=======================更新===========================
这段时间有很多人反映在跑代码的时候会出现NAN的错误,由于本人最近忙着找实习和实习,所以一直没有时间去找模型里面的错误,一直在拖这个事情。恰好一位网友很认真的在咨询我并且尝试着修改模型代码,所以借着这次机会把模型中的一些问题找了出来并更新了模型代码,最新的代码可以参考这位网友的GitHub:https://github.com/Fengfeng1024/MPCNN
为了方便大家了解代码的问题,以及如何寻找bug,这里贴出来我们邮沟通的细节,希望大家可以通过这个过程学到如何解决代码中的bug,下面邮件内容倒叙排列~~:
https://github.com/Fengfeng1024/MPCNN 感谢博主的分享
—————— 原始邮件 ——————
发件人: “254557889”<254557889@qq.com>;
发送时间: 2018年5月8日(星期二) 晚上9:04
收件人: “输过,败过,不曾怕过”chenfeng_scut@qq.com;
主题: 回复:关于您的MPCNN模型复现代码遗留问题
恭喜恭喜,因为我看这个代码还有文章下面一直有人在咨询NAN的问题,所以如果可以的话你能把终版代码pull到我github的项目上吗,或者说你上传到你自己的GitHub上面,然后我在文章和代码里面给出你实现的连接,好让更多的人能够看到,有所帮助~~
—————— 原始邮件 ——————
发件人: “输过,败过,不曾怕过”chenfeng_scut@qq.com;
发送时间: 2018年5月8日(星期二) 下午4:26
收件人: “刘冲”<254557889@qq.com>;
主题: 回复:关于您的MPCNN模型复现代码遗留问题
今天我用tensorboard可视化了每个层的权重和一些输出,发现计算欧氏距离的时候有些输出是0,我觉得可能因为这个导致最后softmax的输入有些为0,所以loss变为NAN了,既然如此,我于是计算欧式距离最后加了1e-4,没想到loss还是NAN。还有一个想法就是用标准化欧氏距离,不知道可不可行。现在跑模型没用欧式距离,同时对您的代码有一些改进,权重都初始化为mean=0,stddev=1.0,在每一层卷积后加BN层,所有可训练的参数加到L2正则化。附件有acc和loss曲线,增加了epoch,终于收敛了。
—————— 原始邮件 ——————
发件人: “254557889”<254557889@qq.com>;
发送时间: 2018年5月7日(星期一) 中午12:13
收件人: “输过,败过,不曾怕过”chenfeng_scut@qq.com;
主题: 回复:关于您的MPCNN模型复现代码遗留问题
你好,看了你的邮件也给了我一些提示,首先我认为NAN出现的原因可能是,相似度计算处,对每个向量的每个维度的平方差求和,而每个向量都是卷积之后的输出,正如你所说relu激活函数的输出值可能会很大,导致欧氏距离计算平方和时出现NAN的现象,而余弦相似度分母会进行归一化操作,自然没有NAN的问题。上面是我分析的原因,但我不明白的是为什么去掉了sqrt就可以解决NAN??我的想法是把relu改成tanh,或者说不使用欧氏距离。然后至于说训练效果很差这个问题,首先来讲数据集是公共数据集应该不会有问题,肉眼可见的训练上的规律很可疑,因为训练过程中加入了shuffle,不应该能找到像你说的那种规律。这里可以尝试的方案是,将代码改变一下,可以每100个step eval一次,而不是每个epoch eval一次,然后再tensorboard上面查看train和eval两条曲线,看看原因究竟是什么,另外把训练过程中的W和b权重也都可视化一下,往往问题会出现在某个权重的异常上面。再有就是我看训练的acc还算可以,但是eval的acc只有0.3,另外一个就是loss下降的很缓慢,一般使用了tf.reduce_mean之后loss应该降到很低才对,现在维持在40+肯定是有问题的。
—————– 原始邮件 ——————
发件人: “输过,败过,不曾怕过”chenfeng_scut@qq.com;
发送时间: 2018年5月7日(星期一) 中午11:43
收件人: “刘冲”<254557889@qq.com>;
主题: 回复:关于您的MPCNN模型复现代码遗留问题
非常感谢您的回复。根据您提供的思路,首先我采用了梯度截断的方法,将梯度控制在某一范围内,但是这样跑出来的效果并不好;然后我用了tfdbg定位到计算欧式距离的时候出现了NAN,我把tf.sqrt去掉之后就可以了,不过我还是不明白为什么会出现NAN,因为计算余弦相似度的时候也是用了tf.sqrt函数。还有一个原因也会导致NAN,就是relu激活函数,paper中的激活函数都是tanh。训练过程中,我发现到某些数据集的时候训练效果非常不好,而且loss和acc波动有点大,难以收敛。附件有训练日志,lr=1e-3、epoch=10、batch_size=64.
—————— 原始邮件 ——————
发件人: “254557889”<254557889@qq.com>;
发送时间: 2018年5月5日(星期六) 下午3:08
收件人: “输过,败过,不曾怕过”chenfeng_scut@qq.com;
主题: 回复:关于您的MPCNN模型复现代码遗留问题
你好,这个代码是我刚开始使用tf仿真论文的时候做的,当时确实遇到了很多问题,包括代码本身应该也存在很多问题。当时的效果其实也很差,一直想着回头再看看修改一下,但是最近一直比较忙没时间搞,所以希望你在跑程序的同时自己看看程序本身是否存在问题,而不是单纯的跑代码。另外关于你说的W1全部变为NAN这个问题,可以尝试使用RNN训练过程中常用的梯度截断的方法,把梯度限制在10以内,这样应该可以防止NAN现象的出现,另外就是看看代码里面究竟哪一行引起了NAN的出现,这里可以看一下官网上面tfdbg的介绍,里面说了如何找到NAN出现的位置以及简单地分析方法。很哟可能是分母部分为0之类的情况导致的。最后,希望你能把这个代码跳出来改正确吧~~
—————— 原始邮件 ——————
发件人: “输过,败过,不曾怕过”chenfeng_scut@qq.com;
发送时间: 2018年5月5日(星期六) 中午12:45
收件人: “刘冲”<254557889@qq.com>;
主题: 关于您的MPCNN模型复现代码遗留问题
博主,您好,首先非常感谢您对MPCNN模型的思路与代码分享,我在运行您的代码过程中,碰到了loss为nan的情况,网上查了很多方法,调整lr、batch_size,tf.clip_by_value函数调整最后一层输出,同时仔细对比了论文与您的复现代码,没发现任何问题,然后我打印出每一个权重参数,发现第一个batch_size训练过后,权重参数W1[0]全部变为NAN,我还是不知道怎么解决这个问题,无奈之下联系博主,希望博主能解决我的疑问,万分感谢
=======================以下是原文===============================
上节已经介绍了数据预处理部分代码,本节则详细介绍一下模型构建和训练部分。旨在以一个新手的角度出发,详细介绍一下tf中不同类型cnn的使用方法以及其中tensor的shape变化,来感受一下其运行过程的细节。代码可以在我的github上下载
模型初始化
首先我们介绍一下模型构建部分。这部分代码全部写在model.py文件中。为了方便调用,我们写了一个MPCNN_Layer类来实现整个论文模型的构建。首先是init函数,主要用于初始化一些权重参数等,代码入下:
#初始化一些变量主要包括了各层之间的权重,偏置。
def __init__(self, num_classes, embedding_size, filter_sizes, num_filters, n_hidden,
input_x1, input_x2, input_y, dropout_keep_prob):
'''
:param num_classes: 6,代表6种类别。即输出y的维度
:param embedding_size: 词向量维度
:param filter_sizes: 卷积窗口大小。此处为列表【1,2,100】100表示对整个句子直接卷积。
:param num_filters: 卷积核数量,这里为列表【num_filters_A,num_filters_B】分别为20,20.论文中A为300
:param n_hidden:全连接层的神经元个数
:param input_x1:输入句子矩阵。shape为【batch_size,sentence_length, embed_size,1】
:param input_x2:同inpt_x1
:param input_y:输出6维的array。one-hot编码
:param dropout_keep_prob:dropout比率
'''
self.embedding_size = embedding_size
self.filter_sizes = filter_sizes
self .num_filters = num_filters
self.poolings = [tf.reduce_max, tf.reduce_min, tf.reduce_mean]
self.input_x1 = input_x1
self.input_x2 = input_x2
self.input_y = input_y
self.dropout_keep_prob = dropout_keep_prob
#Block_A的参数。因为有三种窗口尺寸,所以初始化三个参数
self.W1 = [init_weight([filter_sizes[0], embedding_size, 1, num_filters[0]]),
init_weight([filter_sizes[1], embedding_size, 1, num_filters[0]]),
init_weight([filter_sizes[2], embedding_size, 1, num_filters[0]])]
self.b1 = [tf.Variable(tf.constant(0.1, shape=[num_filters[0]])),
tf.Variable(tf.constant(0.1, shape=[num_filters[0]])),
tf.Variable(tf.constant(0.1, shape=[num_filters[0]]))]
# Block_B的参数。这里只需要两种窗口尺寸(舍弃100的窗口),所以初始化两个参数
self.W2 = [init_weight([filter_sizes[0], embedding_size, 1, num_filters[1]]),
init_weight([filter_sizes[1], embedding_size, 1, num_filters[1]])]
self.b2 = [tf.Variable(tf.constant(0.1, shape=[num_filters[1], embedding_size])),
tf.Variable(tf.constant(0.1, shape=[num_filters[1], embedding_size]))]
#卷积层经过句子相似计算之后的输出flatten之后的尺寸。用于生成隐藏层的参数。具体会在后面介绍
self.h = num_filters[0]*len(self.poolings)*2 +
num_filters[1]*(len(self.poolings)-1)*(len(filter_sizes)-1)*3 +
len(self.poolings)*len(filter_sizes)*len(filter_sizes)*3
#全连接层参数
self.Wh = tf.Variable(tf.random_normal([self.h, n_hidden], stddev=0.01), name='Wh')
self.bh = tf.Variable(tf.constant(0.1, shape=[n_hidden]))
#输出层参数
self.Wo = tf.Variable(tf.random_normal([n_hidden, num_classes], stddev=0.01), name='Wo')
Block_A和Block_B的构建
接下来进行Block_A的构建,这个比较简单,直接调用conv2d函数即可。如下图所示,代码入下:
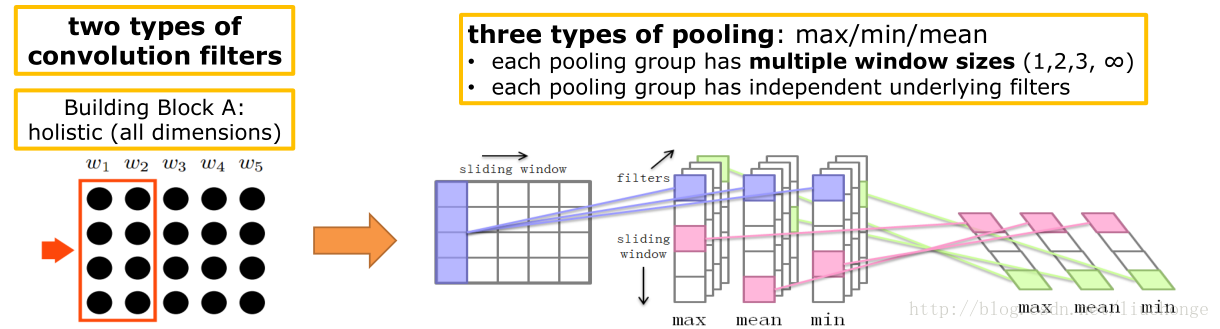
def bulit_block_A(self, x):
#bulid block A and cal the similarity according to algorithm 1
out = []
with tf.name_scope("bulid_block_A"):
#遍历每个pooling方式,max、min、mean
for pooling in self.poolings:
pools = []
#每个pooling都对应几种不同的窗口大小。【1,2,100】
for i, ws in enumerate(self.filter_sizes):
#print x.get_shape(), self.W1[i].get_shape()
with tf.name_scope("conv-pool-%s" %ws):
#x->[batch_size, sentence_length, embed_size, 1], W1[i]->[ws, embed_size, 1, num_filters]
conv = tf.nn.conv2d(x, self.W1[i], strides=[1, 1, 1, 1], padding="VALID")
#print conv.get_shape()
conv = tf.nn.relu(conv + self.b1[i]) # [batch_size, sentence_length-ws+1, 1, num_filters_A]
pool = pooling(conv, axis=1) ## [batch_size, 1, num_filters_A]
pools.append(pool)
out.append(pools)
return out所以Block_A的输出out是一个嵌套列表。第一层长度为3,代表三种pooling方式,第二层长度为3,代表三种卷积窗口大小,然后其中每个元素都是[batch_size, 1, num_filters_A]的三维Tensor。
接下来看Block_B部分的构建。由于此处用到了per_dim的卷积核,所以比较麻烦。图和代码如下所示。
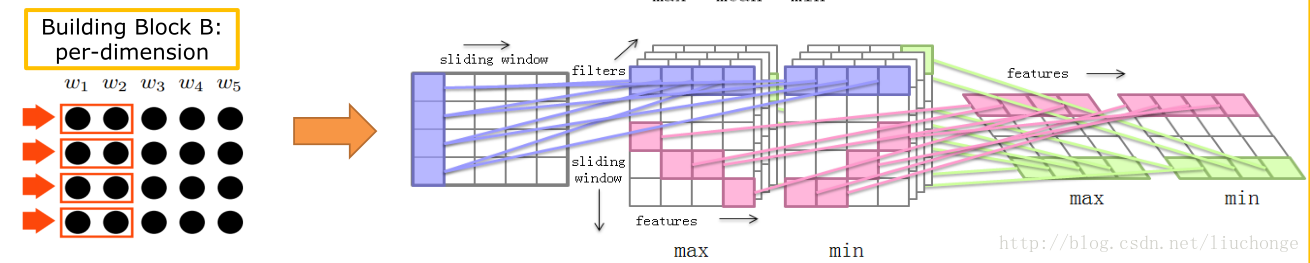
def per_dim_conv_layer(self, x, w, b, pooling):
'''
实现per_dim卷积,请结合模型介绍篇的图片进行理解
:param input: [batch_size, sentence_length, embed_size, 1]
:param w: [ws, embedding_size, 1, num_filters]
:param b: [num_filters, embedding_size]
:param pooling:
:return:
'''
# 为了实现per_dim的卷积。所以我们要将输入和权重偏置参数在embed_size维度上进行unstack
#这样我们就获得了每个维度上的输入、权重、偏置。可以结合模型介绍篇里面的图片进行理解
input_unstack = tf.unstack(x, axis=2)
w_unstack = tf.unstack(w, axis=1)
b_unstack = tf.unstack(b, axis=1)
convs = []
#对每个embed_size维度进行卷积操作
for i in range(x.get_shape()[2]):
#conv1d要求三维的输入,三维的权重(没有宽度,只有长度。所以称为1d卷积)。具体可以参见官方API。
conv = tf.nn.relu(tf.nn.conv1d(input_unstack[i], w_unstack[i], stride=1, padding="VALID") + b_unstack[i])
# [batch_size, sentence_length-ws+1, num_filters_A]
convs.append(conv)
#将embed_size个卷积输出在第三个维度上进行进行stack。所以又获得了一个4位的tensor
conv = tf.stack(convs, axis=2) # [batch_size, sentence_length-ws+1, embed_size, num_filters_A]
#池化。即对第二个维度的sentence_length-ws+1个值取最大、最小、平均值等操作、
pool = pooling(conv, axis=1) # [batch_size, embed_size, num_filters_A]
return pool
def bulid_block_B(self, x):
out = []
with tf.name_scope("bulid_block_B"):
for pooling in self.poolings[:-1]:
pools = []
for i, ws in enumerate(self.filter_sizes[:-1]):
with tf.name_scope("per_conv-pool-%s" % ws):
pool = self.per_dim_conv_layer(x, self.W2[i], self.b2[i], pooling)
pools.append(pool)
out.append(pools)
return out
其中bulid_block_B函数作用与bulid_block_A相同不做介绍。而 per_dim_conv_layer函数则实现了per_dim卷积方法。注释已经很清楚了。所以Block_B的输出out也是一个嵌套列表。第一层长度为2,代表两种pooling方式,第二层长度为2,代表两种卷积窗口大小,然后其中每个元素都是[batch_size, 50, num_filters_B]的三维Tensor。
相似性测量层的构建
经过上面两个部分的构建,我们就应实现了句子表示部分的代码。接下来就是实现相似测量层的两个算法。如下图所示:

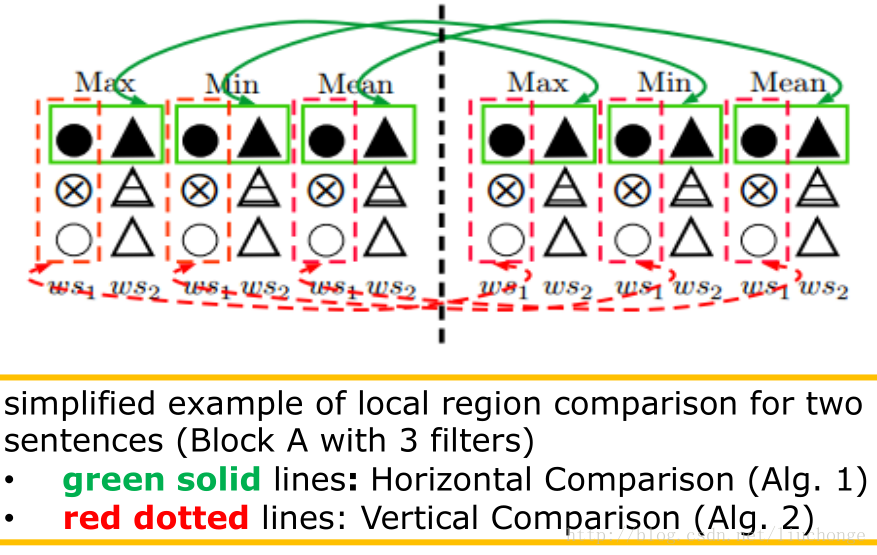
def similarity_sentence_layer(self):
#对输入的两个句子进行构建block_A。
#sent1,2都是3*3*[batch_size,1, num_filters_A]的嵌套列表
sent1 = self.bulit_block_A(self.input_x1)
sent2 = self.bulit_block_A(self.input_x2)
fea_h = []
#实现算法1
with tf.name_scope("cal_dis_with_alg1"):
for i in range(3):
#将max,men,mean三个进行连接
regM1 = tf.concat(sent1[i], 1)
regM2 = tf.concat(sent2[i], 1)
#按照每个维度进行计算max,men,mean三个值的相似度。可以参考图中绿色框
for k in range(self.num_filters[0]):
#comU2计算两个tensor的距离,参见上篇博文,得到一个(batch_size,2)的tensor。2表示余弦距离和L2距离
fea_h.append(comU2(regM1[:, :, k], regM2[:, :, k]))
#得到fea_h是一个长度3*20=60的list。其中每个元素都是(batch_size,2)的tensor
fea_a = []
#实现算法2的2-9行
with tf.name_scope("cal_dis_with_alg2_2-9"):
for i in range(3):
for j in range(len(self.filter_sizes)):
for k in range(len(self.filter_sizes)):
# comU1计算两个tensor的距离,参见上篇博文,上图中的红色框。得到一个(batch_size,3)的tensor。3表示余弦距离和L2距离,L1距离
fea_a.append(comU1(sent1[i][j][:, 0, :], sent2[i][k][:, 0, :]))
#得到fea_a是一个长度为3*3*3=27的list。其中每个元素是(batch_size,3)的tensor
# 对输入的两个句子进行构建block_B。
# sent1,2都是2*2*[batch_size,50, num_filters_B]的嵌套列表
sent1 = self.bulid_block_B(self.input_x1)
sent2 = self.bulid_block_B(self.input_x2)
fea_b = []
# 实现算法2的剩余行
with tf.name_scope("cal_dis_with_alg2_last"):
for i in range(len(self.poolings)-1):
for j in range(len(self.filter_sizes)-1):
for k in range(self.num_filters[1]):
fea_b.append(comU1(sent1[i][j][:, :, k], sent2[i][j][:, :, k]))
##得到fea_b是一个长度为2*2*20=80的list。其中每个元素是(batch_size,3)的tensor
return tf.concat(fea_h + fea_a + fea_b, 1)经过相似计算函数我们就获得了两个句子的相似性向量fea_h,fea_a,fea_b,通过tf.concat()函数就可以将其进行连接得到一个flatten的相似性输出向量fea。这里需要注意的问题是fea维度的计算,我们之前已经知道了fea_h,fea_a,fea_b的维度,分别是60*[batch_size, 2]、27*[batch_size, 3]、80*[batch_size, 3],那么首先将其连接,然后再第一个维度上进行扩展,最终就可以获得一个shape是[batch_size, 441]的Tensor。
全连接层构建
有了fea,接下来的工作就简单了,我们只需要将其输入全连接层即可完成模型的构建工作。代码入下:
def similarity_measure_layer(self):
#调用similarity_sentence_layer函数获得句子的相似性向量
fea = self.similarity_sentence_layer()
# fea_h.extend(fea_a)
# fea_h.extend(fea_b)
#print len(fea_h), fea_h
#fea = tf.concat(fea_h+fea_a+fea_b, 1)
#print fea.get_shape()
with tf.name_scope("full_connect_layer"):
h = tf.nn.tanh(tf.matmul(fea, self.Wh) + self.bh)
h = tf.nn.dropout(h, self.dropout_keep_prob)
o = tf.matmul(h, self.Wo)
return o模型训练
至此我们就完成了模型的搭建工作。接下来就可以进行训练了。这部分代码写在train1.py文件中,主要完成了词向量、训练、测试数据的读取,模型的定义和训练,Summary的记录等工作。是一个比较标准的tf执行流程。这里也推荐大家使用app.flags来定义模型的超参数,这样一来之后修改参数会很方便,修改一个地方就可以了,免得改来改去还总是报错。app定义如下:
tf.app.flags.DEFINE_integer('embedding_dim', 50, 'The dimension of the word embedding')
tf.app.flags.DEFINE_integer('num_filters_A', 20, 'The number of filters in block A')
tf.app.flags.DEFINE_integer('num_filters_B', 20, 'The number of filters in block B')
tf.app.flags.DEFINE_integer('n_hidden', 150, 'number of hidden units in the fully connected layer')
tf.app.flags.DEFINE_integer('sentence_length', 100, 'max size of sentence')
tf.app.flags.DEFINE_integer('num_classes', 6, 'num of the labels')
tf.app.flags.DEFINE_integer('num_epochs', 10, 'Number of epochs to be trained')
tf.app.flags.DEFINE_integer('batch_size', 32, 'size of mini batch')
tf.app.flags.DEFINE_integer("display_step", 100, "Evaluate model on dev set after this many steps (default: 100)")
tf.app.flags.DEFINE_integer("evaluate_every", 100, "Evaluate model on dev set after this many steps (default: 100)")
tf.app.flags.DEFINE_integer("checkpoint_every", 100, "Save model after this many steps (default: 100)")
tf.app.flags.DEFINE_integer("num_checkpoints", 5, "Number of checkpoints to store (default: 5)")
tf.app.flags.DEFINE_float('lr', 1e-3, 'learning rate')
tf.app.flags.DEFINE_float('l2_reg_lambda', 1e-4, 'regularization parameter')
tf.app.flags.DEFINE_boolean("allow_soft_placement", True, "Allow device soft device placement")
tf.app.flags.DEFINE_boolean("log_device_placement", False, "Log placement of ops on devices")
filter_size = [1,2,100]
conf = tf.app.flags.FLAGS
conf._parse_flags()接下来就是进行数据读入和模型构建工作。都很简单不做过多介绍,代码入下:
#glove是载入的次向量。glove.d是单词索引字典<word, index>,glove.g是词向量矩阵<词个数,300>
glove = emb.GloVe(N=50)
#-------------------------------------Loading data----------------------------------------------#
print ("Loading data...")
Xtrain, ytrain = load_set(glove, path='./sts/semeval-sts/all')
#[22592, 句长]
Xtest, ytest = load_set(glove, path='./sts/semeval-sts/2016')
#[1186, 句长]
#-------------------------------------Loading finished----------------------------------------------#
#-------------------------------------training the network----------------------------------------------#
with tf.Session() as sess:
#定义输入输出等placeholder
input_1 = tf.placeholder(tf.int32, [None, conf.sentence_length], name="input_x1")
input_2 = tf.placeholder(tf.int32, [None, conf.sentence_length], name="input_x2")
input_3 = tf.placeholder(tf.int32, [None, conf.num_classes], name="input_y")
dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
#通过embedding_lookup进行单词索引-》词向量的转换。glove.g是词向量矩阵
s0_embed = tf.nn.embedding_lookup(glove.g, input_1)
s1_embed = tf.nn.embedding_lookup(glove.g, input_2)
input_x1 = tf.reshape(s0_embed, [-1, conf.sentence_length, conf.embedding_dim, 1])
input_x2 = tf.reshape(s1_embed, [-1, conf.sentence_length, conf.embedding_dim, 1])
input_y = tf.reshape(input_3, [-1, conf.num_classes])
#构建MPCNN模型
setence_model = MPCNN_Layer(conf.num_classes, conf.embedding_dim, filter_size,
[conf.num_filters_A, conf.num_filters_B], conf.n_hidden,
input_x1, input_x2, input_y, dropout_keep_prob)
#调用similarity_measure_layer函数获得模型输出
out = setence_model.similarity_measure_layer()
#使用softmax交叉熵函数计算cost
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=out, labels=setence_model.input_y))
train_step = tf.train.AdamOptimizer(conf.lr).minimize(cost)
#获得预测和精确度
predict_op = tf.argmax(out, 1)
acc = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(input_y, 1), tf.argmax(out, 1)), tf.float32))
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}n".format(out_dir))
loss_summary = tf.summary.scalar("loss", cost)
acc_summary = tf.summary.scalar("accuracy", acc)
train_summary_op = tf.summary.merge([loss_summary, acc_summary])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph)
dev_summary_op = tf.summary.merge([loss_summary, acc_summary])
dev_summary_dir = os.path.join(out_dir, "summaries", "dev")
dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, sess.graph)
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=conf.num_checkpoints)
init = tf.global_variables_initializer().run()
for j in range(10):
for i in range(0, 20000, conf.batch_size):
x1 = Xtrain[0][i:i + conf.batch_size]
x2 = Xtrain[1][i:i + conf.batch_size]
y = ytrain[i:i + conf.batch_size]
_, summaries, accc, loss = sess.run([train_step, train_summary_op, acc, cost],
feed_dict={input_1: x1, input_2: x2, input_3: y, dropout_keep_prob: 0.5})
time_str = datetime.datetime.now().isoformat()
print("{}: loss {:g}, acc {:g}".format(time_str, loss, accc))
train_summary_writer.add_summary(summaries)
print("nEvaluation:")
accc = sess.run(acc, feed_dict={input_1: Xtest[0], input_2: Xtest[1], input_3: ytest, dropout_keep_prob: 1.0})
print "test accuracy:", accc一些效果图
执行上面的代码我们就可以去tensorboard查看我们程序运行的效果了。先贴几张模型架构图:
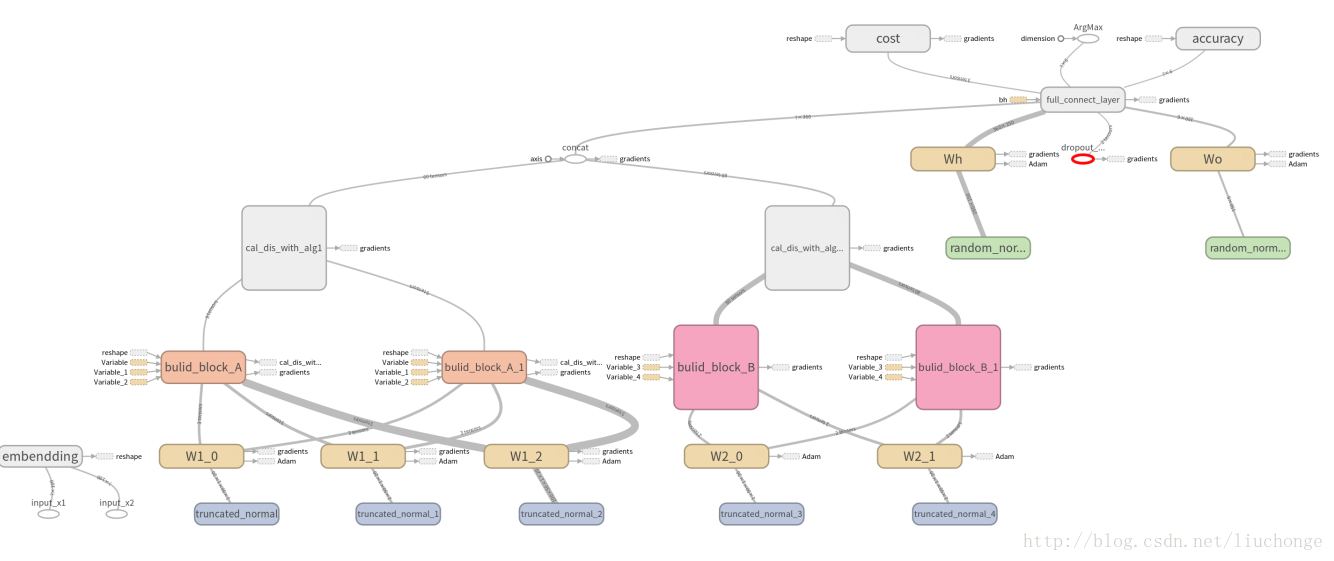
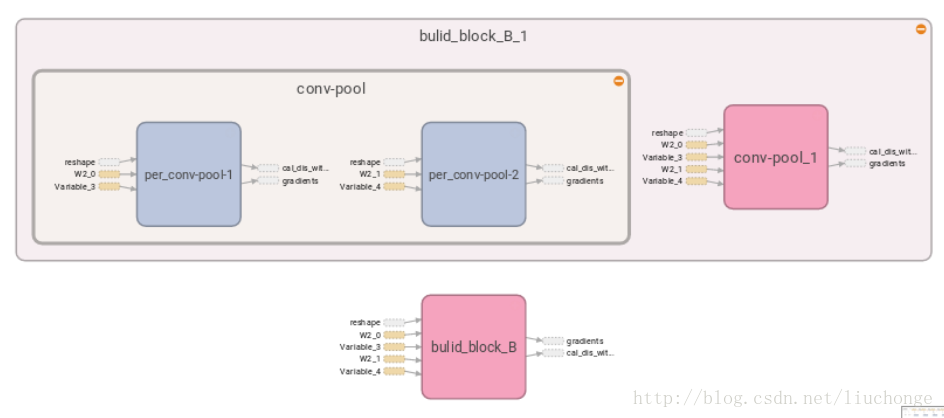
下面这张是Block_B的内部架构,其实蓝色方框内还有embed_size个per_dim的卷积核,由于太多了所以不进行展示:
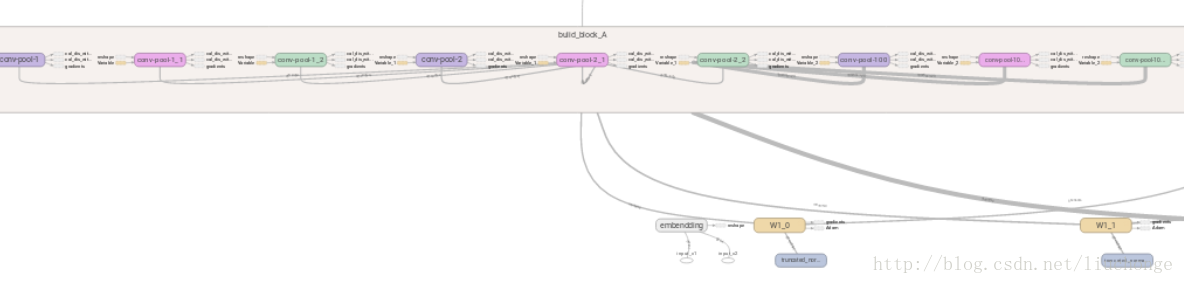
再来一张Block_A的内部架构,里面一共9个卷积-pooling层:
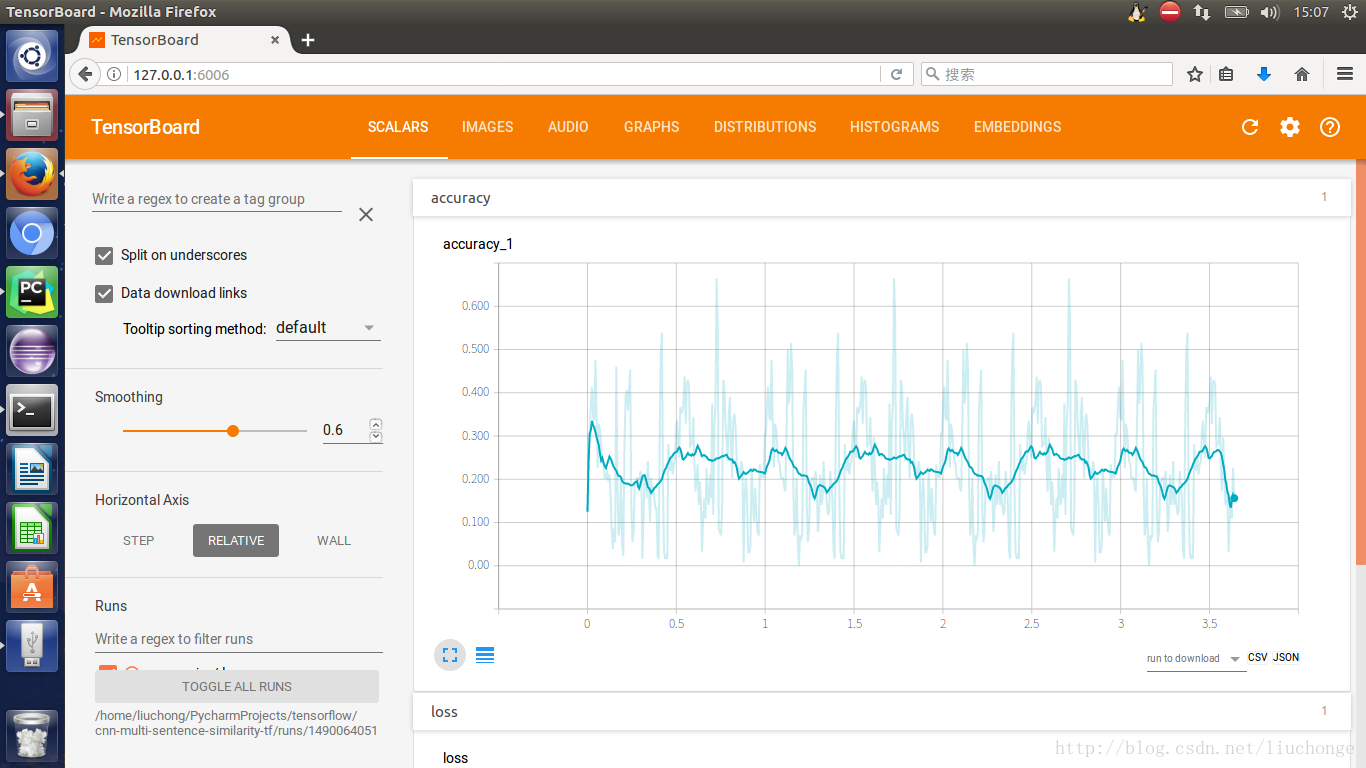
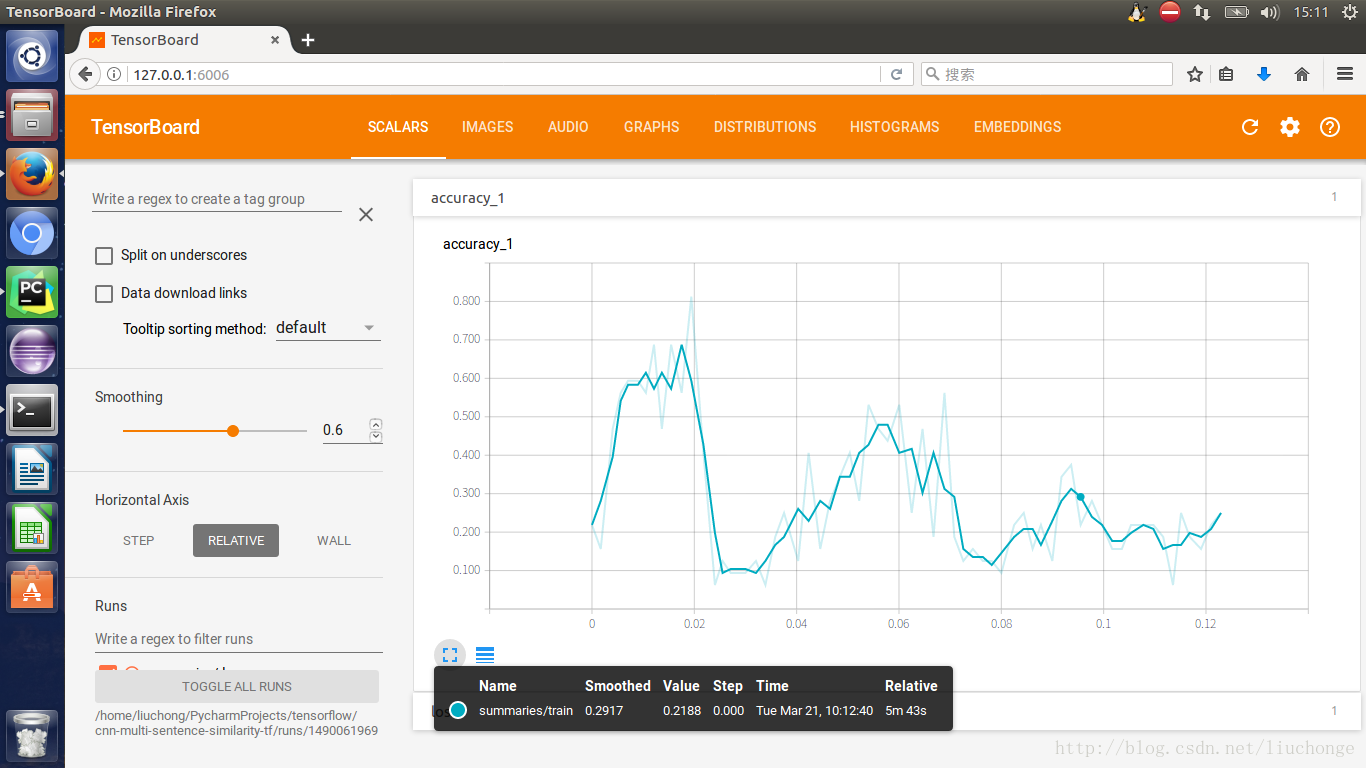
等等吧,还有很多可以去细看的图,这里就不一一列举了。接下来说一下程序运行不理想的地方==那就是准确度了。这里由于很多参数并未按照论文中所说的那样设置,也有可能是被的一些原因导致准确度上不去,如下图所示。总是震荡,而无法收敛。请教了一些朋友,改了改学习率啊、dropout啊、batch_size啊等等,都收效甚微。但是本着写程序练手的态度就不纠结与这些细节了,也是因为每一次训练成本都比较高。自己懒得去一步步调参了==不过还是贴出来两张训练的结果吧。
最后的总结
好了,这样我们就算勉强完成了对该论文的方针实现啦(捂脸)。在总结一下几个需要注意的点,也是我在编程序的时候遇到的坑:
- 在程序编写过程中一定要对各个变量的shape聊熟于心,刚入门的要多看官方文档,把一些重要的函数用法和作用了解的比较透彻,这样才能在使用的时候知道用哪个函数,怎么用。
- 词向量千万不要在读取训练集的时候就转化,否则太消耗内存了。要是用tf提供的embedding_lookup函数在训练的过程中在进行转化
- 输入要转化为np数组才行,不然feed的时候会报错。
- 变量、每一个比较重要的部分都是用tf.name_scope()函数命名,不然最后你会发现TensorBoard上面的结构图夸张复杂到无法加载。然后就是在TensorBoard架构图页面右侧的模块可以右键添加到左侧,这样才能形成一个完整的流图,不然你看到的可能是一个个分离的模块。
- 至于模型调参的问题,我还要继续慢慢研究,感觉还有很长的路要走
- 看教程的时候要自己动手写一遍,甚至调试一边,这样会收获更多
- 对了,说到调试,跑程序的时候遇到了几个问题,很棘手,比如cost是NAN,当时想着用tfdbg调试呢,但是环境老是报错,最终无奈放弃了。改用调整学习率等参数解决了。但是我觉得tfdbg看起来很好用,决定最近抽时间看一看。配置好。
- 还有很多遇到的问题,但是一时想不起来了,以后再说吧。
最后
以上就是土豪楼房最近收集整理的关于CNN在句子相似性建模的应用--tensorflow实现篇2的全部内容,更多相关CNN在句子相似性建模内容请搜索靠谱客的其他文章。








发表评论 取消回复