1.需求:
使用Spark SQL 连接hive ,读取数据,将统计结果存储到 mysql中
2.将写好的代码打包上传的集群,然后提交spark运行,前提是hive,HDFS已经启动
3.代码:
(1)pom.xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.0</version>
</dependency>
(2)demo4.scala
package day1209
import org.apache.spark.sql.SparkSession
import java.util.Properties
/**
* 使用Spark SQL 连接hive ,将统计结果存储到 mysql中
*
* ./spark-submit --master spark://hadoop1:7077 --jars /usr/local/tmp_files/mysql-connector-java-8.0.11.jar --driver-class-path /usr/local/tmp_files/mysql-connector-java-8.0.11.jar --class day0628.Demo4 /usr/local/tmp_files/Demo1209.jar
*/
object Demo4 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("Hive2Mysql").enableHiveSupport().getOrCreate()
//.config("spark.sql.inMemoryColumnarStorage.batchSize", 10)
//执行sql
val result = spark.sql("select deptno,mgr from default.emp")
//将结果保存到mysql中
val props = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "000000")
result.write.mode("append").jdbc(
"jdbc:mysql://hadoop2:3306/company?serverTimezone=UTC&characterEncoding=utf-8",
"emp_stat", props)
//停止Spark
spark.stop()
}
}
4.执行:
(1)启动spark
cd /opt/module/spark-2.1.1
./bin/spark-submit --master spark://hadoop2:7077 --jars /opt/TestFolder/mysql-connector-java-5.1.27.jar --driver-class-path /opt/TestFolder/mysql-connector-java-5.1.27.jar --class spark.sqlshizhan.Demo4 /opt/TestFolder/Scala-1.0-SNAPSHOT.jar
5.结果:
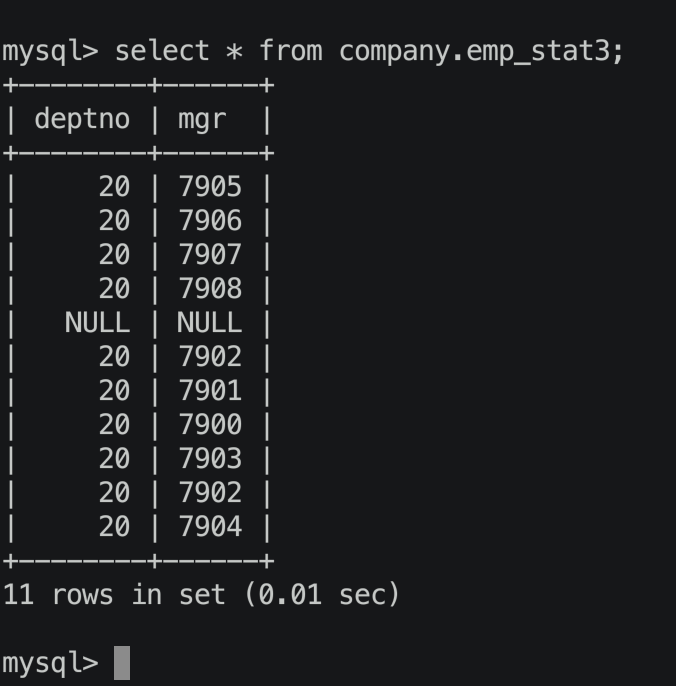
最后
以上就是洁净热狗最近收集整理的关于Spark SQL实战:使用Spark SQL 连接hive ,将统计结果存储到 mysql中的全部内容,更多相关Spark内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复