*************
使用的工具:Matlab
分类器:SVM
*************
1、案例背景:
在葡萄酒制造业中,对于葡萄酒的分类具有很大意义,因为这涉及到不同种类的葡萄酒的存放以及出售价格,采用SVM做为分类器可以有效预测相关葡萄酒的种类,从UCI数据库中得到wine数据记录的是在意大利某一地区同一区域上三种不同品种的葡萄酒的化学成分分析,数据里含有178个样本分别属于三个类别(类别标签已给),每个样本含有13个特征分量(化学成分),将这178个样本50%做为训练样本,另50%做为测试样本,用训练样本对SVM分类器进行训练,用得到的模型对测试样本的进行分类标签预测,最终得到96.6292%的分类准确率. .....
2、模型的建立:

这只是一个简单的模型建立,其实我就觉得 叫“过程”更加的贴切
3、数据导入:
load chapter12_wine.mat;载入测试数据wine, 其中包含的数据为 classnumber = 3, wine:178*13的矩阵, 类型标签wine_labes:178*1的列向量
如图:
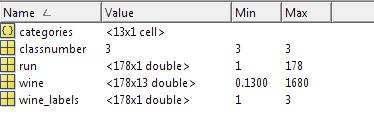
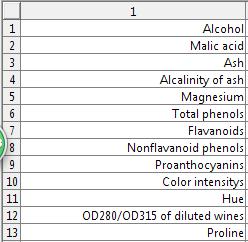
其中13个属性值分别为:酒精Alcohol、苹果酸Malic acid、灰分的碱度Alcalinity of ash、镁(元素)Magnesium、总酚含量Total phenols、黄酮类化合物flavanoids、酚Nonflavanoid phenols、原花青素proanthocyanins、色泽度color intensitys、色调hue、淡酒OD280/OD315 of diluted wines、脯氨酸proline
可以看到13个属性值在178样本中的分布情况:
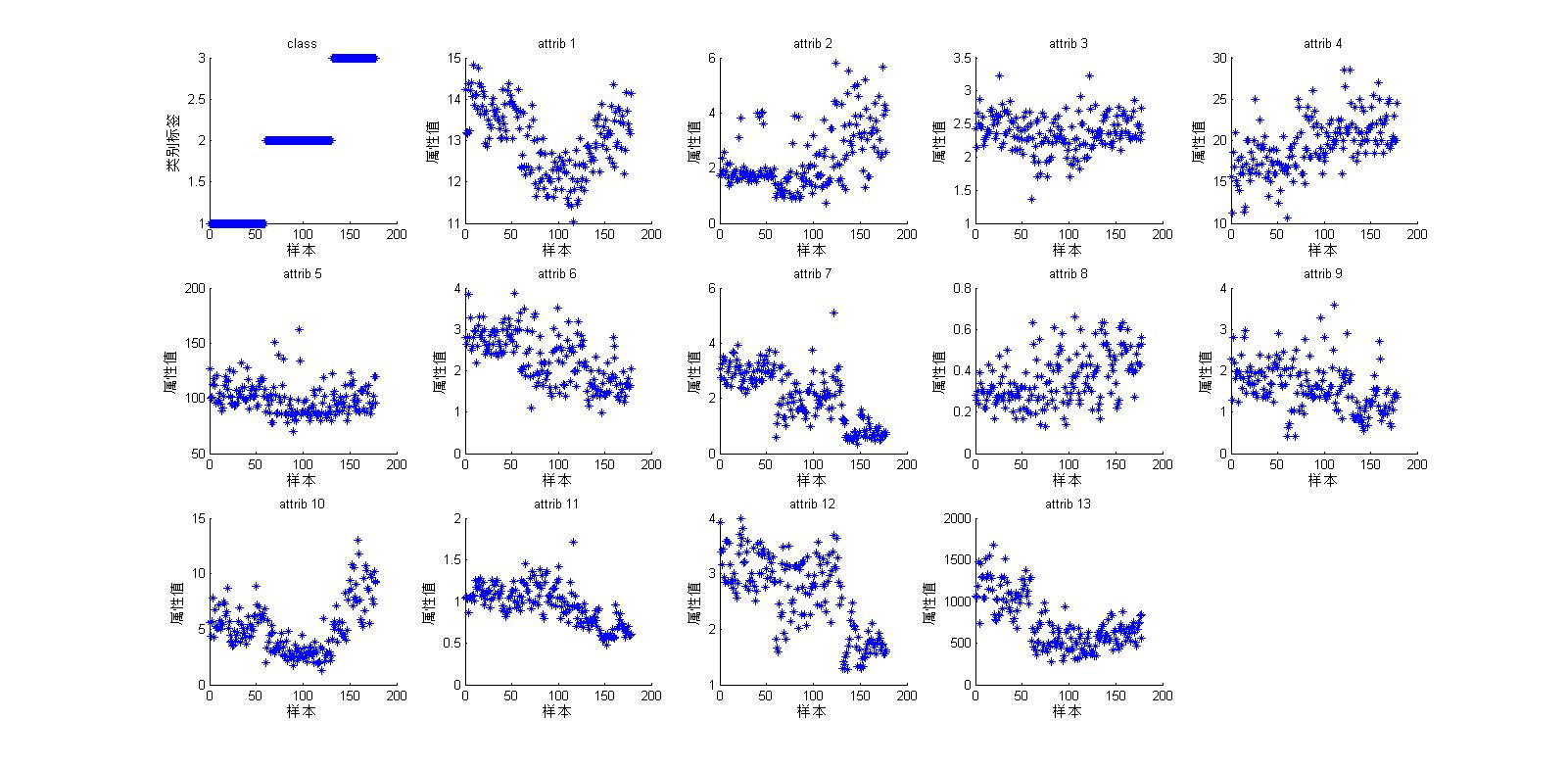
4、处理结果:
看出来,红色的预测和蓝色实际分类还是很吻合的,分类正确率还是很高的

5、附录:Matlab代码
% SVM神经网络的数据分类预测----意大利葡萄酒种类识别
%% 清空环境变量
close all;
clear;
clc;
format compact;
%% 数据提取
% 载入测试数据wine,其中包含的数据为classnumber = 3,wine:178*13的矩阵,wine_labes:178*1的列向量
load chapter12_wine.mat;
% 画出测试数据的box可视化图
figure;
boxplot(wine,'orientation','horizontal','labels',categories);
title('wine数据的box可视化图','FontSize',12);
xlabel('属性值','FontSize',12);
grid on;
% 画出测试数据的分维可视化图
figure
subplot(3,5,1);
hold on
for run = 1:178
plot(run,wine_labels(run),'*');
end
xlabel('样本','FontSize',10);
ylabel('类别标签','FontSize',10);
title('class','FontSize',10);
for run = 2:14
subplot(3,5,run);
hold on;
str = ['attrib ',num2str(run-1)];
for i = 1:178
plot(i,wine(i,run-1),'*');
end
xlabel('样本','FontSize',10);
ylabel('属性值','FontSize',10);
title(str,'FontSize',10);
end
% 选定训练集和测试集
% 将第一类的1-30,第二类的60-95,第三类的131-153做为训练集
train_wine = [wine(1:30,:);wine(60:95,:);wine(131:153,:)];
% 相应的训练集的标签也要分离出来
train_wine_labels = [wine_labels(1:30);wine_labels(60:95);wine_labels(131:153)];
% 将第一类的31-59,第二类的96-130,第三类的154-178做为测试集
test_wine = [wine(31:59,:);wine(96:130,:);wine(154:178,:)];
% 相应的测试集的标签也要分离出来
test_wine_labels = [wine_labels(31:59);wine_labels(96:130);wine_labels(154:178)];
%% 数据预处理
% 数据预处理,将训练集和测试集归一化到[0,1]区间
[mtrain,ntrain] = size(train_wine);
[mtest,ntest] = size(test_wine);
dataset = [train_wine;test_wine];
% mapminmax为MATLAB自带的归一化函数
[dataset_scale,ps] = mapminmax(dataset',0,1);
dataset_scale = dataset_scale';
train_wine = dataset_scale(1:mtrain,:);
test_wine = dataset_scale( (mtrain+1):(mtrain+mtest),: );
%% SVM网络训练
model = svmtrain(train_wine_labels, train_wine, '-c 2 -g 1');
%% SVM网络预测
[predict_label, accuracy] = svmpredict(test_wine_labels, test_wine, model);
%% 结果分析
% 测试集的实际分类和预测分类图
% 通过图可以看出只有一个测试样本是被错分的
figure;
hold on;
plot(test_wine_labels,'o');
plot(predict_label,'r*');
xlabel('测试集样本','FontSize',12);
ylabel('类别标签','FontSize',12);
legend('实际测试集分类','预测测试集分类');
title('测试集的实际分类和预测分类图','FontSize',12);
grid on;</span>
最后
以上就是丰富睫毛最近收集整理的关于数据挖掘之数据处理——SVM神经网络的数据分类预测-意大利葡萄酒种类识别的全部内容,更多相关数据挖掘之数据处理——SVM神经网络内容请搜索靠谱客的其他文章。








发表评论 取消回复