你是否考虑分析和可视化地理数据? 为什么不尝试 Elastic Stack? 也就是所谓的 ELK(Elasticsearch + Logstash + Kibana)或Elatic Stack 不仅是NoSQL数据库。 它是一个整体系统,可以实时存储,搜索,分析和可视化来自任何来源的数据。 在这种情况下,我们将使用有关华沙公共交通位置的开放数据。
在今天的文章中,我将介绍如何使用 Elastic Stack 和 Kafka 来监控公共交通的车辆。我们将使用 Docker 来部署所有需要的组件。下面是整个系统的框架图:
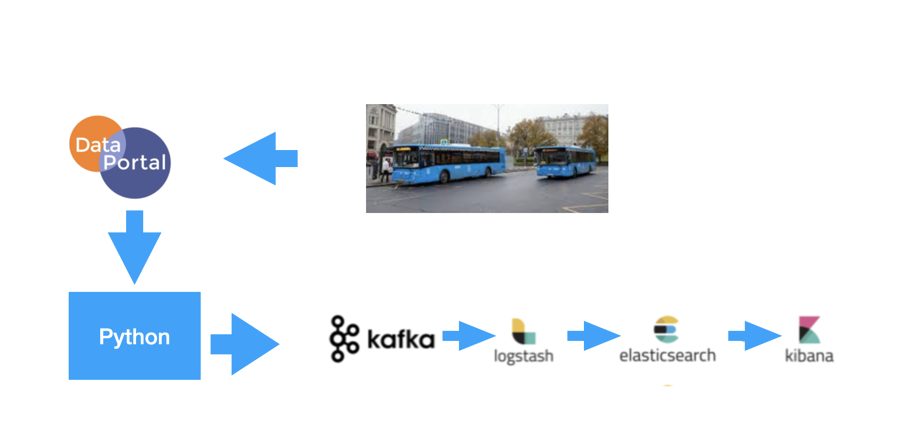
整个应用的框架如上:
- 汽车或公交的数据上传到一个数据平台。它提供 REST API 接口来被调用。
- Python 应用定时从 data portal 进行抓取数据,并同时发送到 Kafka
- Kafaka 的数据发送到 Logstash 进行加工,并导入到 Elasticsearch 中
- 在 Kibana 中对数据进行呈现,展示
安装
Python
我们有一个应用是用 python 语言写的。你需要安装 python3 来运行该应用。
API key
为了测试这个应用,我们必须得到相应的华沙公共交通信息的 API key。我们可以在地址 https://api.um.warszawa.pl/# 进行申请。由于是我们不懂的文字,需要翻译中文才可以了:
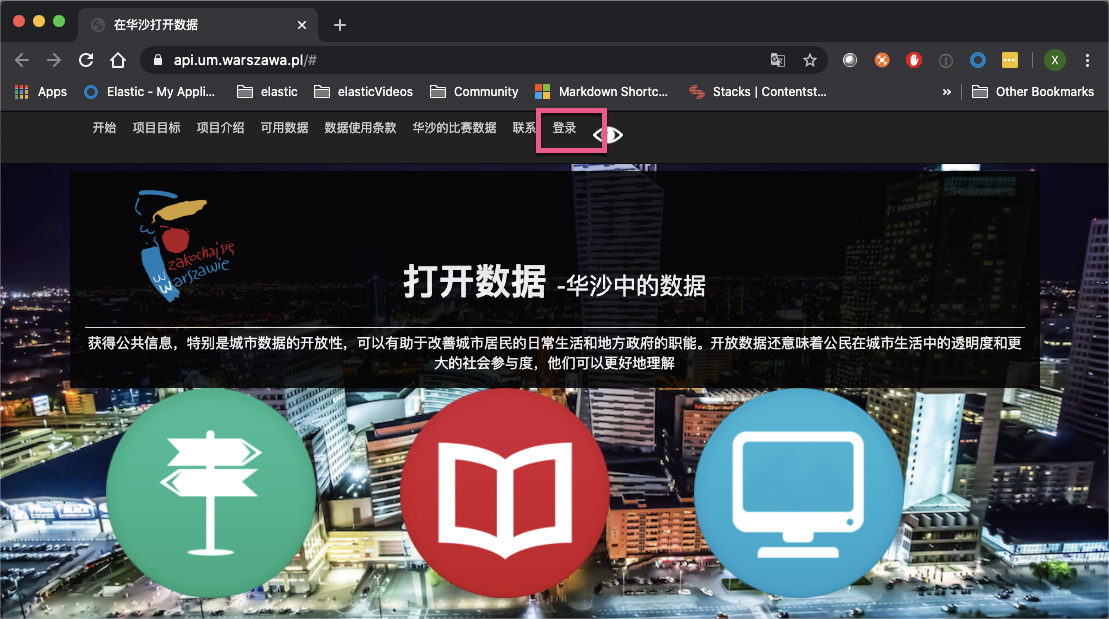
点击上面的 “登录” 链接,并进行脑力测试:
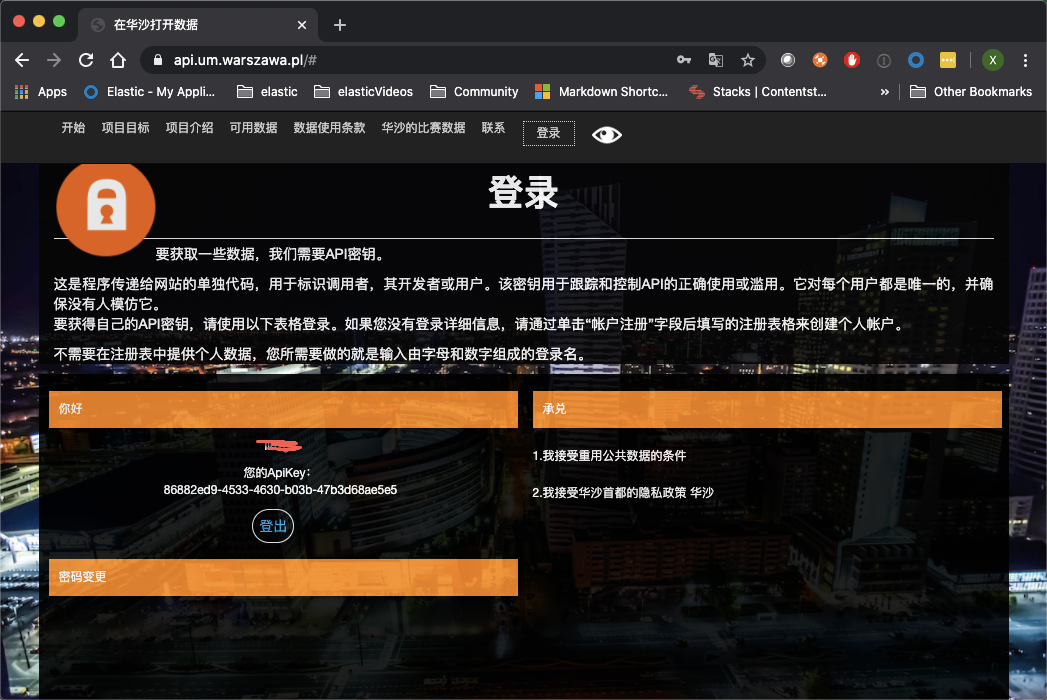
最终得到如上所示的 API key:86882ed9-4533-4630-b03b-47b3d68ae5e5。这个 key 将在一下的 python 应用中使用。
Elastic Stack 及 Kafka
你需要安装 Docker 来实现 Elastic Stack 及 Kafka 的安装。
本展示的所有的源码可以在地址 https://github.com/liu-xiao-guo/wiadro-danych-kafka-to-es-ztm 进行下载。
docker-compose 包含 Elasticsearch,Kibana,Zookeeper,Kafka,Logstash 和应用程序 Kafka Streams (由于一些原因,在本展示中将不被采用)。
docker-compose.yml
version: '3.3'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.7.0
restart: unless-stopped
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata:/usr/share/elasticsearch/data
ports:
- 9200:9200
kibana:
image: docker.elastic.co/kibana/kibana:7.7.0
restart: unless-stopped
depends_on:
- elasticsearch
ports:
- 5601:5601
volumes:
- kibanadata:/usr/share/kibana/data
zookeeper:
image: 'bitnami/zookeeper:3'
ports:
- '2181:2181'
volumes:
- 'zookeeper_data:/bitnami'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: 'bitnami/kafka:2'
ports:
- '9092:9092'
- '29092:29092'
volumes:
- 'kafka_data:/bitnami'
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,PLAINTEXT_HOST://:29092
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
depends_on:
- zookeeper
ztm_kafka_streams:
image: "maciejszymczyk/ztm_stream:1.0"
environment:
- APPLICATION_ID_CONFIG=awesome_overrided_ztm_stream_app_id
- BOOTSTRAP_SERVERS_CONFIG=kafka:9092
depends_on:
- kafka
logstash:
image: docker.elastic.co/logstash/logstash:7.7.0
volumes:
- "./pipeline:/usr/share/logstash/pipeline"
environment:
LS_JAVA_OPTS: "-Xmx256m -Xms256m"
depends_on:
- elasticsearch
- kafka
volumes:
esdata:
driver: local
kibanadata:
driver: local
zookeeper_data:
driver: local
kafka_data:
driver: local
我们在自己电脑的 console 中打入如下的命令:
docker-compose up我们可以看到如下的画面:
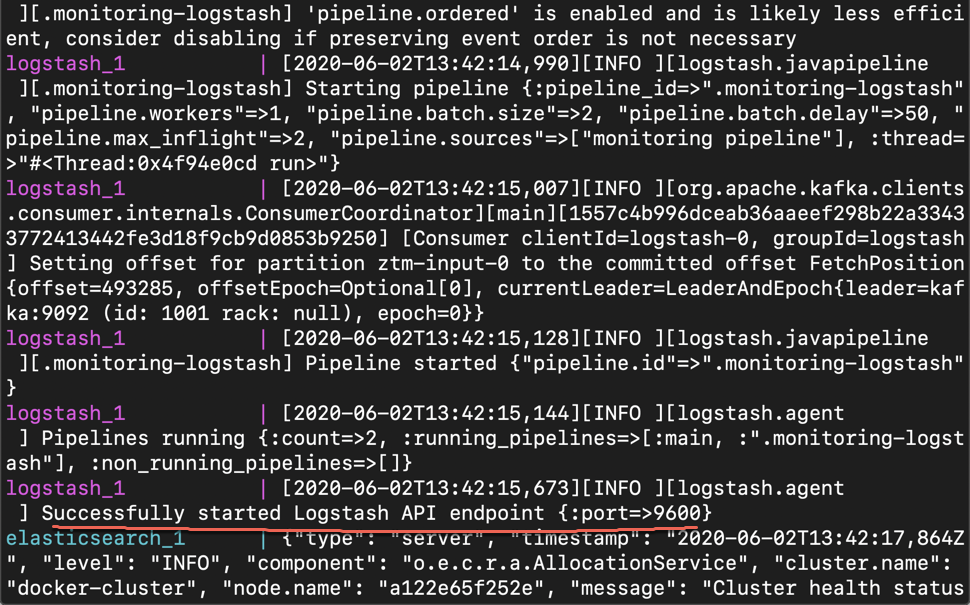
从上面我们可以看出来 Logstash 已经被成功地启动。
我们在浏览器的地址栏中输入地址 http://localhost:5601
我们可以看到 Kibana 已经成功启动,这也意味着 Elasticsearch 被成功地运行起来了。
配置及运行
Logstash
我们使用如下的 pipeline 来实现对数据的处理:
pipeline/kafka_to_es.conf
input {
kafka {
topics => "ztm-input"
bootstrap_servers => "kafka:9092"
codec => "json"
}
}
filter {
mutate {
convert => {"Lat" => "float"}
convert => {"Lon" => "float"}
add_field => ["location", "%{Lat},%{Lon}"]
remove_field => ["Lat", "Lon"]
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "ztm"
}
}它从 Kafaka 的 "ztm-input" topic 获取数据,并把相应的 Lat 及 Lon 字段合并成为一个 location 字段。在 output 的部分,我们把数据导入到 Elasticsearch 之中。
Elasticsearch
我们使用了索引生命周期管理机制, 而不是将记录放入诸如ztm-2020.05.24之类的索引中。 它使你可以自动执行索引的寿命。 它会自动进行汇总,并根据你配置策略的方式更改索引属性(热-热-冷架构)。 假设我希望在索引达到1GB或30天过去后进行 rollover,我们在 Kibana 中执行如下的命令:
PUT _ilm/policy/ztm_policy
{
"policy": {
"phases": {
"hot":{
"actions": {
"rollover": {
"max_size": "1gb",
"max_age": "30d"
}
}
}
}
}
}你还需要一个模板,该模板具有 ztm_policy 将连接到的适当 mapping。 如果没有 mapping,Elasticsearch 将不会猜测到 location 字段为 geo_point 的数据类型,并且时间字段将是纯文本。
PUT _template/ztm_template
{
"index_patterns": ["ztm-*"],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name":"ztm_policy",
"index.lifecycle.rollover_alias": "ztm"
},
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"bearing": {
"type": "float"
},
"brigade": {
"type": "keyword"
},
"distance": {
"type": "float"
},
"lines": {
"type": "keyword"
},
"location": {
"type": "geo_point"
},
"speed": {
"type": "float"
},
"time": {
"type": "date",
"format":"MMM dd, yyyy K:mm:ss a"
},
"vehicleNumber": {
"type": "keyword"
}
}
}
}现在该使用适当的别名创建第一个索引了。
PUT ztm-000001
{
"aliases": {
"ztm": {
"is_write_index":true
}
}
}我们在 Kibana 中运行上面的三个命令。
Python 脚本
首先,我们必须获得所需要的 API key。这个在上面我们已经讲述了。
ztm.py
import requests
import json
import time
from kafka import KafkaProducer
token = '86882ed9-4533-4630-b03b-47b3d68ae5e5'
url = 'https://api.um.warszawa.pl/api/action/busestrams_get/'
resource_id = 'f2e5503e927d-4ad3-9500-4ab9e55deb59'
sleep_time = 15
bus_params = {
'apikey':token,
'type':1,
'resource_id': resource_id
}
tram_params = {
'apikey':token,
'type':2,
'resource_id': resource_id
}
while True:
try:
r = requests.get(url = url, params = bus_params)
data = r.json()
producer = KafkaProducer(bootstrap_servers=['localhost:29092'],
value_serializer=lambda x: json.dumps(x).encode('utf-8'),
key_serializer=lambda x: x
)
print('Sending records...')
for record in data['result']:
print(record)
future = producer.send('ztm-input', value=record, key=record["VehicleNumber"].encode('utf-8'))
result = future.get(timeout=60)
except:
print("¯_(ツ)_/¯")
time.sleep(sleep_time)
上面的代码其实是蛮简单的。它定时从 API portal 获取公交系统的位置信息,并转发到 Kafka。
我们使用如下的命令来运行上面的应用:
python3 ztm.py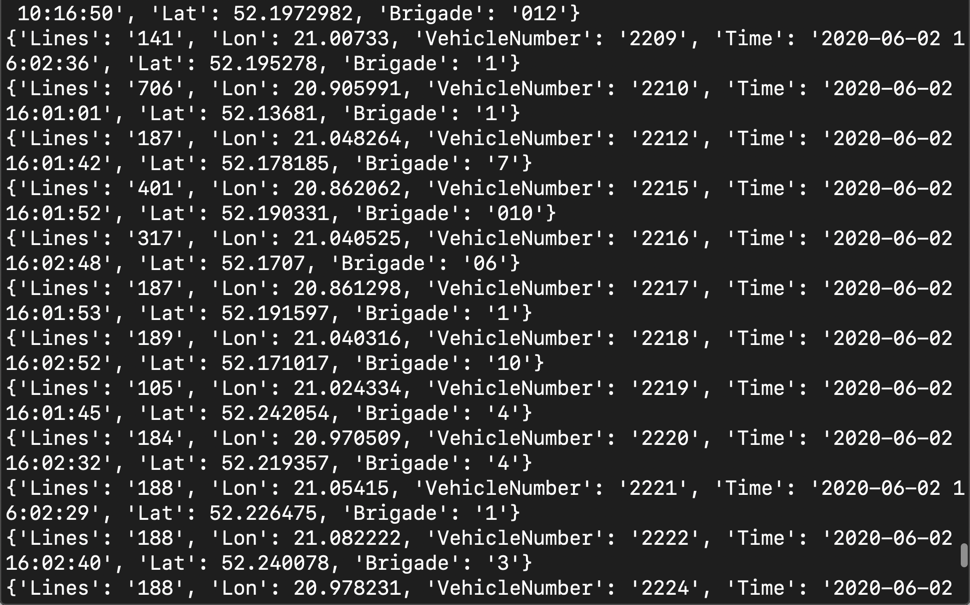
这个时候,我们可以在屏幕上看到所获得很多的关于公交系统车辆的信息。
我们可以转到运行 docker-compopse up 命令的那个 console,我们可以看到如下的信息:
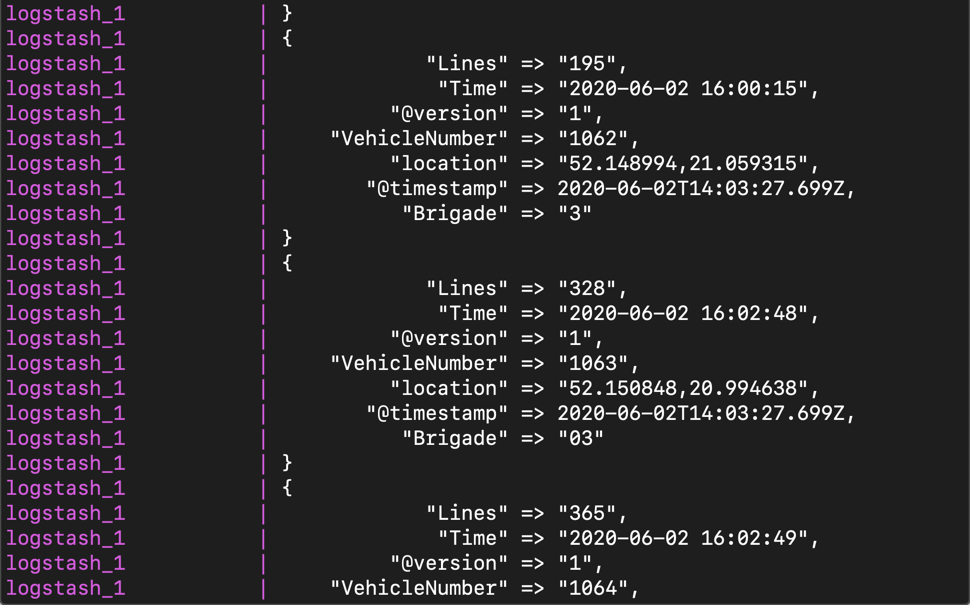
它表明我们的 Logstash 是在正常工作。
在 Kibana 中展示
打开 Kibana,并使用如下的命令:
GET _cat/indices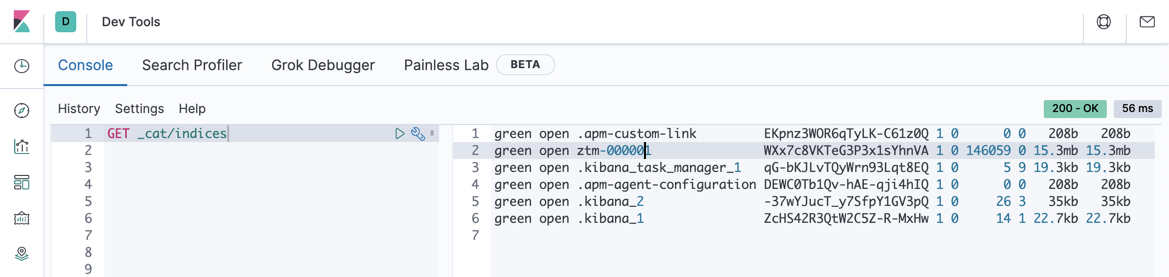
从上面,我们可以看到一个叫做 ztm-000001 的索引,并且它里面含有已经收集上来的车辆信息。
为了分析这个索引,我们必须创建一个 index pattern:
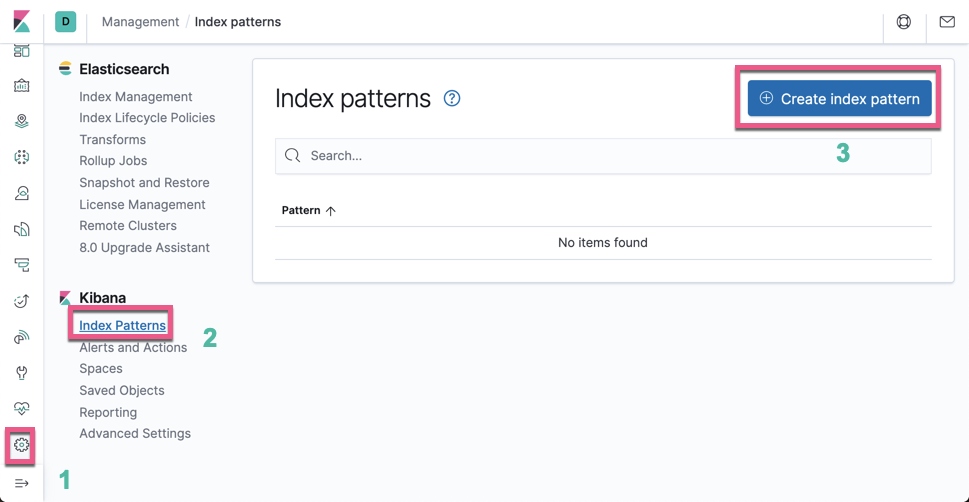
点击 Create index pattern:
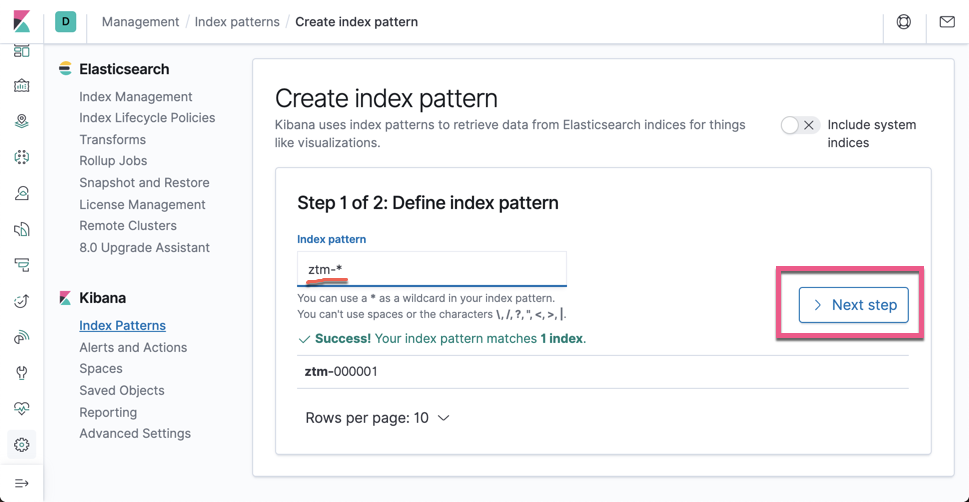
点击 Next step:
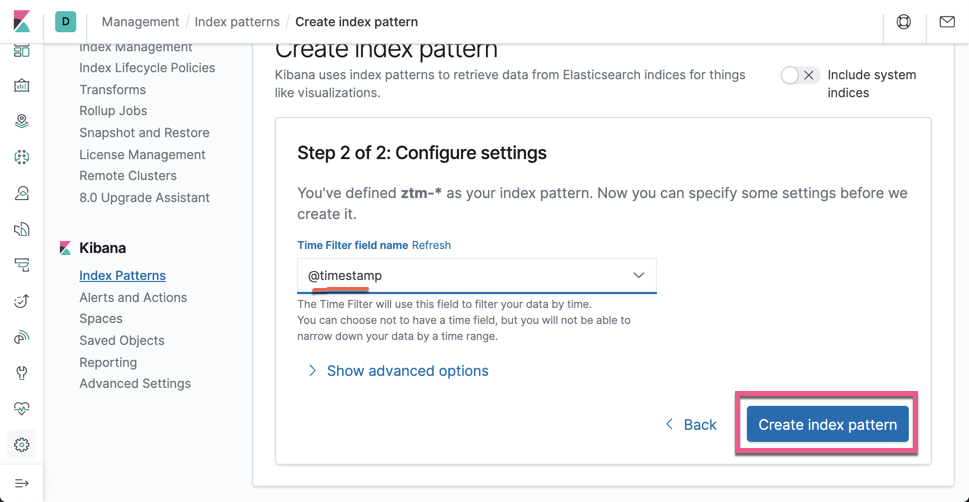
点击上面的 Create index pattern 按钮。这样就完成了创建 index pattern。
为了对数据可视化,我们点击 Visualization:
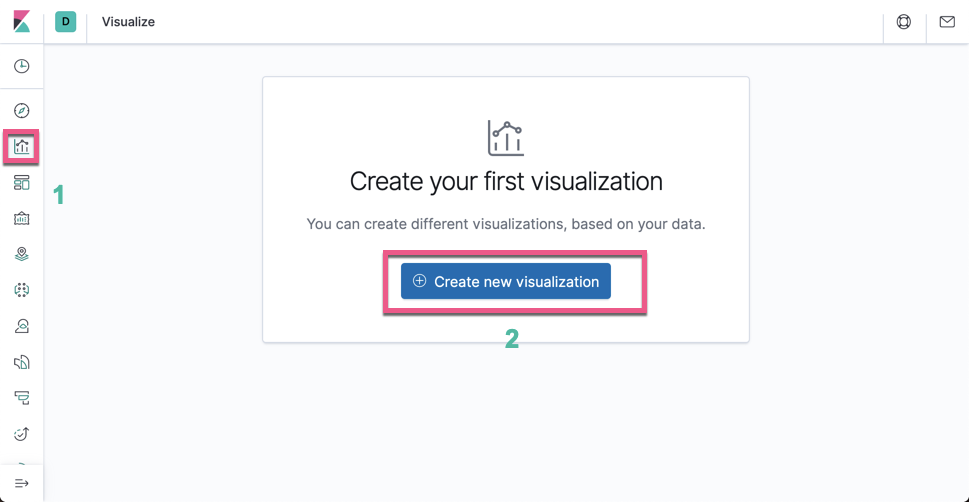
点击上面的 Create new visualization:
点击 Maps:
点击 Add layer:
点击 Documents:
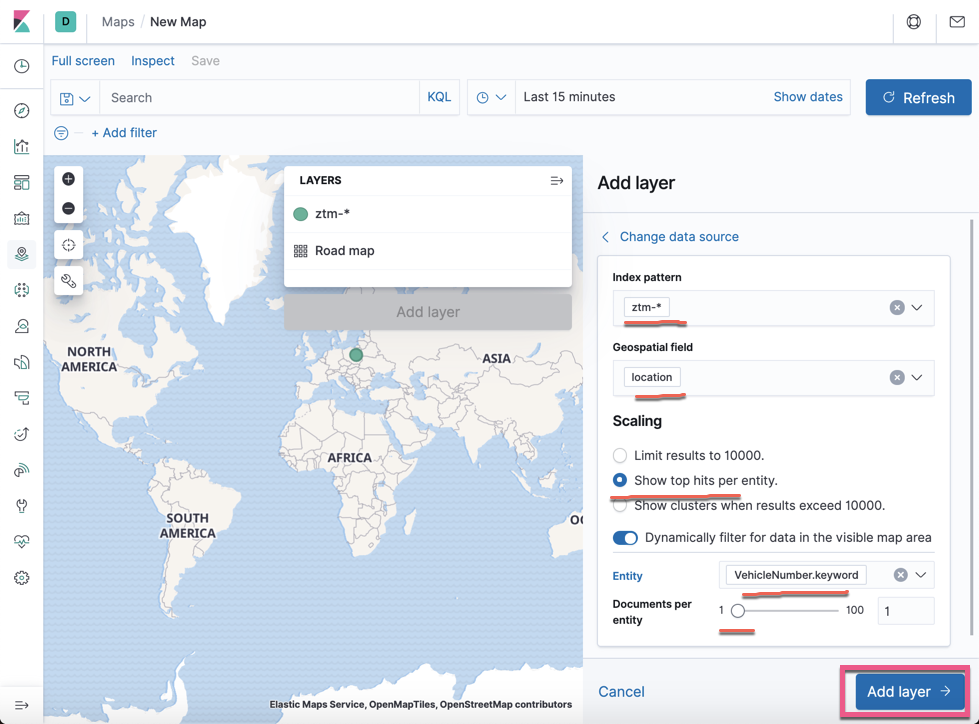
点击 Add layer:
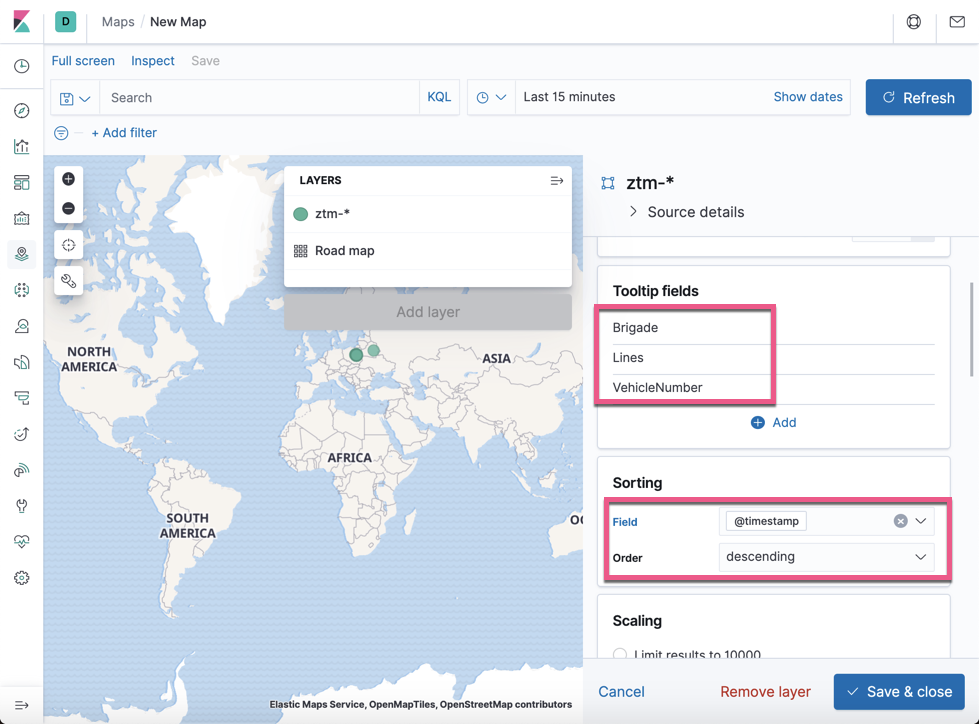
向下滚动:
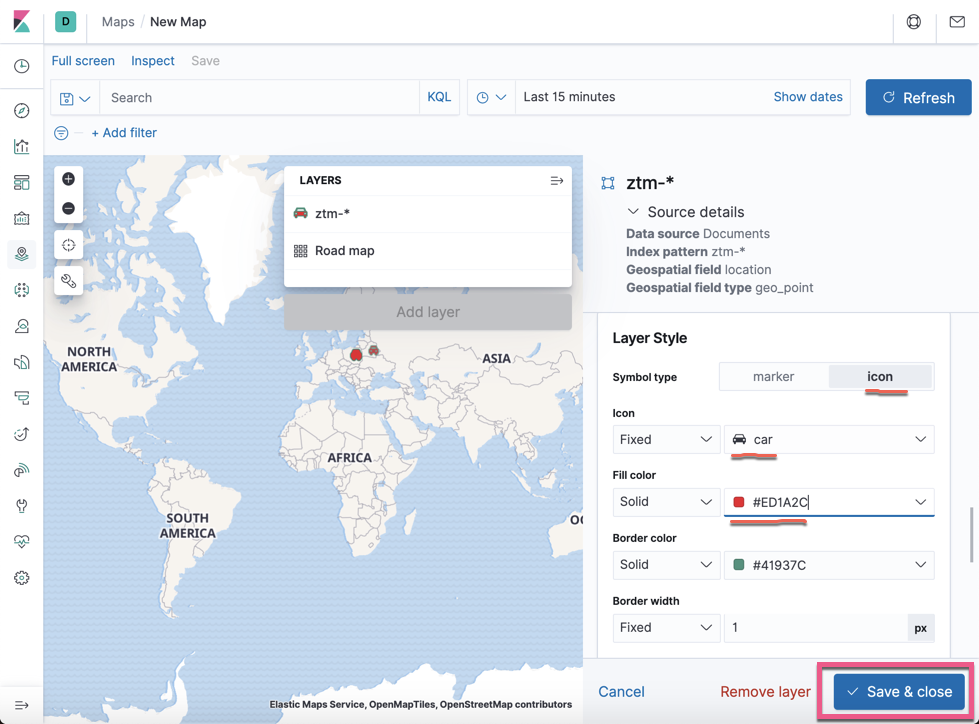
点击上面的 Save & close 按钮:
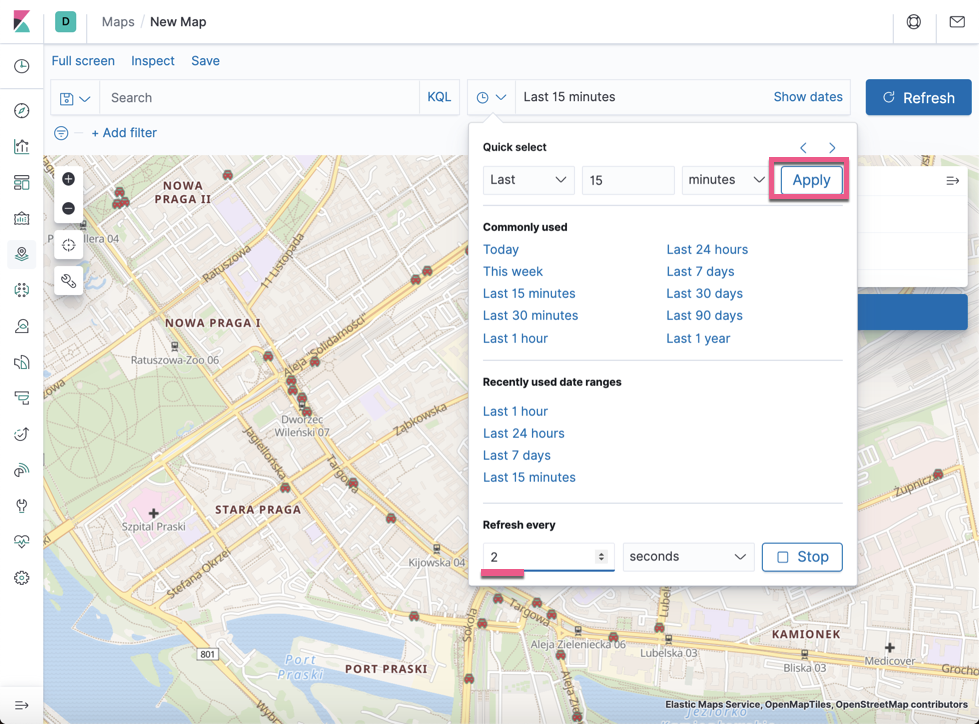
在上面,我们配置每隔2秒自动获取数据。点击 Apply 按钮。
我们聚焦华沙地区:
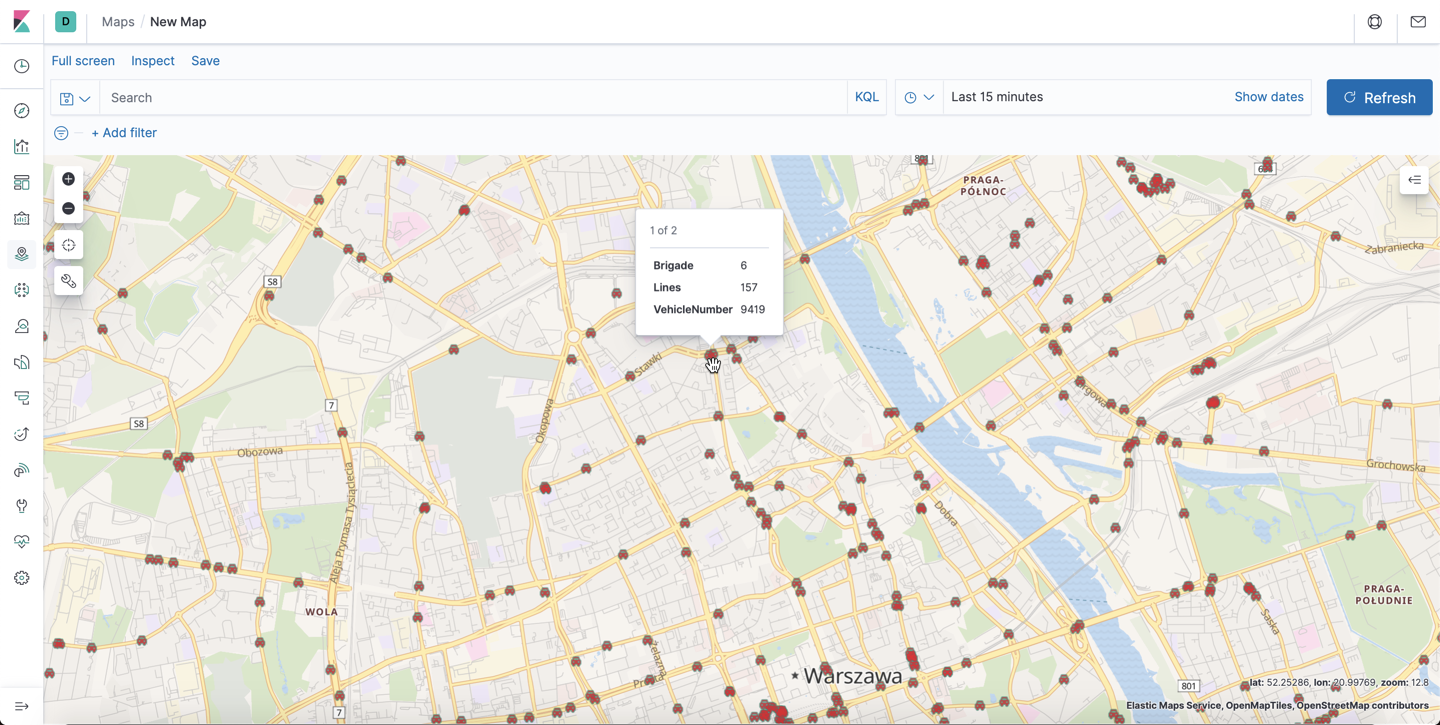
这样在地图上,我们可以清楚地看到每个车辆的运行情况。
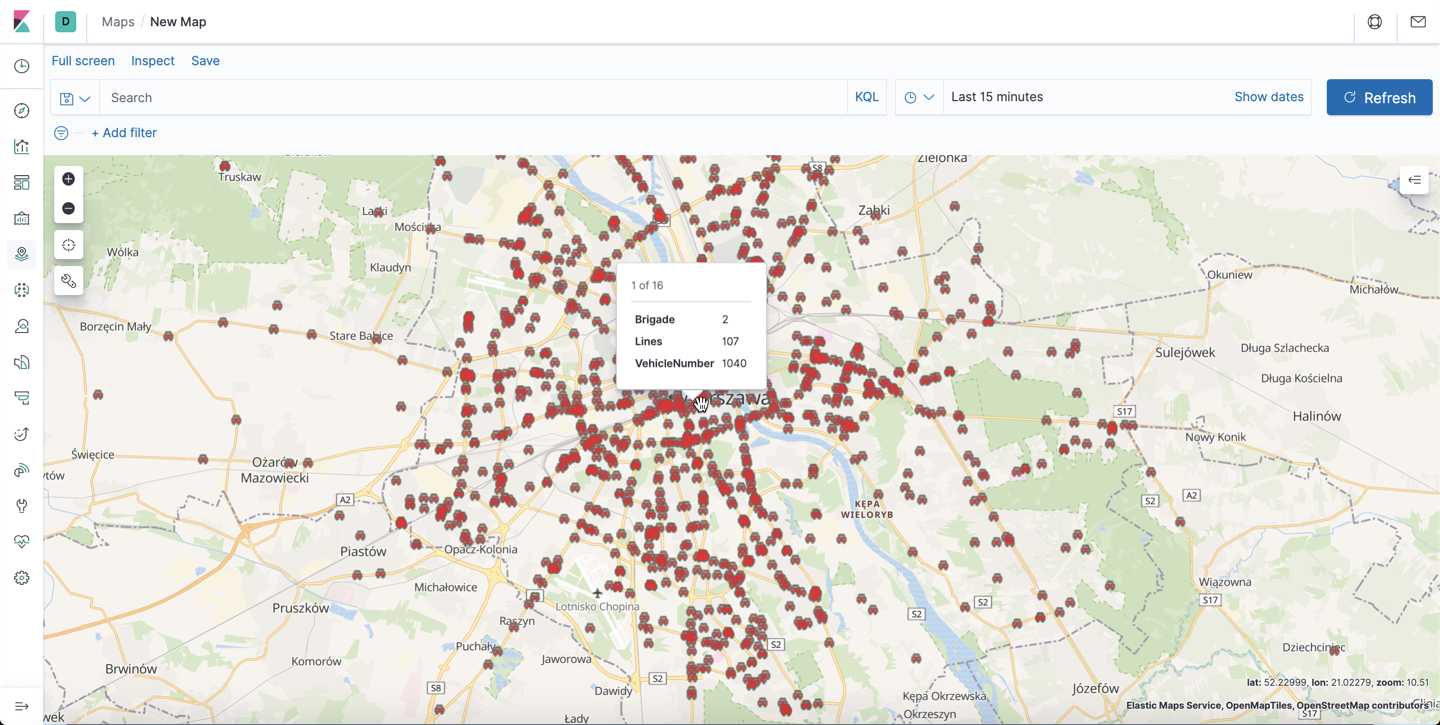
我们甚至可以针对一个 Brigade 进行搜索:
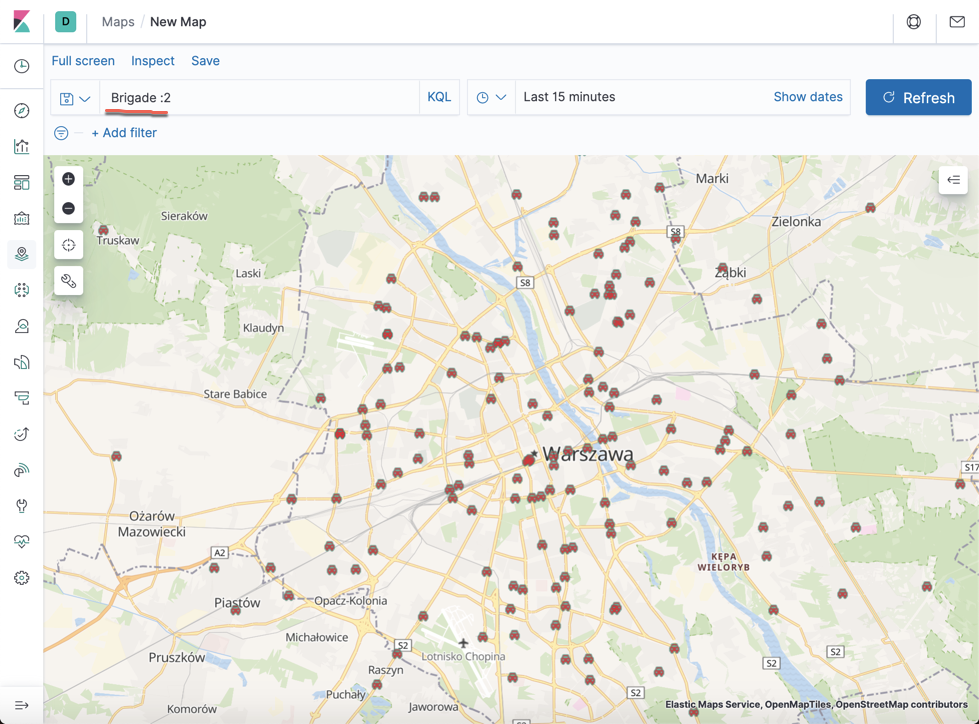
参考:
【1】https://medium.com/@zorteran/how-to-visualize-public-transport-using-kibana-elasticserach-logstash-elastic-stack-and-kafka-eabc6975255a
最后
以上就是淡淡微笑最近收集整理的关于Observability:如何在 Docker 之上使用 Elastic Stack 和 Kafka 可视化公共交通安装配置及运行在 Kibana 中展示的全部内容,更多相关Observability:如何在内容请搜索靠谱客的其他文章。








发表评论 取消回复