match对象属性和方法
在了解了正则常用表达式以及pattern对象属性和方法之后,继续总结match对象的方法属性以及分组相关的知识点。match对象是一次匹配后的结果,它包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。match对象的属性和方法如下:
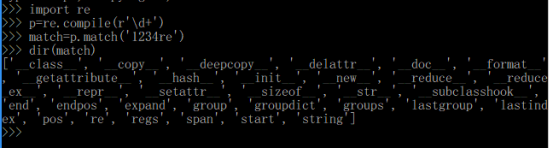
string属性
作用:获取匹配时使用的字符串对象
代码示例:
>>> m=re.match(r'(w+)! (w+)(?P<sign>.*)','Hi! gloryroad!')
>>> print(m.string)
Hi! gloryroad!
re属性
作用:获取匹配时使用的pattern对象,也就是匹配到内容的正则表达式对象
代码示例:
>>> m=re.match(r'(w+)! (w+)(?P<sign>.*)','Hi! gloryroad!')
>>> m.re
re.compile('(\w+)! (\w+)(?P<sign>.*)')

pos/endpos属性
作用:表示文本中正则表达式开始搜索/结束搜索的索引。值与pattern.match()和pattern.search()方法中的同名参数相同
代码示例:
#pos和endpos
m=re.match(r'(w+)! (w+)(?P<sign>.*)','Hi! gloryroad!')
print (m.pos)
print (m.endpos)

lastindex属性
作用:表示最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组将返回None
代码示例:lastindex
import re
#三个分组
m=re.match(r'(w+)! (w+)(?P<sign>.*)','Hi! gloryroad!')
print (m.lastindex)
#一个分组
m=re.match(r'w+! w+(?P<sign>.*)','Hi! gloryroad!')
print (m.lastindex)
#没有分组
m=re.match(r'w+! w+','Hi! gloryroad!')
print (m.lastindex)

lastgroup属性
作用:表示最后一个被捕获的分组别名,如果这个分组没有别名或者没有被捕获的分组返None.
代码示例:
import re
#1个命名分组
m=re.match(r'(w+)! (w+)(?P<sign>.*)','Hi! gloryroad!')
print (m.lastgroup)
#没有命名分组
m=re.match(r'w+! w+(.*)','Hi! gloryroad!')
print (m.lastgroup)
group()方法
group([group1, …])
作用:获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group可以使用编号也可以使用别名;编号0代表匹配的整个字符串;默认返回group(0);没有截获字符串的组返回None;截获了多次的则返回最后一次截获的子串
代码示例1:返回指定的分组
import re
p=re.compile('[a-z]+s(d)(w)')
matchResult = p.search("aa 1w31")
if matchResult:
#打印整个匹配结果
print (matchResult.group())#等价于print matchResult.group(0)
#打印第一个分组内容,也就是(d)括号中匹配的内容
print (matchResult.group(1))
#打印第二个分组内容,也就是(w)括号中匹配的内容
print (matchResult.group(2))
代码示例2:使用编号和名字引用分组
>>> re.search(r"(?P<num>d+)","123")
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>> re.search(r"(?P<num>d+)","123").group(1)#使用编号引用分组
'123'
>>> re.search(r"(?P<num>d+)","123").group("num")#使用名字引用分组
'123'
>>> re.search(r"(?P<num>d+) (?P=num)","123 123").group()#引用前面的命名分组
'123 123'
>>> re.search(r"(?P<num>d+) (?P=num)","123 123").group(1)
'123'
>>> re.search(r"(?P<num>d+) (?P=num)","123 456").group()#匹配的内容也必须一样
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
#按序号引用前面的命名分组时匹配的内容也必须完全一样
>>> re.search(r"(d+) 1","123 123").group(1)
'123'
>>> re.search(r"(d+) 1","123 456").group(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
代码示例3:分组嵌套
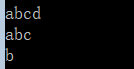
matchResult=re.search(r'(a(b)c)d','abcdefg')
print (matchResult.group())
print (matchResult.group(1))
print (matchResult.group(2))
>>> re.search(r"((d+) (d+))","123 456").group()
'123 456'
>>> re.search(r"((d+) (d+))","123 456").group(1)#最外面的括号代表的分组
'123 456'
>>> re.search(r"((d+) (d+))","123 456").group(2)
'123'
>>> re.search(r"((d+) (d+))","123 456").group(3)
'456'
>>> re.search(r"((d+) (d+))","123 456").group(2,3)
('123', '456')
代码示例4:group函数传多个参数
import re
p = re.compile('(a(b)c)d')
m = p.match('abcd')
print(m.group(1,2,1))
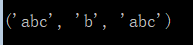
groups()方法
groups([default=None])
作用:以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…,last).没有截获字符串的组以None代替
代码示例:
import re
print('n')
p = re.compile('[a-z]+s(d)(w)')
m = p.match("aa 1w31")
if m:
print (m.groups())
print (m.group(1,2))
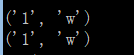
start()方法
start([group=0])
作用:返回指定的组截获的子串在string中的起始索引(子串的第一个字符索引)。默认为第1组
代码示例:
import re
m=re.search(r'(w+)! (w+) (w+)','HMan! gloryroad train')
#表示第一个分组被匹配的字符串位置索引
print (m.start(1))
#表示第二个分组被匹配的字符串位置索引
print (m.start(2))
#表示第三个分组被匹配的字符串位置索引
print (m.start(3))
#默认情况
print (m.start())

end()方法
end([group=0])
作用:返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引),group的默认值为0,表示最后一组
代码示例:
import re
print('n')
m=re.search(r'(w+)! (w+) (w+)','*HMan! gloryroad train')
#表示第一个分组被匹配的字符串位置索引
print (m.end(1))
#表示第二个分组被匹配的字符串位置索引
print (m.end(2))
#表示第三个分组被匹配的字符串位置索引
print (m.end(3))
#默认情况
print (m.end(0))

span()方法
作用:以元组的形式返回(start(group),end(group)),即某个分组的匹配内容在被匹配字符串中的开始索引和结束索引组成的元组
代码示例:
import re
m=re.search(r'(w+)! (w+) (w+)','HMan! gloryroad train')
print (m.span(1))

expand(template)方法
作用:将匹配到的分组带入template中然后返回。template可以使用id或g、g引用分组,但不能使用编号0。id与g是等价的;但10将被认为是第10个分组,如果想表达1之后是字符’0’,只能使用g<1>0。
代码示例:格式化输出
m=re.search(r'(w+)! (w+) (w+)','HMan! gloryroad train')
#将匹配的结果带入
print(m.expand(r'resut:3 2 1'))

groupdict([default=None])方法
作用:将所有匹配到并且指定了别名的分组,以别名为key,匹配到的字符串为value存于字典中,然后返回这个字典。如果表达式中未设置别名分组,就会返回一个空字典。
代码示例:
line='This is the last one'
res=re.match(r'(?P<g1>.*) is (?P<g2>.*?) .*', line, re.M|re.I)
groupDict=res.groupdict()
if groupDict:
print (groupDict)
else:
print ('无别名分组')

正则的贪婪性
前面已经提到过正则的贪婪行,本节重点介绍以下。点(.)表示除换行符以外的任意一个字符,星号()表示的是匹配签名一个字符0次1次或多次,这个两个符号一起使用表示匹配除换行符以外的任意多个字符,也就是说(.)组合时,他们会尽可能多的去匹配满足条件的字符,这就是(.*)的贪婪性
代码示例1:.匹配除n外的任意一个字符
>>> print(re.match(r'.*',".*abd526/?n").group())
.*abd526/?
代码示例2:匹配.本身
try:
m = re.match(r'.*..','...').group()
except AttributeError as e:
print('匹配失败')
else:
print('匹配结果为:',m)
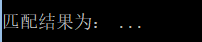
代码示例3:
try:
m = re.match(r'.*...','..').group()
except AttributeError as e:
print('匹配失败')
else:
print('匹配结果为:',m)

说明:只有当正则表达式中要匹配的字符数小于等于原字符串中的字符数时,才有可能匹配成功。并且’.’在匹配的过程中会回溯,先匹配0次,如果整个表达式匹配成功,再匹配一次;如果还能匹配,那就匹配两次,这样一次次试下去,直到不能匹配成功时,返回最近一次匹配成功的结果,这就是’.’的贪婪性。
在点星(.)后面加上一个问号(?),表示匹配签名匹配的字符串0次或1次,这样就可以将点星(.)的贪婪性暂时屏蔽。注意(?)不只是在(.)后面是抑制贪婪性,跟在数量词后面({m}/{m,n}/+/)都起到抑制贪婪性的作用
代码示例5:抑制贪婪性
line = "this a134gwordgtest"
#未屏蔽.*的贪婪性
res1=re.match(r'.*a.*g',line,re.M|re.I)
print (res1.group())
#屏蔽.*的贪婪性
res2=re.match(r'.*a.*?g',line,re.M|re.I)
print (res2.group())
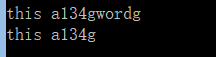
说明:从上面的实例可以看出,在未屏蔽点星(.)的贪婪性时,匹配到元字符串中第二个g字符处了,第二个点星(.)匹配了“134gword”。加了问号(?)屏蔽点星(.)的贪婪性后,第二个点星(.)只匹配了“134”,最后一个g字符匹配了g字符。
代码示例6:抑制贪婪性的特例
>>> print(re.match(r"d*?","123")) #用问号抑制贪婪,*最小是0次匹配
<_sre.SRE_Match object; span=(0, 0), match=''>
>>> print(re.match(r"d+?","123"))#用问号抑制贪婪,+最小是1次匹配
<_sre.SRE_Match object; span=(0, 1), match='1'>
正则表达式的修饰符
正则表达式可以包含一些可选标志修饰符来控制匹配模式。修饰符被指定为一个可选的标志,用在正则表达式处理函数中的flag参数中。多个标志可以通过使用按位或运算符“|“来指定它们,表示同时生效。如: re.I | re.M被设置成I和M标志
修饰符 描述
re.I 全写(re.IGNORECASE),表示使匹配时,忽略大小写
re.L 全写(re.LOCALE),使预定字符类 w W b B s S 取决于当前区域设定
re.M 全写(re.MULTILINE),多行匹配,影响 ^ 和 $的行为
re.S 全写(re.DOTALL),使点(.)匹配包括换行在内的所有字符
re.U 全写(re.UNICODE),根据Unicode字符集解析字符。这个标志影响w W b B s S d D
re.X 全写(re.VERBOSE),该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
re.I的实例
表示忽略大小写匹配
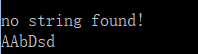
代码示例:#默认情况下,要匹配小写字母,但是字符串以大写西门开头,匹配失败
p=re.compile('[a-z]+')
m =p.match('AAb12GFH3ab')
if m :
print (m.group())
else:
print ("no string found!")
#使用re.I忽略大小写,匹配成功
p=re.compile('[a-z]+',re.I)
m=p.match('AAbDsd123ab')
if m:
print (m.group())
else:
print ("no string found!" )
re.M的实例
多行匹配,影响 ^ 和 $的行为
代码示例1:
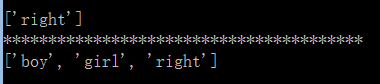
#默认情况下,未使用re.M,会匹配多行文字的最后一行的结尾
p=re.compile('[a-z]+$')
string="""I am a boy
you r a beautiful girl
right"""
m = p.findall(string)#将字符串看着一个整体,所以找到的是最后一个right
if m:
print (m)
else:
print ("no string found!")
#使用re.M,会匹配每行结尾,也多行匹配
print ('*'*40)
p=re.compile('[a-z]+$',re.M)
string="""I am a boy
you r a beautiful girl
right"""
m = p.findall(string)
if m:
print (m)
else:
print ("no string found!")
代码示例2:re.I | re.M结合使用 ,匹配出所有的行
p=re.compile('^.*[a-z]+$',re.M|re.I)
string="""I am a Boy
you r a beautiful girl
right"""
m = p.findall(string)
if m:
print (m)
else:
print ("no string found!")
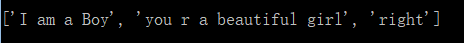
re.S的实例
全写(re.DOTALL),使点(.)匹配包括换行在内的所有字符
代码示例:re.I | re.S结合使用 ,将多行字符串当作一行
p=re.compile('^.*[a-z]+$',re.S|re.I)
string="""I am a Boy
you r a beautiful girl
right"""
m = p.findall(string)
if m:
print (m)
else:
print ("no string found!")

re.X的实例
这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
代码示例:
a = re.compile(r"""d+ # 匹配至少1个连续的数字,自定义注释
. # 匹配点(.)
d* # 匹配数字至少0个""", re.X)
b = re.compile(r"d+.d*") #a和b的正则表达式等价的
print(a.search("test12.58 2.0 abc 3.8").group())

无名分组
就是用一对圆括号()括起来的正则表达式,匹配出的内容就表示一个分组。从正则表达式左边开始看,看到的第一个左括号’(’表示第一个分组,第二个表示第二个分组,以此类推。需要注意的是,有一个隐含的全局分组(就是索引为0的分组),就是整个表达式匹配的结果。
代码示例:取代码中的超链接中的文本
s = u'<div><a href="https://support.google.com/chrome/?p=ui_hotword_search" target="_blank">更多</a><p>dfsl</p></div>'
print(re.search(r'<a.*>(w+)</a>',s).group(1))
print(re.search(r'<a.*>(.*)</a>',s).group(1))
print(re.match(r'.*<a.*>(w+)</a>.*',s).group(1))

有名分组
就是给具体有默认分组编号的组另外再起一个别名,方便以后引用
命名分组的语法格式为:
(?P正则表达式)
P必须大写,name是一个合法发标识符,表示分组的别名
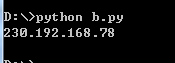
代码示例1:提取字符串中的IP地址
s="ip='230.192.168.78',version='1.0.0'"
print(re.search(r'(?P<IP>d{1,3}.d{1,3}.d{1,3}.d{1,3})',s).group(1))#通过序号引用
print(re.search(r'(?P<IP>d{1,3}.d{1,3}.d{1,3}.d{1,3})',s).group('IP'))#通过名字引用
代码示例2: 多个命名分组
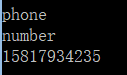
m=re.search(r'(?P<last>w+),(?P<first>w+),(?P<phone>S+)',"phone,number,15817934235")
#使用命名分组获取第一个分组的内容
print (m.group('last'))
#使用命名分组获取第二个分组的内容
print (m.group('first'))
#使用命名分组获取第三个分组的内容
print (m.group('phone'))
后向引用
正则表达式中放在圆括号‘()’中的表示一个分组。我们就可以对整个组使用一些正则操作,比如重复操作符。要注意的是,只有圆括号‘()’才能用于形成分组,” ”用于定义字符串,而‘{ }’用于定义重复操作。
当用‘()’定义了一个正则表达式分组后,正则引擎就会把匹配的组按照顺序进行编号,然后存入缓存中。这样我们就可以在后面对已经匹配过的内容进行引用,这就叫后向引用。后向引用语法:
- 通过索引引用
数字
1表示引用第一个分组,2引用第二个分组,以此类推,n引用第n个组,而�则表示引用整个被匹配的正则表达式本身。 - 通过命名分组名进行引用(如果有的话)
(?P=name)
字符P必须是大写的P,name表示命名分组的分组名。
注意:
这些引用都必须是在正则表达式中才有效,用于匹配一些重复的字符串;
后面的(?P=name)只是分组1即(?P[a-z]+)的引用,并不是分组2,?P=name 不是等于[a-z]+,而是等于前面分组匹配到的内容,引用分组匹配的内容必须要与分组1的内容完全相同,否则匹配不到;
代码示例:
#通过默认分组编号进行后向引用
s = 'aaa111aaatestaaa'
print (re.findall(r'([a-z]+)d+(1).*(1)',s))#注意匹配的内容也必须完全一致
#通过命名分组进行后向引用
res = re.search(r'(?P<name>go)s+(?P=name)s+(?P=name)', 'go go go')
print (res.group())
print (res.group('name'))
按序号和按别名引用分组时匹配的内容不一致时会匹配失败
>>> s = 'aaa111aaatestaaa'
>>> re.findall(r'(?P<name>[a-z]{3}).*(?P=name).*(?P=name)',s)
['aaa']
>>> re.findall(r'([a-z]{3}).*(1).*(1)',s)
[('aaa', 'aaa', 'aaa')]
>>> s = 'aaa111aabtestaaa'
>>> re.findall(r'(?P<name>[a-z]{3}).*(?P=name).*(?P=name)',s)
[]
>>> re.findall(r'([a-z]{3}).*(1).*(1)',s)
[]
前向肯定断言和后向肯定断言
前向肯定断言的语法:
(?<=pattern)
前向肯定断言表示你希望匹配的字符串前面是pattern匹配的内容时才匹配。但是不输出前向肯定表达式匹配的内容
后向肯定断言的语法:
(?=pattern)
后向肯定断言表示你希望匹配的字符串的后面是pattern匹配的内容时才匹配,但是不输出后向肯定表达式匹配的内容
如果在一次匹配过程中,需要同时用到前向肯定断言和后向肯定断言时,那你必须将前向肯定断言表达式写在要匹配的正则表达式的前面,而后向肯定断言表达式写在你要匹配的字符串的后面,表示后向肯定模式之后,前向肯定模式之前。
代码示例1:获取C语言代码中的注释内容
'''c语言的注释中的内容是包含在’/*’和’*/’之间,并不希望匹配的结果把’/*’和’*/’也包括进来'''
s ='''char *a="hello world"; char b='c'; /* this is comment */ int c=1; /* this is multiline comment */'''
print(re.findall(r'(?<=/*).+?(?=*/)',s))

前向肯定断言括号中的正则表达式必须是能确定长度的正则表达式,比如w{3},而不能写成w*或者w+或者w?等这种不确定个数的正则表达式。
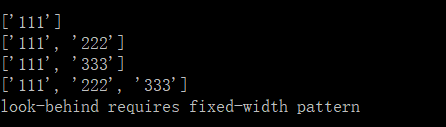
代码示例2:搜索字符串中连续的数字的字符串
s = 'aaa111aaa , bbb222 , 333ccc'
# 指定前后肯定断言
print(re.findall(r'(?<=[a-z]{3})d+(?=[a-z]{3})',s))
# 指定前向肯定断言
print(re.findall(r'(?<=[a-z]{3})d+',s))
# 指定后向肯定断言
print(re.findall(r'd+(?=[a-z]{3})',s))
#普通方法
print(re.findall(r'[a-z]*(d+)[a-z]*',s))
# 下面是一个错误的实例
try:
m = re.findall(r'(?<=[a-z]+)d+(?=[a-z]+)',s)
except Exception as e:
print(e)
else:
print(m)
代码示例3:
前向肯定
>>> re.search(r"((?<=abc)d+)","abc123deb")
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re.search(r"((?<=abc)d+)","abc123deb").group()
'123'
后向肯定
>>> re.search(r"(d+(?=abc))","xbc123abc").group()
'123'
>>> re.search(r"(?<=xbc)(d+(?=abc))","xbc123abc").group()
'123'
前向否定断言和后向否定断言
前向否定断言的语法:
(?<!pattern)
前向否定断言表示你希望匹配的字符串的前面不是pattern匹配的内容时才匹配。但是不输出前向肯定表达式匹配的内容
后向否定断言的语法:
(?!pattern)
后向否定断言表示你希望匹配的字符串后面不是pattern匹配的内容时才匹配。但是不输出后向否定表达式匹配的内容
跟前向肯定断言一样,前向否定断言括号中的正则表达式必须是能确定长度的正则表达式,比如w{3},而不能写成w*或者w+或者w?等这种不能确定个数的正则模式符。
代码示例:前向否定断言和后向否定断言
s = 'aaa111aaa , bbb222 , 333ccc'
# 指定前后否定断言,不满足前三个字母和后三个字母的条件
print(re.findall(r'(?<![a-z]{3})d+(?![a-z]{3})',s))
# 指定前向否定断言
print(re.findall(r'(?<![a-z]{3})d+',s))
# 指定后向否定断言
print(re.findall(r'd+(?![a-z]{3})',s))
# 下面是一个错误的实例
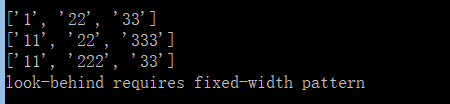
try:
m = re.findall(r'(?<![a-z]+)d+',s)
except Exception as e:
print(e)
else:
print(m)
代码示例:前向否定断言和后向否定断言
前向否定
>>> re.search(r"(?<!xbc)d+","abc123abc").group()#前面的字母不是xbc
'123'
>>> re.search(r"(?<!xbc)d+","xbc123abc").group()
'23'
>>> re.search(r"(?<!xbc)d+?","xbc123abc").group()
'2'
后向否定:
>>> re.search(r"d+(?!xbc)","123abc").group()
'123'
>>> re.search(r"d+(?!xbc)","123xbc").group()
'12'
最后
以上就是诚心芹菜最近收集整理的关于python3基础:正则(三)match对象属性和方法正则的贪婪性正则表达式的修饰符无名分组有名分组后向引用前向肯定断言和后向肯定断言前向否定断言和后向否定断言的全部内容,更多相关python3基础:正则(三)match对象属性和方法正则内容请搜索靠谱客的其他文章。








发表评论 取消回复