引言
6.824不愧为神课,这样的教学方式才是真正做到提升学生兴趣与水平的好课啊!试问能有多少个学校的课程设计中有这样高质量的实验,对比本校的所有计算机课程,一年一个TTMS,又或者是无意义的上机敲个几百行学习语言的代码,太真实了呀。。实在是一年的实验不及人家一学期一门课的实验来的有趣,来的有用。的要怪就怪自己当初没有好好学习了。牢骚发完了,开始正题部分吧。

Introduction
这个实验的主题内容就是实现一个MapReduce库,当然没有那么狠心,直接一上来撸一个分布式框架,我们要做的就是去在已有的框架上去填几个函数,深刻的理解MapReduce的工作原理。在一二部分我们会以串行为前提,写一个Map、Reduce的逻辑处理部分和一个wordCount的小demo,后面我们将以并行为前提实现分配任务,容错部分和一个简单的倒排索引。在完成此实验前最好看过MapReduce的论文。
在进行正式的编码之前我们可以简单的了解下测试的原理,这样更有助于我们去完成实验。
在我们测试代码的时候我们会执行以下语句:
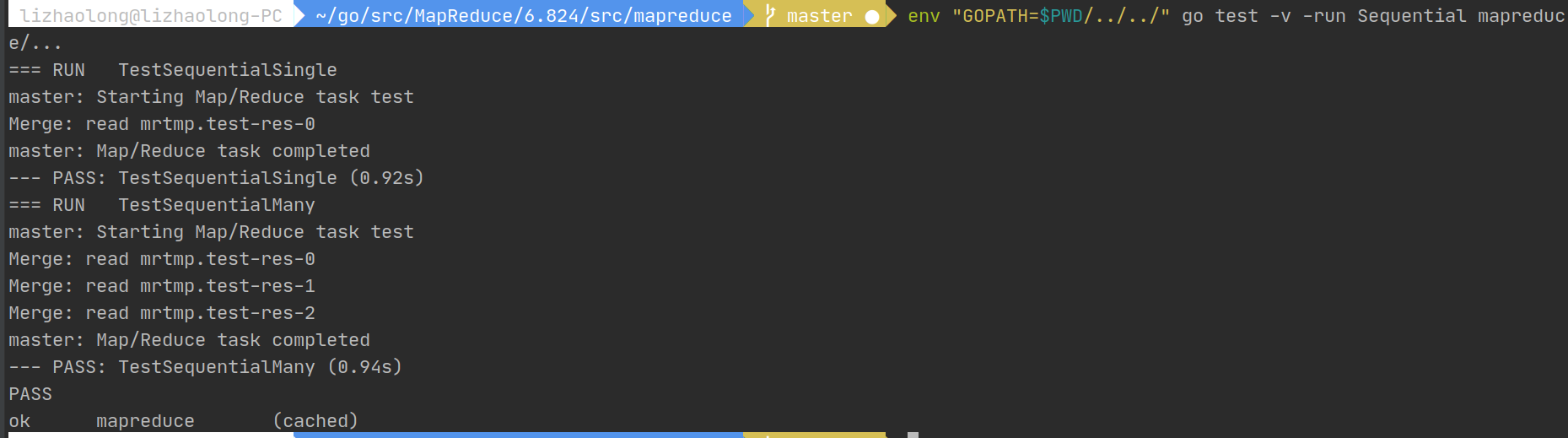
go test -run Sequential mapreduce/…
这里根据run后面的参数不同会调用不同的函数,即TestSequentialSingle和TestSequentialMany函数,因为一二部分为串行,所以我们使用TestSequentialSingle举例子
func TestSequentialSingle(t *testing.T) {
mr := Sequential("test", makeInputs(1), 1, MapFunc, ReduceFunc)
mr.Wait()
check(t, mr.files)
checkWorker(t, mr.stats)
cleanup(mr)
}
func Sequential(jobName string, files []string, nreduce int,
mapF func(string, string) []KeyValue,
reduceF func(string, []string) string,
) (mr *Master) {
mr = newMaster("master")
go mr.run(jobName, files, nreduce, func(phase jobPhase) {
switch phase {
case mapPhase:
for i, f := range mr.files {
doMap(mr.jobName, i, f, mr.nReduce, mapF) //mapF就相当于是用户写的
}
case reducePhase:
for i := 0; i < mr.nReduce; i++ {
doReduce(mr.jobName, i, len(mr.files), reduceF)
}
}
}, func() {
mr.stats = []int{len(files) + nreduce}
})
return
}
我们可以看到在Sequential中首先创建了一个master实例,然后就开启了一个go routine,执行run函数,值得一提的是run的后两个参数是func类型,这里使用了两个匿名函数,这也是和并行不一样的地方。我们可以看出run其实就是处理的重点函数,我们来看看吧
func (mr *Master) run(jobName string, files []string, nreduce int,
schedule func(phase jobPhase),
finish func(),
) {
mr.jobName = jobName //给master填充状态
mr.files = files
mr.nReduce = nreduce
fmt.Printf("%s: Starting Map/Reduce task %sn", mr.address, mr.jobName)
schedule(mapPhase) // 使用回调处理 执行 map
schedule(reducePhase) // 执行reduce
finish()
mr.merge() //合并reduce的输出
fmt.Printf("%s: Map/Reduce task completedn", mr.address)
mr.doneChannel <- true
}
我们可以看到处理的逻辑其实就是启动一个go routine,这就是一个MapReduce任务,然后先执行Map,当然执行输入的文件数个,也就是len( mr.files),每一个map会输出nreduce个文件存储在本地,然后每个reduce会从这些Map处取走属于自己的那个分区,然后执行合并。我们的任务就是补充doMap和doReduce。
part I
上面已经说了我们的任务是补充doMap和doReduce,它们分属于common_map.go和common_reduce.go中,只需要填写它们即可,值得一提的是注释中提示我们最好使用json格式,还好Go自带json的编码解码。
处理的逻辑是这样的,我们在doMap中可以得到一个string类型的内容字段,也就是inFile,我们需要把这个inFile分成nReduce份,划分的过程这里使用了哈希分区的方法(framework自带),当然实际中可以使用基于关键字的分区。然后的一点就是使用提供的reduceName生成对应的文件名,其中存储json类型的key-value,这个key-value有用户提供的mapF函数实现,这样看来其实我们也不用做什么,就是把mapF的返回值写入指定的文件中即可
func doMap(
jobName string, // the name of the MapReduce job
mapTaskNumber int, // which map task this is
inFile string, // 实际就是文件的内容
nReduce int, // the number of reduce task that will be run ("R" in the paper)
mapF func(file string, contents string) []KeyValue,
) {
inputfile, err := os.Open(inFile)
if err != nil {
log.Fatal("doMap: open file error", inFile, "error:", err)
}
defer inputfile.Close()
// 打开文件以后我们需要依据内容把其划分为nReduce份
fileInfo, err := inputfile.Stat() // 我们需要知道文件的大小
if err != nil {
log.Fatal("doMap: get state fail", inFile, "error:", err)
}
Content := make([]byte, fileInfo.Size()) //接收文件
ReadBytes, err := inputfile.Read(Content)
if err != nil {
log.Fatal("doMap: Read file error", inFile, "error:", err)
} else if int64(ReadBytes) != fileInfo.Size() {
log.Fatal("doMap: Read file error, don`t have enough bytes", inFile, "error:", err)
}
keyValues := mapF(inFile, string(Content)) // 调用用户编写的Map/Reduce函数 返回一个变长数组
for i := 0; i < nReduce; i++ {
filename := reduceName(jobName, mapTaskNumber, i) // 获取存储的文件
reduceFile, err := os.Create(filename) // 打开或者创建
if err != nil {
log.Fatal("doMap: create intermediate file ", filename, " error: ", err)
}
defer reduceFile.Close() // 在一个循环里面可以完成一个文件的写入
enc := json.NewEncoder(reduceFile) // 使用json格式写入
for _, kv := range keyValues {
if ihash(kv.Key)%uint32(nReduce) == uint32(i) { // 查找要存到第N个reduce文件中的键值对
err := enc.Encode(&kv)
if err != nil {
log.Fatal("doMap: encode error:", err)
}
}
}
}
}
doReduce所做的事情其实和doMap类似,就是读取doMap提供的文件,这里framework提供了reduceName。然后我们把其中的值排序,执行用户提供的reduceF,最后写入最后的文件即可,文件名由mergeName提供。这里排序我个人认为不是必要的,虽然同一分区的键值对来自于不同的Map,也就是不同的机器,我们完全可以扫一遍数据,使得所有相同key的键值对都以key->value[]的格式存下来,而reduceF接收的参数又是(key string, values []string),所以对于reduceF,也就是用户编写的reduce来说无论是否有序都可以(不绝对),除非所有的key之间处理的过程有联系,否则这里的排序其实并不是必要的。
func doReduce(
jobName string, // the name of the whole MapReduce job
reduceTaskNumber int, // which reduce task this is
nMap int, // the number of map tasks that were run ("M" in the paper)
reduceF func(key string, values []string) string,
) {
KeyValues := make(map[string][]string, 0)
// 其实这里得到的是所有map的一个分区的key
// 每一次执行这个函数的作用就是把所有map的一个分区合并到一起
// 这样reduce执行完毕以后我们就有了nmap个合并后的文件分布在不同的reduce worker上
// 最后只需要执行一次合并就可以了
for i := 0; i < nMap; i++ {
filename := reduceName(jobName, i, reduceTaskNumber) //获取当前reduce的输入文件 也就是map中写入的文件
file, err := os.Open(filename)
if err != nil {
log.Fatal("doReduce: open file error ", filename, "error", err)
}
defer file.Close()
dec := json.NewDecoder(file)
for {
var kv KeyValue
err := dec.Decode(&kv)
if err != nil {
break //解析完毕
}
_, ok := KeyValues[kv.Key] //在map中是靠哈希分开的,所以同一个文件中的key是不一样的,且相同的key可能存在不同的value
if !ok { //不存在的话
KeyValues[kv.Key] = make([]string, 0)
}
KeyValues[kv.Key] = append(KeyValues[kv.Key], kv.Value)
}
}
var keys []string
for k, _ := range KeyValues {
keys = append(keys, k)
}
sort.Strings(keys) // 给所有的key排序 如果go的map天然有序就不用排了
mergeFileName := mergeName(jobName, reduceTaskNumber) // 根据提示 我们可以得到最后合并的文件的名称
mergeFile, err := os.Create(mergeFileName)
if err != nil {
log.Fatal("doReduce: create merge file error ", mergeFileName, " error: ", err)
}
defer mergeFile.Close()
enc := json.NewEncoder(mergeFile) //以json格式写入最终文件
for _, k := range keys { // 顺序处理所有的key
res := reduceF(k, KeyValues[k])
err := enc.Encode(&KeyValue{k, res})
if err != nil {
log.Fatal("doReduce: encode error")
}
}
}
然后就OK啦。
part II
这一部分我们需要写一个map/reduce函数,题目是经典的wordCount(论文中的例子),路径在main/wc.go,我们需要补充mapF和reduceF,其实这个处理过程有一点问题,就是接口的限制很大,mapF默认传入的是文件名和文件内容,需要我们返回键值对,这个键值对我们该如何设计呢?这里使用论文中的方法,就是key为word,value为一个固定字符
func mapF(document string, value string) (res []mapreduce.KeyValue) {
// TODO: you have to write this function
results := strings.FieldsFunc(value, func(ch rune) bool{return !unicode.IsLetter(ch)})
for _,v := range results{
res = append(res, mapreduce.KeyValue{v, "1"})
}
return
}
// The reduce function is called once for each key generated by Map, with a
// list of that key's string value (merged across all inputs). The return value
// should be a single output value for that key.
func reduceF(key string, values []string) string {
// TODO: you also have to write this function
var res int
/*var sum int
for _,v := range values{
count, err := strconv.Atoi(v)
if err != nil {
log.Fatal("reduceF: strconv string to int error: ", err)
}
sum += count
}*/
res = len(values) //注释掉上面会导致没有使用log包 去掉import里的log就可以了
/*
* 其实这里我们直接加上values的length就可以了 因为在map中我们给每一个单词的键值对是
* key:单词 value: "1" 所以在doReduce会传入键和所有对应的value
* 这个时候我们直接加上长度就可以了
*/
return strconv.Itoa(res)
}
part III
这个部分虽然只是去填充schedule函数但其实并不太好写,串行阶段的实现非常简单,就只需要两个循环就可以了,
func(phase jobPhase) {
switch phase {
case mapPhase:
for i, f := range mr.files {
doMap(mr.jobName, i, f, mr.nReduce, mapF) //mapF就相当于是用户写的
}
case reducePhase:
for i := 0; i < mr.nReduce; i++ {
doReduce(mr.jobName, i, len(mr.files), reduceF)
}
}
}
但是并行就没那么简单了,值得注意的是类似于上面函数的调用部分不需要我们来写,我们只需要对Worker.DoTask进行一个RPC即可完成调用,所以这一部分的实现我们只需要填充call的参数即可,因为这些参数都是已知的,所以没什么问题。问题的关键在于Worker的注册,因为我们所写的地方是master,master需要调度哪一些worker来执行此次任务,这里的调度策略就是从mr.registerChannel中读取,因为registerChannel不是缓冲channel,所以我们的写入和读取都是阻塞的,我们都需要创建goroutine来执行。尤其是当这个worker完成任务以后我们应该执行一个goroutine把这个worker放入registerChannel中,一次复用worker。
func (mr *Master) schedule(phase jobPhase) {
var ntasks int
var nios int // number of inputs (for reduce) or outputs (for map)
switch phase {
case mapPhase:
ntasks = len(mr.files) // 有几个输入文件
nios = mr.nReduce // 几个输出文件
case reducePhase:
ntasks = mr.nReduce // 输入文件 也就是map的输出
nios = len(mr.files)
}
fmt.Printf("Schedule: %v %v tasks (%d I/Os)n", ntasks, phase, nios)
var wg sync.WaitGroup
for i := 0;i<ntasks;i++{
wg.Add(1)
go func(taskNumber int, nios int, phase jobPhase){
defer wg.Done()
for{
var args DoTaskArgs //需要使用这个参数进行RPC通信
// 可以想象成一个就绪队列 代表master可以调度的worker的名称
worker := <-mr.registerChannel //查看注册信息 这也是我们的工作之一
//当一个worker启动时,它会给master发送Register RPC
args.File = mr.files[taskNumber] //文件名
args.JobName = mr.jobName //job名
args.NumOtherPhase = nios //输出的文件数 见串行执行的doMap第四个参数和doRecuce的第三个参数
args.TaskNumber = taskNumber //第几个任务
args.Phase = phase //到底执行map还是reduce
//worker其实是一个服务器的名称
ok := call(worker, "Worker.DoTask", &args, new(struct{}))
if ok {
go func() {
// 任务执行完毕 再放回worker
mr.registerChannel <- worker
}()
// 这里跑一个goroutine是必要的 因为channel不是缓冲channel,写入没有读取的话会阻塞,我们不能使得阻塞主线程
break
}
}
}(i, nios, phase)
}
wg.Wait() //ntasks个任务全部完成以后退出
fmt.Printf("Schedule: %v phase donen", phase)
}

part IV
上面我们假设worker不会出现错误,在part IV中worker可能出现错误,这里我们把worker的失败当做RPC的失败即可。有一点其实值得一提,就是一个RPC的失败并不一定就意味着worker失败,也许worker只是现在不可达,这意味着可能发生两个worker接受到同样的任务然后进行计算,但是我们不必担心,因为我们的任务函数是幂等的,就算出现这样的情况也没有关系。且题目要求还告诉我们:测试永远不会在任务的中间失败,所以你根本不需要担心一些workers输入到同一个文件。还有题目也告诉我们忽略master错误。
其实代码部分就是part III的代码,其中的容错其实就是内部的for循环,当RPC失败的时候我们在registerChannel中重新拿一个worker出来即可,且题目告诉我们忽略一些workers输入到同一个文件,所以当出现错误的时候重新分配就可以了。

part V
这部分看上去很难,反向索引,还是选做的,实则非常简单,个人认为是除了partII以外最简单的一个,其实就是让我们计算每个单词出现的文件有哪些,然后以如下格式输出:
A: 16 pg-being_ernest.txt,pg-dorian_gray.txt,pg-dracula.txt,pg-emma.txt,pg-frankenstein.txt,pg-great_expectations.txt,pg-grimm.txt,pg-huckleberry_finn.txt,pg-les_miserables.txt,pg-metamorphosis.txt,pg-moby_dick.txt,pg-sherlock_holmes.txt,pg-tale_of_two_cities.txt,pg-tom_sawyer.txt,pg-ulysses.txt,pg-war_and_peace.txt
ABC: 2 pg-les_miserables.txt,pg-war_and_peace.txt
ABOUT: 2 pg-moby_dick.txt,pg-tom_sawyer.txt
ABRAHAM: 1 pg-dracula.txt
ABSOLUTE: 1 pg-les_miserables.txt
就是这个格式,[key] [:] [value number][each entry],然后用,隔开就可以了,这里有一个坑点,就是前两项是我们不需要操作的,我们只需要输出后面的数字和内容即可,因为这个failed了一次。有一点值得注意,因为这map中并没有做去重处理,所以在reduce中会有很多的重复,我们需要进行一次去重和排序。下面是实现:
func mapF(document string, value string) (res []mapreduce.KeyValue) {
// TODO: you should complete this to do the inverted index challenge
results := strings.FieldsFunc(value, func(ch rune) bool{return !unicode.IsLetter(ch)})
for _,v := range results{
res = append(res, mapreduce.KeyValue{v, document})
}
return
}
// 最重要的是去重
func reduceF(key string, values []string) string {
// TODO: you should complete this to do the inverted index challenge
set := make(map[string]bool)
var results []string
for _,str := range values{
set[str] = true
}
for value := range set{
if set[value] == true{
results = append(results, value)
}
} //results存着所有的文档
sort.Strings(results)
//res := key +": "+ strconv.Itoa(len(results))+" "
res :=strconv.Itoa(len(results))+" " //系统会自动填充前两项 都在会出现错误
for i,v := range results{
if i >= 1{
res += ","
}
res += v
}
return res
}

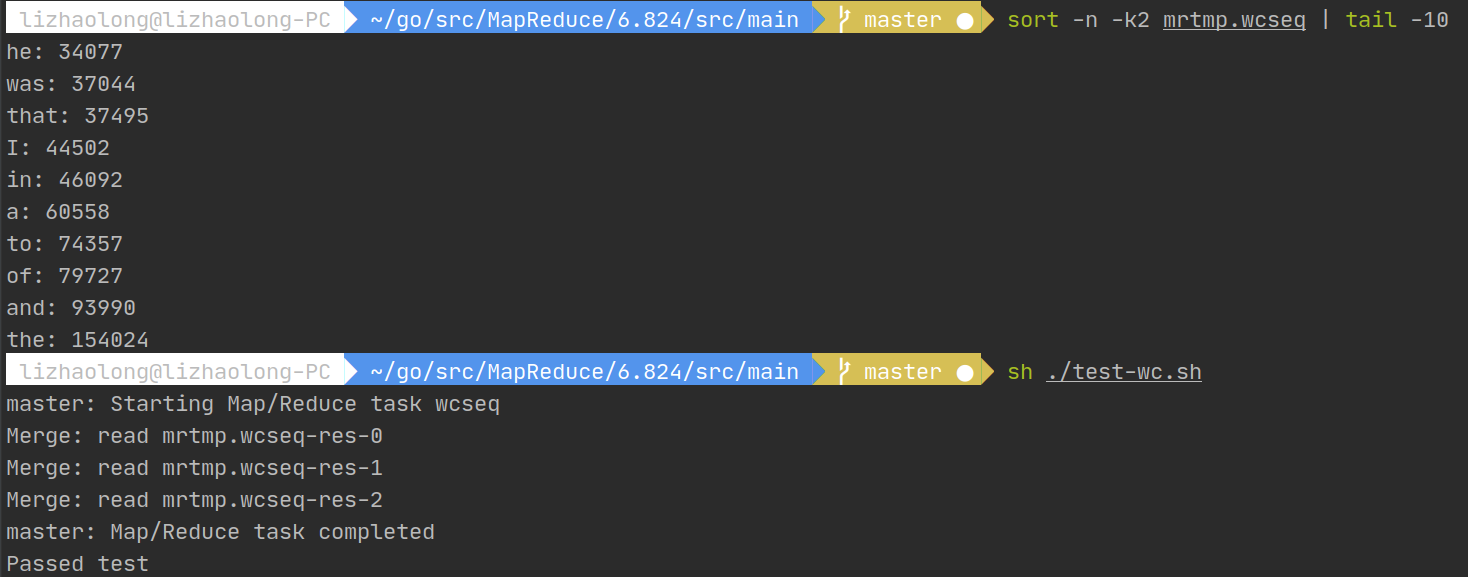
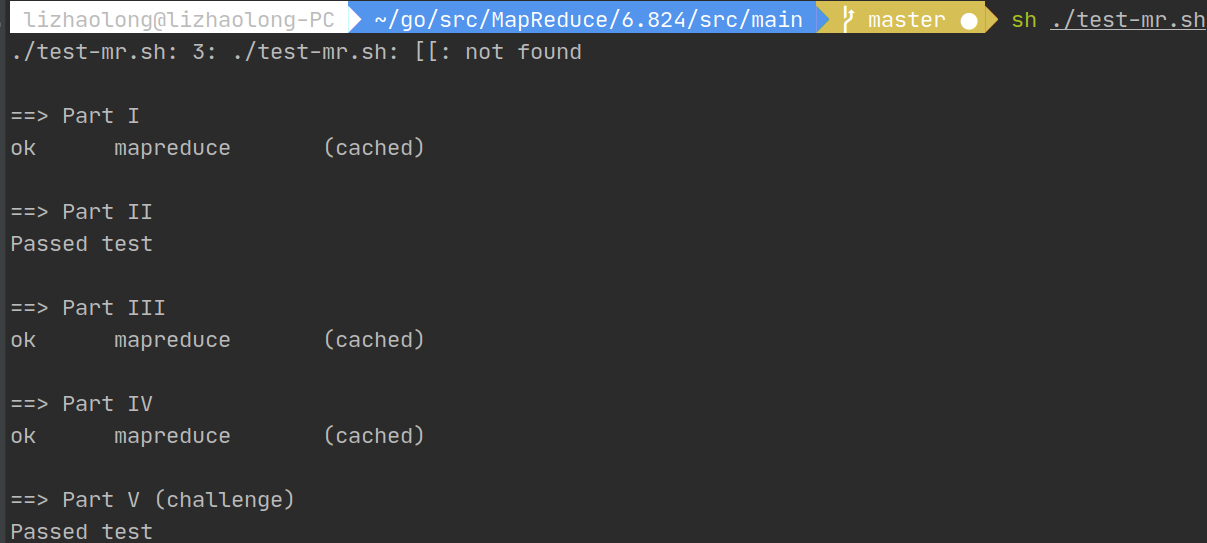
然后lab1就OK啦!我们可以执行sh ./test-mr.sh测试五个部分的代码。
总结
不得不说国外的课程压力还是比较大,一周之内要求完成Go语言的学习,完成MapReduce的论文学习和lab1的所有部分,但不可否认都是精华。对比本校计算机课程的课程任务和教学水平,实在是让人汗颜。好在算是在规定时间之内完成了lab1,不可否认收获是巨大的,不仅对于mapReduce的理解更为深入,还学习了一门如此有趣且有用的语言,对于一个受C++折磨快两年的苦逼大学生来说实在是让人热泪盈眶啊。
搞定收工,看海贼王去。
2020.8.1 :
更新了一个6.824每一课后面的问题解答,有很多确实很有意思的问题,有兴趣的朋友可以看看
最后
以上就是受伤柜子最近收集整理的关于MIT 6.824 lab1引言的全部内容,更多相关MIT内容请搜索靠谱客的其他文章。








发表评论 取消回复