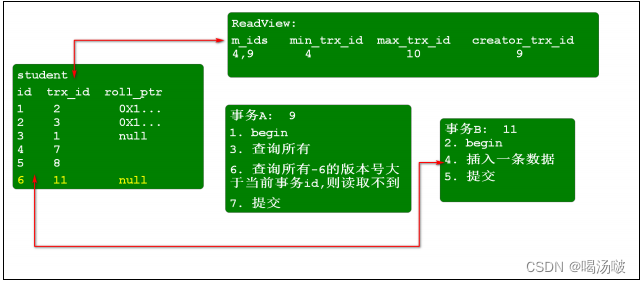
mysql默认隔离级别为可重复读,是否会产生幻读?
不会产生幻读
通过MVCC来解决幻读
如何进行慢sql优化
进行SQL优化的第一步,是先查找哪些查询sql执行效率低。
慢sql日志功能:
-在mysql会有一个日志文件用于记录执行时间超过指定时间的sql,这个日志文件就叫做慢sql日志。
- 该功能在mysql中默认不开启,若想使用该功能,需要开启
操作慢sql日志的sql:
1. 查看慢sql日志是否打开:`show variables like 'slow_query_log';`
2. 开启慢sql日志功能:`set global slow_query_log=1`
执行时间超过10s时,默认视为慢sql,会将该sql记录到日志文件中。
3. 查询慢sql日志设置的时间:`show global variables like 'long_query_time'`
4. 如果需要,可以修改设置时间(阈值时间): `set global long_query_time=2`
5. 查看日志文件: `show variables like 'slow_query_log_file'`
注意点:对慢sql日志功能设置完成,需要重启数据库服务器,才能生效
慢sql日志文件在数据库安装路径中的data目录下(前提:打开慢sql日志功能)
确定慢sql是哪些后,如何对sql进行优化
1. 看慢sql是否使用了*,若是,则改为具体的字段
2. 看慢sql是否使用了嵌套查询,此时是否可以将嵌套查询转换为联查,若可以,则使用联查,因为联查的效率 高于嵌套的.
3. 检查查询条件部分是否可以使用索引,若可以,确定查询条件字段是否使用了索引,若没有,则添加索引
如何优化数据库?
使用读写分离,主从复制,集群,分库分表
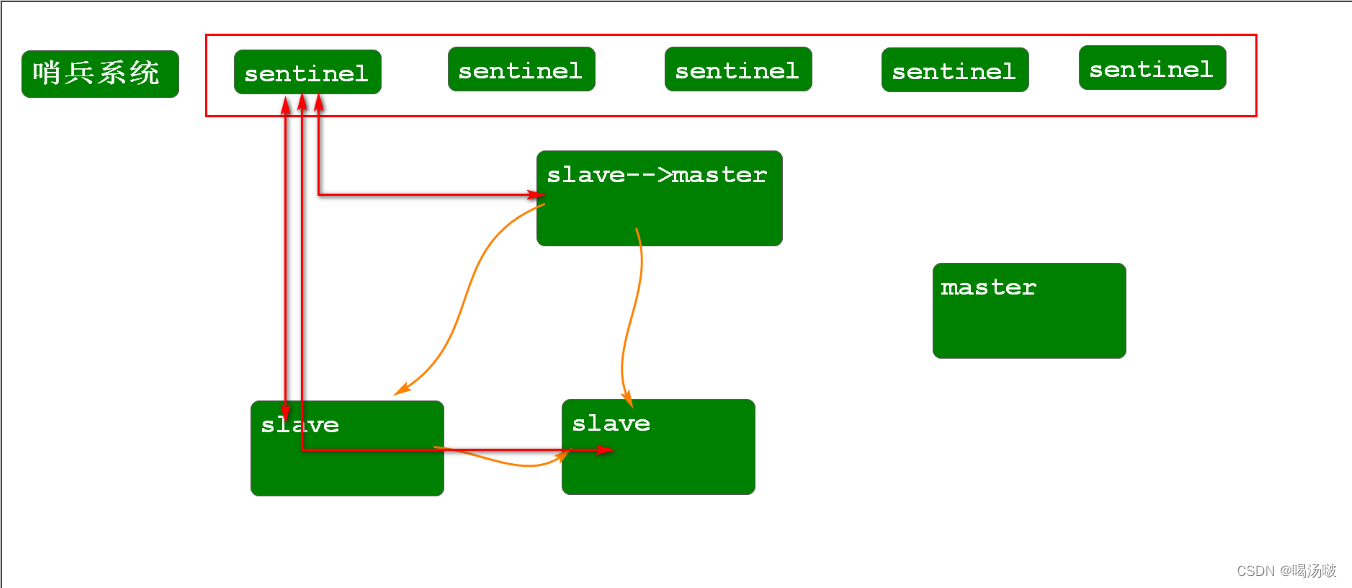
如果主服务器宕机了,怎么办?
哨兵模式解决这个问题
哨兵系统中存在若干个哨兵实例,每个哨兵实例都会通过心跳机制与所有的服务器保持联系,每个一定的时间哨兵实 例会向所有服务器发出pin命令,服务器接收到后会给出响应,若某个哨兵实例没有接收某台服务器得响应,则主观认 为该服务器宕机,但是主观认为不代表客观宕机,此时需要确定是否真的宕机,方式为:该哨兵实例会向其他的哨兵发 出询问,若超过半数的哨兵都接收不到对应的响应,则客观认为服务器宕机,若宕机的是master,此时哨兵系统会从从 服务器中选举一台作为新的master,将原来的master从集群中移除,并通知其他所有的slave,master发生了改 变.让新的master与所有的slave重新建立联系.
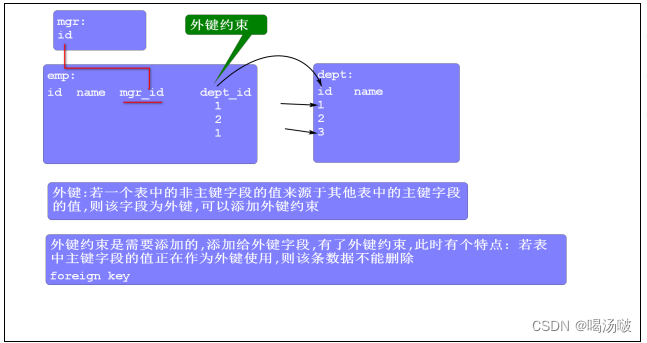
索引 – Index
什么是索引
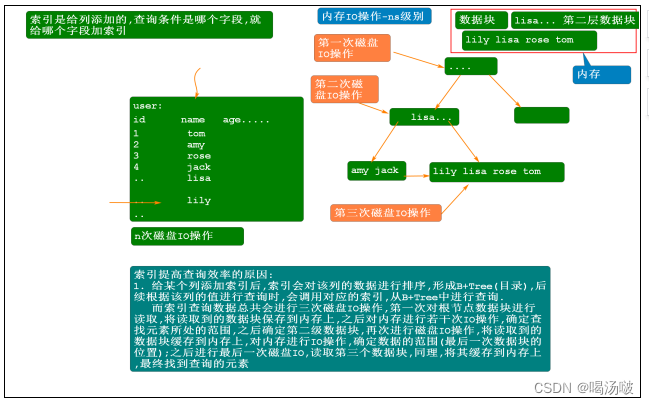
索引是作用于列上,用于对该列的值进行排序,形成一个目录,从而提高该字段的查询效率的,索引适用于数据量大的 表中
索引底层是B+Tree
B+Tree是基于BTree
BTree数据结构 -- B:balance 平衡
数据结构可视化网站[:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html](:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html)
BTree的特点:
1. 以数据块来保存元素,实现排序
2. 每个数据块中最多保存degree-1个元素,当数据块中的元素数量达到度的值时,此时会进行分裂提取,将最中间 的元素提取到上一级数据块中,将原数据块分裂成左右两个数据块
3. 查询优势:每次比较会排除大量数据,无需读取这些数据,整体而言,树的高度是几,则读取几次数据块,查询次数 会大大降低,查询效率会提高.

B+Tree
和BTree的区别 1
1. 叶子数据块之间用单向链表进行连接,为了提高区域范围内的数据查询效率
2. 在叶子数据块进行分裂提取时,提取出去的元素依然存在于原叶子数据块中;但是若从非叶子数据块进行分裂提取,此时 提取的数据不会再存在于原数据块中.保证最终查询的数据一定位于叶子数据块中.非叶子数据块存在的意义是作为目录存 在.
查询效率高: 整体查询的次数降低了,不会对所有元素都查询,而是每次比较之后,可以排除大量数据
树-- Tree
专业术语:
1. 根节点:每棵树中有且仅有一个根节点
2. 高度: 树的层次数
3. 度:树中所有节点的最大子节点数
4. 叶子节点:度为0的节点
索引的高度固定为3,则度会根据数据量进行适当的调整
注意:
将读取到的数据块缓存到内存上后 ,对内存中缓存的数据块中的数据进行读取,采用的是二分查找算法
索引的底层是B+Tree,但是索引对B+Tree进行了一些优化
索引使用B+Tree,在叶子数据块中保存的元素不是一个元素值,而是key-value
则索引中叶子数据块中的key-value分别保存什么?
索引的分类
1. 聚簇索引(聚集索引):给主键id添加的索引就叫做聚簇索引
2. 非聚簇索引(非聚集索引):给非主键字段添加的索引叫做非聚簇索引
Innodb的特点
从mysql5.5开始存储引擎换为Innodb,该存储引擎有以下的特点:
1. Innodb支持事务和行锁
2. 默认会给表的主键添加聚簇索引;若表中没有提供主键,此时Innodb会自动给表添加隐藏主键,类型为long,长 度为6,Innodb会给该主键添加聚簇索引
3. 除聚簇索引外,Innodb默认还会给添加了unique约束以及外键约束的字段添加索引.
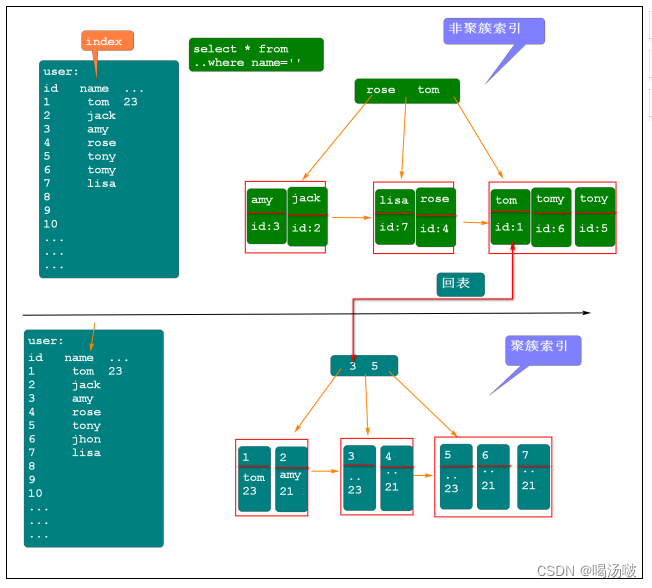
聚簇索引
聚簇索引是Innodb存储引擎默认添加的.无需我们添加
聚簇索引中的key和value分别保存什么?
key: 主键-id
value: 主键对应的行数据
聚簇索引中,根据id就可以直接找到对应的行数据
非聚簇索引
是需要我们添加的,其key和value分别为:
key:保存添加了索引的那列的值
value: 这行数据对应的id(主键)
非聚簇索引中,根据添加了索引的那列的值,可以快速的找到对应的id,此时再根据id到聚簇索引中,可以快速查询到 对应的行数据,这个操作叫做回表操作.
索引操作
1. 创建索引
create index index_name on table_name(col)
案例: 给字段添加unique约束,验证是否Innodb默认给添加了索引
添加unique约束
alter table t_name add col type unique;
create table t_name(id int primary key,name varchar(20) unique)
2. 查询索引
show index from table_name
3. 删除索引
drop index index_name on table_name
索引的适用场景
1. 表中的数据量大时,应该使用索引.表中数据量不大,不要使用索引,因为建立索引也是需要时间的.
2. 通常会给作为查询条件的字段添加索引
3. 当某字段的值会被频繁修改时,不要给该字段添加索引,因为每次修改都会改变元素的排序,从而导致索引重构, 耗费时间
4. 在一个表中,索引并不是越多越好,通常情况下,一个表中的索引不要超过6个
索引的失效场景
索引失效是指:因为一些不当操作,导致进行全表扫描,而不使用索引,这种情况我们叫做索引失效。
使用索引时sql语句要避免的情况:
1.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
where name is not null
2.应尽量避免在 where 子句中使用!=操作符,否则将引擎放弃使用索引而进行全表扫描
3.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描
where name=xx or name=xx or name=xx
4.not in 也要慎用,否则会导致全表扫描,in并不会导致索引失效
where ..not in(xx,xx,xx)
适用in 会不会适用索引? -- 会
5.尽量避免在where子句中对字段使用like左侧模糊查询(like '_%'),会导致全表扫描
where xx like '%xx' /like '_x'
6.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描
eg: select...from user where age+4>12
7.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
eg:select...from ...where round(score)=....
使用索引注意事项:
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要 超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
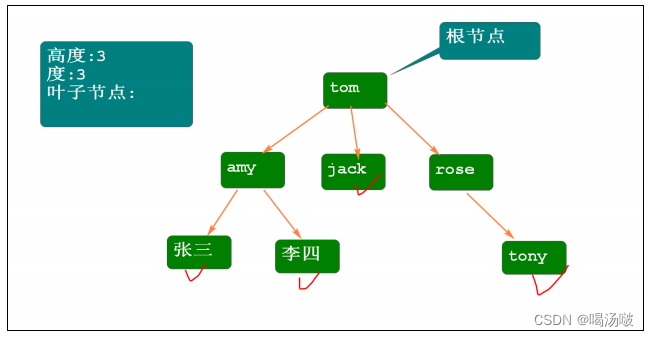
树 - tree
树是数据结构,由若干个节点构成,其中有且仅有一个根节点.
树的术语:
高度: 树的层次
根节点: 有且仅有一个
度: 树中节点的最大子节点数
叶子节点: 度为0的节点
二叉树:
度为2的树,则为二叉树
二叉排序树
定义:
二叉排序树(Binary Sort Tree),又称二叉查找树(Binary Search Tree),亦称二叉搜索树。是数据结 构中的一类。在一般情况下,查询效率比链表结构要高。
特点:
1. 元素不能重复
2. 左子树中的节点均小于根节点
3. 右子树中的节点均大于根节点
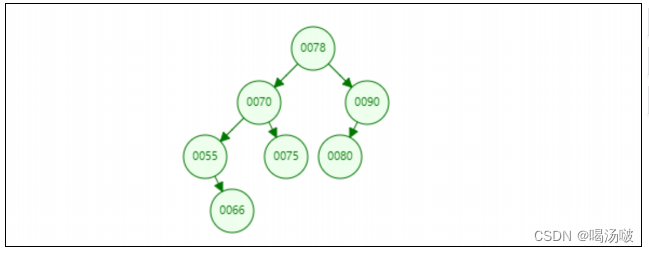
二叉排序树的查询效率高于单向链表
单向链表中,查询元素,最差的情况要查询n次;而在二叉排序树中,每次比较,均可以排除将近一半的数据,所以查询 次数会大大减少.查询效率高于单向链表
二叉排序树中的元素可以是其他引用类型,但是要求该引用类型的对象之间是可比较大小的,如何保证对象之间能
比大小?
实现Comparable接口,在类中定义比较规则,则对象之间是可比较大小的.
最后
以上就是不安眼睛最近收集整理的关于数据库/SQL优化&索引如何进行慢sql优化如何优化数据库?索引 – Index树 - tree的全部内容,更多相关数据库/SQL优化&索引如何进行慢sql优化如何优化数据库?索引内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复