6.1 初识Mahout
Apache Mahout是Apache基金支持的顶级项目,其目标在于建立可伸缩的用于机器学习算法库。现在,Mahout支持数据挖掘的三个领域:
(1)Recommendation mining,推荐引擎(协同过滤);(2)Clustering,聚类; (3)Classification,分类。
目前,Apache发布的最新版本是0.9,它主要支持:User and Item based recommenders、Matrix factorization based recommenders、K-Means, Fuzzy K-Means clustering、Latent Dirichlet Allocation(集合概率模型)、Singular Value Decomposition(奇异值分解)、Logistic regression classifier(逻辑回归分类器)、Naive Bayes classifier(贝叶斯分类)、Random forest classifier(随机森林分类器)、High performance java collections、A vibrant community。
6.2 Mahout的安装与配置
6.2.1Mahout的安装
Apache提供了两种类型的Mahout安装文件,一种是bin(二进制)类型,另一种是src(源码)类型。前者安装较易,后者需要进行编译,并且须先安装Maven。下面在Hadoop集群(操作系统为CentOS6.4)中介绍这两种安装方法:
(1)bin(二进制)类型安装
step1:下载Mmahout tar文件
Mahout bin(二进制)下载地址:http://archive.apache.org/dist/mahout/0.8/mahout-distribution-0.8.tar.gz,本教程中下载的是0.8版本 。
命令:wget http://archive.apache.org/dist/mahout/0.8/mahout-distribution-0.8.tar.gz
step2:解压Mmahout tar文件
命令: tar -zxvf mahout-distribution-0.8.tar.gz -C $MAHOUT_HOME/
$MAHOUT_HOME代表的是安装Mahout的目标路径。
(2)src(源码)类型安装
教程中主要使用Maven3.0,所以系统需要先有JAVA1.6以上版本的支持。
命令:java -version
安装Maven2
step1:下载mave3。从http://maven.apache.org/download.cgi,下载apache-maven-3.2.2-bin.tar.gz。
命令:wget http://mirror.bit.edu.cn/apache/maven/maven-3/3.2.2/binaries/apache-maven-3.2.2-bin.tar.gz
step2:解压下载的文件。
命令:tar -zxvf apache-maven-3.2.2-bin.tar.gz
step3:配置maven
配置profile,命令:vi /etc/profile
加入以下内容:
export M2_HOME=/usr/local/maven3
export PATH=$PATH:$M2_HOME/bin
执行命令source /etc/profile使profile生效。
配置mvn,主要是修改Java的内存大小,命令:vi $M2_HOME/bin/mvn
在exec "$JAVACMD"后面加上:
-Xmx256m

step4:验证
命令:mvn -v
出现如下图所示界面表示安装成功。

安装Mahout
step1:先检查安装svn,命令:yum install svn
step2:下载Mahout src类型文件,用svn库下载当前Mahout最新版本.
命令:svn co http://svn.apache.org/repos/asf/mahout/trunk/
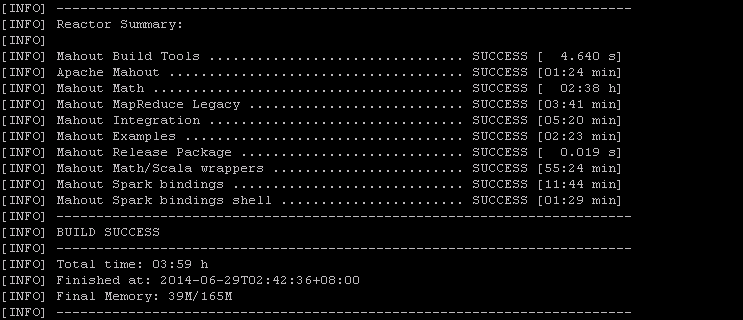
step3:使用maven安装Mahout,进入下载的trunk目录运行命令:mvn install,系统自动编译core和example目录,这个过程要执行testing部分,故将花费大量的时间,出现下图所示的界面表示安装成功。如果想在短时间内完成,可运行命令:mvn -DskipTests install
6.2.2 Mahout的配置
配置profile文件,便于操作mahout时不需要全路径。
命令:vi /etc/profile
加入下面的环境变量:
export HADOOP_CONF_DIR=$HADOOP_HOME/conf
export MAHOUT_HOME=/usr/local/trunk
export MAHOUT_CONF_DIR=$MAHOUT_HOME/conf
export PATH=$MAHOUT_HOME/conf:$MAHOUT_HOME/bin:$PATH
使用命令:source /etc/profile,使配置生效。
6.2.3 验证Mahout是否安装成功
命令:bin/mahout -help
安装成功后,此命令将显示mahout实现的所有算法命令,如下图所示。

6.3 关联规则挖掘
数据挖掘过程是从海量数据中发现未知的、用户感兴趣的、有潜在价值的知识和规则的过程,可以与用户或者知识库之间进行交互,把用户感兴趣的模式提供给用户,或者将其作为新的知识、规则加入知识库中。目前,数据挖掘的应用十分广泛。概括来说,数据挖掘的任务主要有估计(estimation)、分类(classification)、预测(prediction)、关联规则(association rule)、聚类(clustering)。
6.3.1 关联规则概述
关联规则挖掘用于寻找给定数据集中数据项之间的有趣的关联或相关关系,关联规则提示了数据项间的未知的依赖关系,根据所挖掘的关联关系,可以从一个数据对象的信息来推断另一个数据对象的信息,其中较为经典的案例是发生在沃尔玛超市的“啤酒与尿布“。
定义6.1 关联规则挖掘的数据集如果记为D(即事务数据库),即D={t1,t2,…,tk,…,tn},tk={i1,i2,…,im,…,ip}, tk称为事务(Transaction), im称为项(Item)。
定义6.2 项集(Itemset):设I={i1,i2,…,im}是D中全体项组成的集合,I的任何子集X称为D的项集。|X|=k称为集合X为k项集(K-Itemset)。
定义6.3 TID:事务的惟一标识。
定义6.4 项集支持数(Item count):数据集D中所包含的全部项集X的事务数,即:
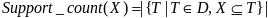
定义6.5 项集支持度(Item support):项集在事务数据库D中所出现的概率,即:

定义6.6 频繁项集:事先给定一个最小支持数(minsup),如果项集X的支持数大于等于这个最小支持数,那么X称为大项集或频繁项集。
定义6.7 关联规则(Association rule):若X、Y为项集,且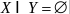
也就是说,对于已经给定的支持阈值和置信阈值,如果规则的置信度和支持度都大于相应阈值,那么这样的规则就称为关联规则。
一般来说,关联规则挖掘分为以下两个步骤进行:
步骤一:首先找出所有支持数大于等于指定的最小支持数的项集,即搜索大项集;
步骤二:利用已经找到的大项集进一步产生关联规则。
目前大多数研究都集中在频繁项集的挖掘上,寻找频繁项集的问题可以归纳为寻找含有给定置信度的规则,研究者们已经提出了许多这方面的发现算法,其中,较为经典的有Apriori算法、FPGrowth算法、AGM算法、PrefixSpan算法等。
6.3.2 Mahout实现的关联规则算法——FPGrowth
6.3.2.1 FPGrowth算法
在1993年Agrawal等人首次提出了挖掘顾客交易数据库中项集之间的关联规则的问题,提出了AIS算法和SETM算法,1994年又提出了改进的算法Apriori算法和AprioriTid算法[27][28][29],AIS算法与SET算法都是在遍历交易数据库期间不断产生候选项集,这种方法的显著特点就是会导致许多不必要的数据项集的生成和计数,而Apriori和AprioriTid算法只利用前次过程中生成的大项集来生成新的候选项集, AprioriTid算法在第一次遍历后完全不用交易数据库来计算候选集的支持数,而是使用了在前一次过程中所使用的候选项集来生成Tid表来代替原来的交易数据库,显然新生成的Tid表比原来的交易数据库小得多,这样就减少了许多不必要的I/O读取,提高了算法的效率。但是Apriori算法在挖掘额长频繁模式的时候性能往往低下,Jiawei Han提出了FPGrowth算法,它是基于频繁模式树的挖掘算法。
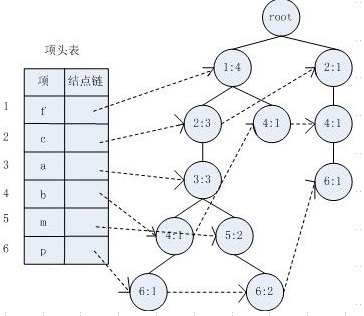
频繁模式树(Frequent Pattern Tree):将事务数据表中的各个事务数据项按照支持度排序后,把每个事务中的数据项按降序依次插入到一棵以 NULL为根结点的树中,同时在每个结点处记录该结点出现的支持度,如下图所示。
条件模式基:包含FP-Tree中与后缀模式一起出现的前缀路径的集合
条件树:将条件模式基按照FP-Tree的构造原则形成的一个新的FP-Tree
FPGrowth算法的基本思想:不断地迭代FP-tree的构造和投影过程。
step1 对于每个频繁项,构造它的条件投影数据库和投影FP-tree。
step2 对每个新构建的FP-tree重复这个过程,直到构造的新FP-tree为空,或者只包含一条路径。
step3 当构造的FP-tree为空时,其前缀即为频繁模式;当只包含一条路径时,通过枚举所有可能组合并与此树的前缀连接即可得到频繁模式。
6.3.2.2 Mahout使用FPGrowth算法进行频繁模式挖掘
Mahout已经实现了FPGrowth算法,使用时只需通过调用API中的mahout fpg命令便可完成频繁模式挖掘。用命令:mahut fpg -h,列出其参数。下面介绍几个常用的参数:
- --input(-i):数据输入路径
- --output(-o):数据输出路径
- --minSupport(-s):最小支持数,缺省为3
- --splitterPattern(-regex):挖掘中以数据行为单位,一行中可通过此参数设置数据项之间的分隔符,缺省为[,t]*[,|t][t][,t]*
- --method(-method):运行模式,可选sequential或mapreduce
- --encoding(-c):文本编码格式,缺省为UTF-8
例1 使用Mahout进行频繁模式挖掘
数据准备
实验数据来源于IBM公司Almaden研究中心开发的QUEST系统,下载网址:http://fimi.ua.ac.be/data/,每行数据中的数据项间用空格隔开。
运行Mahout fpg挖掘算法
1.sequential模式
设置本地运行命令:export MAHOUT_LOCAL=true
命令:
mahout fpg
>-i T10I4D100K.dat
>-o result
>-k 50
>-method sequential
>-regex '[ ]'
>-s 3
算法执行结束后,出现如下界面表示成功。

2.mapreduce模式
首先,需要将下载的数据文件上传至Hadoop集群上,并保证集群已经正常工作。
上传命令:hadoop dfs -put /usr/local/T10I4D100K.dat /user/root/testdata/
运行mahout命令:
mahout fpg
>-i hdfs://master204:54310/user/root/testdata/T10I4D100K.dat
>-o hdfs://master204:54310/user/root/result
>-k 50
>-method mapreduce
>-regex '[ ]'
>-s 3
算法执行结束后,出现如下界面表示成功。

从图中可以看出,使用sequential方法执行的时间远远高于mapredue。
查看计算结果
Mahout的fpg算法成功运行后,计算机结果集以SequenceFile的形式存放于frequentpatterns的文件目录下,需要查看时运行命令:
mahout seqdumper
>-i hdfs://master204:54310/user/root/result/frequentpatterns/part-r-00000
>-c
其中,-c参数指统计结果记录的个数。seqdumper的参数如下图:

结果如下图:

分析计算结果
mahout seqdumper
>-i hdfs://master204:54310/user/root/result/frequentpatterns/part-r-00000
>-q
局部如下图:
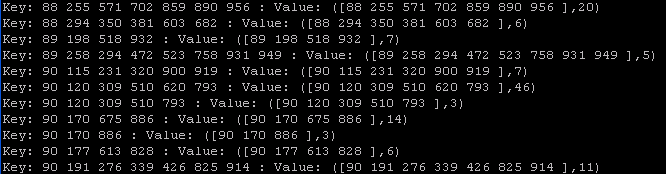
从上图可以看出,7阶大项集{88,255,571,702,589,890,956}的支持数为20,6阶大项集{88,294,350,381,603,682}的持数为6,可根据实际情况应用于相关领域。
最后
以上就是苹果康乃馨最近收集整理的关于Hadoop实战之路——第六章 数据挖掘利器Mahout的全部内容,更多相关Hadoop实战之路——第六章内容请搜索靠谱客的其他文章。








发表评论 取消回复