大数据概述
大数据的“大”是相对而言的,是指所处理的数据规模巨大到无法通过目前主流数据库软件工具,在可以接受的时间内完成抓取、储存、管理和分析,并从中提取出人类可以理解的资讯。
业界普遍认同大数据具有4个 V特征(数据量大Volume、变化速度快Velocity、多类型Variety与高价值Value)。简而言之,大数据可以被认为是数据量巨大且结构复杂多变的数据集合。
大数据的4V特征
第一个特征Volume是大数据的首要特征,数据体量巨大。当今世界需要进行及时处理以提取有用信息的数据数量级已经从TB级别,跃升到PB甚至EB级别。
**第二个特征Variety:**数据类型繁多。大数据的挑战不仅是数据量的大,也体现在数据类型的多样化。除了前文提到的网络日志、地理位置信息等具有固定结构的数据之外,还有视频、图片等非结构化数据。
**第三个特征Velocity:**处理速度快。信息的价值在于及时,超过特定时限的信息就失去了使用的价值。
**最后一个特征是Value:**商业价值高,但是价值密度低。单个数据的价值很低,只有大量数据聚合起来处理才能借助历史数据预测未来走势,体现出大数据计算的价值所在。
大数据存储平台
HDFS
HDFS(全称Hadoop Distributed File System)原是Apache开源项目Nutch的组件,现在成为是Hadoop的重要组件,它是一款具有高容错性特点的分布式文件系统,它被设计为可以部署在造价低廉的主机集群上。它将一个大文件拆分成固定大小的小数据块,分别存储在集群的各个节点上。因此HDFS可以存储超大的数据集和单个巨大的文件。这样的分布式结构能够进行不同节点的并行读取,提高了系统的吞吐率。同一个数据块存储在不同的数据节点上,保证了HDFS在节点失败时还能继续提供服务,使其具有了容错性。
HDFS副本策略
HDFS副本放置策略对于HDFS可靠性和性能至关重要。副本放置策略关系到数据的可靠性、可用性和网络带宽的利用率。对于副本放置策略的优化让HDFS在分布式文件系统中脱颖而出,这一调优是需要大量实践经验作为依托的。
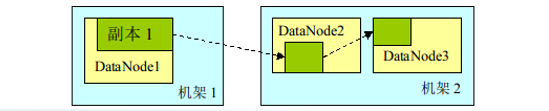
HDFS采用基于机架感知的副本放置策略,将副本存放在不同的机架上,即第一个副本放在客户本地节点上,另外两个副本随机放置在远程机架上,这样可以防止当某个机架失效时数据的丢失,在一个数据中心中往往不只有一个机架,对于大部分数据中心来说,不同机架上节点之间的通信需要经过多个交换机,其带宽比相同机架节点之间的通信带宽要小。因此,基于机架感知的副本放置策略可以在网络带宽和数据可靠性之间取得平衡。
HBase简介
Apache HBase是运行于Hadoop平台上的数据库,它是可扩展的、分布式的大数据储存系统。HBase可以对大数据进行随机而实时的读取和写入操作。它的目标是在普通的机器集群中处理巨大的数据表,数据表的行数和列数都可以达到百万级别。受到Google Bigtable 思想启发,Apache开发出HBase, HBase是一个开源的、分布式的、数据多版本储存的、面向列的大数据储存平台。Google的Bigtable是运行于GFS(Google File System)上的,而HBase是运行与Apache开发的Hadoop平台上。
HBase的特性
1)线性和模块化的扩展性;
2)严格的读写一致性;
3)自动且可配置的数据表分片机制;
4)RegionServer之间可以进行热备份切换;
5)为MapReduce操作HBase数据表提供方便JAVA基础类;
6)易用的JAVA客户端访问API;
7)支持实时查询的数据块缓存和模糊过滤;
8)提供Trift网关和REST-ful Web服务,并支持XML,Protobuf和二进制编码;
9)可扩展的Jrubyshell;
10)支持通过Hadoop检测子系统或JMX导出检测数据到文件、Ganglia集群检测系统。
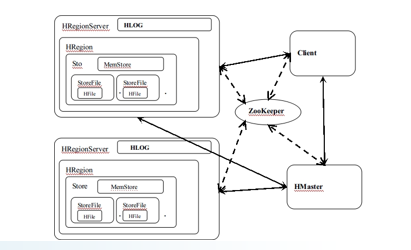
HBase体系架构
MongoDB
MongoDB简介
MongoDB 是一个面向集合的,模式自由的文档型数据库。
在数据库里每个聚集有一个唯一的名字,可以包含无限个文档。聚集是RDBMS中表的同义词,区别是聚集不需要进行模式定义。
MongoDB的功能及适用范围
功能
查询:基于查询对象或者类SQL语句搜索文档。查询结果可以排序,进行返回大小限制,可以跳过部分结果集,也可以返回文档的一部分。
插入和更新:插入新文档,更新已有文档。
索引管理:对文档的一个或者多个键(包括子结构)创建索引,删除索引等等。
常用命令:所有MongoDB 操作都可以通过socket传输的DB命令来执行。
适用范围
适合实时的插入,更新与查询
适合由数十或数百台服务器组成的数据库
网站数据
适合作为信息基础设施的缓存层
大尺寸,低价值的数据
用于对象及JSON数据的存储
大数据分析处理平台
Impala平台
Impala是CDH(Cloudera Distribution with Apache Hadoop)的一个组件,是一个对大量数据并行处理(MPP-Massively Parallel Processing)的查询引擎。
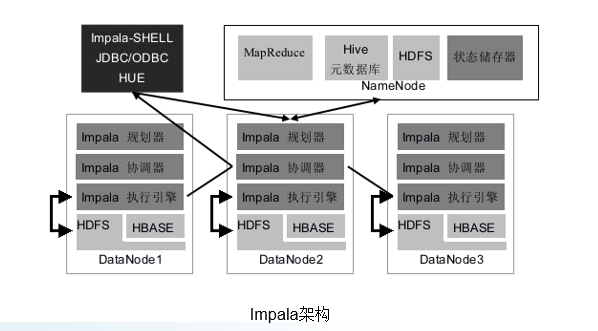
Impala基本架构
大数据研究和发展方向
数据的不确定性与数据质量
大数据的不确定性要求我们在处理数据时也要应对这种不确定性,包括数据的收集,存储、建模、分析都需要新的方法来应对
保证有效的数据不丢失,所以需要研究出一种新的计算模式,一种高效的计算模型和方法,这样数据的质量和数据的时效性才能有所保证。
跨领域的数据处理方法的可移植性
广泛吸纳其他研究领域的原理模型,然后进行有效的结合,从而提高大数据处理的效率。
### 跨领域的数据处理方法的可移植性
新型存储级内存 (storageclass memory, SCM) 器件设计成为新内存体系的一部分,而非作为虚拟内存交换区域的外存补充,计算不仅存在于传统的内存上,也在新型存储级内存上发生。
电阻存储器 、铁电存储器 、相变存储器等为代表的新兴非易失性随机存储介质 技术的发展,使得传统的内存与存储分离的界限逐渐变得模糊
新型存储介质的访问性能逐步逼近动态随机存取存储器 (dynamic random access memory, DRAM),但是其容量和单位价格却将远低于 DRAM。
以新型非易失型存储设备为基础构建混合内存体系以加速计算的模式,称为内存计算。
对于流式数据的实时处理
CluStream、D-Stream等框架
在资源状态信息的实时监控和调整、资源敏感策略的构建、聚类策略的调整等方面仍需要继续研究完善。
大数据应用
医学领域的大数据应用
临床决策支持系统
医疗数据透明度
医学图像挖掘
智能交通领域的大数据应用
提高交通运行效率。
提高交通安全水平。
提供环境监测方式。
智能电网领域的大数据应用
监测电力设备状态的数据挖掘
最后
以上就是沉默水池最近收集整理的关于大数据技术的全部内容,更多相关大数据技术内容请搜索靠谱客的其他文章。








发表评论 取消回复