- 故障描述
近期,多个地市州的酒店用户频繁出现错误代码:10071故障
故障一:故障发生时间为早上6点至10点之间。
故障二:个别酒店在晚上(用户高峰期)会出现故障,服务时而正常,时而异常
- 故障原因
经排查(网络部路由跟踪,定位),故障原因基本定位在是由于酒店EPG服务器主备倒换后向上级网络设备上报新MAC地址与ip不匹配造成。经进一步的分析观察,发现欢旅服务器主备nginx早上6点到10点时间vip发生随机飘移现象,由于linux内核网络连接跟踪参数nf_conntrack设置不合理,线上设置参数为:
net.netfilter.nf_conntrack_buckets = 16384
net.netfilter.nf_conntrack_max = 65536
由于早高峰,用户并发过多导致网络连接数持续增加,超过最大网络跟踪数,导致 IP 包被丢掉,连接无法建立。
VIP:192.168.xx.9x
Nginx主机:192.168.xx.60
Nginx备机:192.168.xx.61
- 解决思路
查看业务服务器服务是否正常,正常的情况下,查看/var/log/messages日志,具体定位vip发生飘移情况。
同时查看nginx网络情况,netstat -s grep |reject
- 故障分析过程
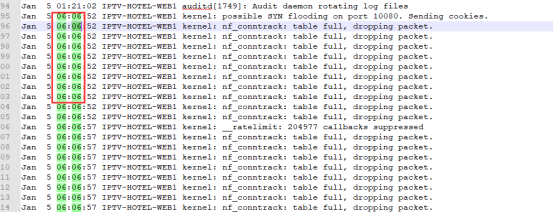
- 1月5日早,欢旅公司技术团队通过查看主备双机系统日志/var/log/messages发现,在早高峰时间段,发现大量错误日志:Jan 5 06:07:00 IPTV-HOTEL-WEB2 kernel: nf_conntrack: table full, dropping packet.
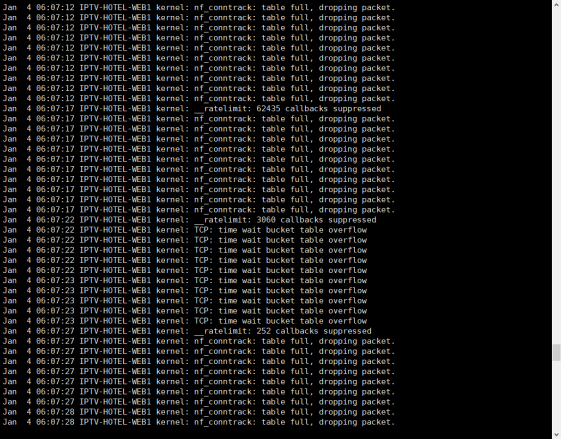
2021年07月20日60日志:
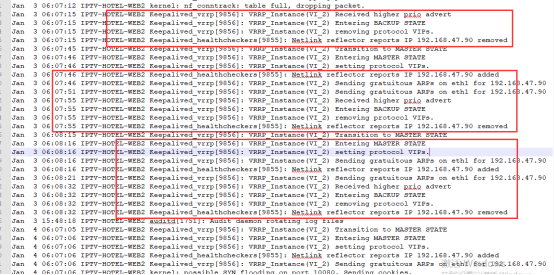
2021年07月26日60日志:
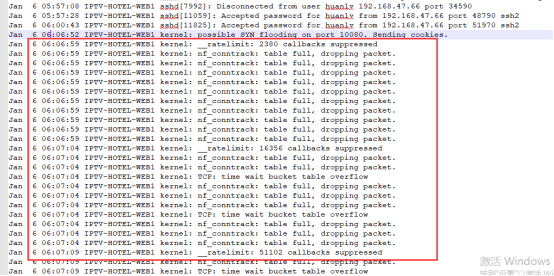
2021年07月28日61日志:
通过日志在6点07分发生大量请求,导致网络连接跟踪数陡增,超越最大值,发现VIP漂移发生飘移过程中,keeplived运行在抢占模式下VIP频繁切换,上图中可见,导致ARP没有及时广播给网关,即MAC地址和IP地址匹配错误。
VIP漂移的原因是连接跟踪模块Netfilter connection tracking(nf_conntrack)模块参数设置偏小,即:net.netfilter.nf_conntrack_max = 65536
查看方法:cat /proc/sys/net/netfilter/nf_conntrack_max
早高峰导致跟踪链接数超过了65536,
查看方法:cat /proc/sys/net/netfilter/nf_conntrack_count
同时,查看nginx网络情况,netstat -s grep |reject

发现出现了大量丢包。并且通过抓包发现,有部分请求拒绝了链接:

发现tcp链接直接失败,客户端连接服务器连接建立失败。
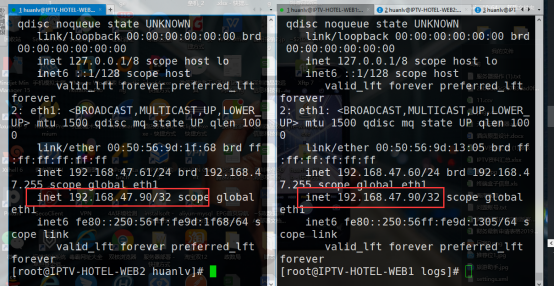
- 为了验证分析的结论,欢旅技术团队在测试环境,搭建了一套主备双机环境,通过设置linux内核参数,对线上问题进行重现,具体环境如下:
vip: 172.16.15.58
主:172.16.15.57
备:172.16.0.75
通过修改linux的内核参数:net.netfilter.nf_conntrack_max = 16384
- 在现有的环境下进行压力测试
模拟并发3000,一共50W次请求:
ab -c 3000 -n 500000 http://172.16.15.58/index.html
通过观察系统日志,发现与线上早高峰故障相同,如下所示:
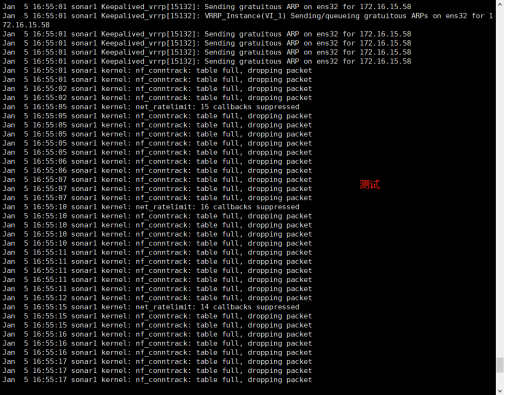
6日凌晨在生产环境下进行压力测试
ab -n 100000 -c 5000 http://110.190.92.10x:10080/iptv-interface/apk/queryIndex?stbId=hl1
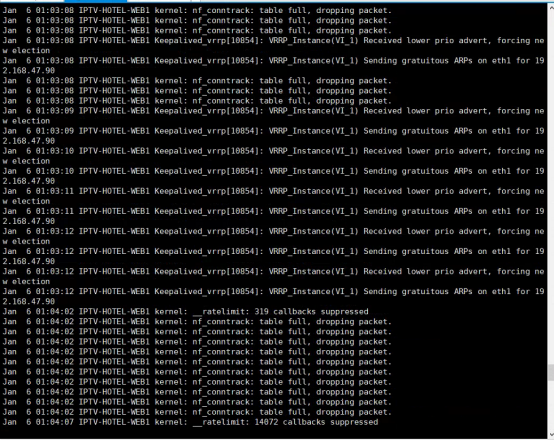
- 分析结果
Linux内核参数nf_conntrack 跟踪所有网络连接,记录存储在 1 个哈希表里。首先根据五元组算出哈希值,分配一个桶,如果有冲突就在链表上遍历,直到找到一个精确匹配的。如果没有匹配的则新建。
即使来自客户端的访问量过高会塞满哈希表。
连接记录会在哈希表里保留一段时间,根据协议和状态有所不同,直到超时都没有收发包就会清除记录。如果服务器比较繁忙,新连接进来的速度远高于释放的速度,把哈希表塞满了,新连接的数据包就会被丢掉。从而出现生产环境错误日志:Jan 5 06:07:00 IPTV-HOTEL-WEB2 kernel: nf_conntrack: table full, dropping packet.
通过tcp抓包分析,发现大量丢包,同事查看tcp连接数也比较高,所以查询资料发现和两阶段等待时间有关系,需要调整内核参数:
sysctl -w net.ipv4.tcp_tw_recycle=0
sysctl -w net.ipv4.tcp_timestamps=1
因为服务器同时开启了tcp_tw_recycle和timestamps,而客户端正是使用NAT来访问服务器,造成启动时间相对较短的客户端得不到服务器的正常响应。如果服务器作为服务端提供服务,且明确客户端会通过NAT网络访问,或服务器之前有7层转发设备会替换客户端源IP时,是不应该开启tcp_tw_recycle的,而timestamps除了支持tcp_tw_recycle外还被其他机制依赖,推荐继续开启。
- 解决方案
- 优化linux内核参数
为了防止vip不正常的浮动,将linux内核参数进行优化,优化项主要为:
- 哈希表扩容(nf_conntrack_buckets、nf_conntrack_max)
- 让里面的元素尽快释放(超时相关参数)
经过生产环境下的服务器内存为8G,按照linux的通用设置规则:CONNTRACK_MAX = RAMSIZE (in bytes) / 16384 / (ARCH / 32)
现有服务器参数设置为:对于生产环境下服务配置为 8G 内存的机器:(8 * 1024^3) / 16384 / (64 / 32) = 262144
sysctl net.netfilter.nf_conntrack_tcp_timeout_established=6000
#编辑文件vim /etc/sysctl.conf
,加入以下内容:
net.ipv4.tcp_fin_timeout = 30
#然后执行 /sbin/sysctl -p 让参数生效
最终linux网络连接追踪参数优化为:
net.netfilter.nf_conntrack_buckets = 131072
net.netfilter.nf_conntrack_max = 262144
net.netfilter.nf_conntrack_tcp_timeout_established = 6000
- 取消Keeplived服务抢占模式
- 添加上服务器状况监控
当VIP漂移或者服务故障的时候,通过邮件(短信)发送告警,从而在第一时间对故障进行处理。
- 调整时间戳内核参数配置
sysctl -w net.ipv4.tcp_tw_recycle=0
sysctl -w net.ipv4.tcp_timestamps=1
【引用别人博客】在一条正常的TCP流中,按序接收到的所有TCP数据包中的timestamp都应该是单调非递减的,这样就能判断那些timestamp小于当前TCP流已处理的最大timestamp值的报文是延迟到达的重复报文,可以予以丢弃
TIME_WAIT状态是TCP四次挥手中主动关闭连接的一方需要进入的最后一个状态,并且通常需要在该状态保持2*MSL(报文最大生存时间),它存在的意义有两个:
1.可靠地实现TCP全双工连接的关闭:关闭连接的四次挥手过程中,最终的ACK由主动关闭连接的一方(称为A)发出,如果这个ACK丢失,对端(称为B)将重发FIN,如果A不维持连接的TIME_WAIT状态,而是直接进入CLOSED,则无法重传ACK,B端的连接因此不能及时可靠释放。
2.等待“迷路”的重复数据包在网络中因生存时间到期消失:通信双方A与B,A的数据包因“迷路”没有及时到达B,A会重发数据包,当A与B完成传输并断开连接后,如果A不维持TIME_WAIT状态2*MSL时间,便有可能与B再次建立相同源端口和目的端口的“新连接”,而前一次连接中“迷路”的报文有可能在这时到达,并被B接收处理,造成异常,维持2*MSL的目的就是等待前一次连接的数据包在网络中消失。
TIME_WAIT状态的连接需要占用服务器内存资源维持,Linux内核提供了一个参数来控制TIME_WAIT状态的快速回收:tcp_tw_recycle,它的理论依据是:
在PAWS的理论基础上,如果内核保存Per-Host的最近接收时间戳,接收数据包时进行时间戳比对,就能避免TIME_WAIT意图解决的第二个问题:前一个连接的数据包在新连接中被当做有效数据包处理的情况。这样就没有必要维持TIME_WAIT状态2*MSL的时间来等待数据包消失,仅需要等待足够的RTO(超时重传),解决ACK丢失需要重传的情况,来达到快速回收TIME_WAIT状态连接的目的。
在多个客户端使用NAT访问服务器时会产生新的问题:同一个NAT背后的多个客户端时间戳是很难保持一致的(timestamp机制使用的是系统启动相对时间),对于服务器来说,两台客户端主机各自建立的TCP连接表现为同一个对端IP的两个连接,按照Per-Host记录的最近接收时间戳会更新为两台客户端主机中时间戳较大的那个,而时间戳相对较小的客户端发出的所有数据包对服务器来说都是这台主机已过期的重复数据,因此会直接丢弃。
- 实施预案
当vip浮动情况仍未得到改善后,先考录PlanB,实施单机策略,最终考虑实施planC,将现有的软负载替换为F5硬负载,从而从本源解决VIP发生浮动时,不能准确向上级网络设备上报对应的MAC地址。
PlanA:持续观察双机状况
PlanB:单机运行,去掉备机
PlanC: 硬负载实施
- 日服务器情况报告,VIP切换,内存,CPU
- 周EPG开发情况报告
参考一下博文:
https://blog.csdn.net/weixin_34221332/article/details/86081600?utm_medium=distribute.wap_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-4.withoutpaiwithsearchfrombaidu_wap&depth_1-utm_source=distribute.wap_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-4.withoutpaiwithsearchfrombaidu_wap
https://blog.csdn.net/weixin_34221332/article/details/86081600?utm_medium=distribute.wap_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-4.withoutpaiwithsearchfrombaidu_wap&depth_1-utm_source=distribute.wap_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-4.withoutpaiwithsearchfrombaidu_wap
https://blog.csdn.net/majianting/article/details/96476375
https://blog.csdn.net/majianting/article/details/96476375
最后
以上就是玩命钢笔最近收集整理的关于线上服务器故障报告的全部内容,更多相关线上服务器故障报告内容请搜索靠谱客的其他文章。








发表评论 取消回复