数据处理
记录在处理数据阶段用到的代码块及其拓展。
主要使用pandas库
1. 文件路径
(1) os库
import os
os.getcwd() # 获取当前文件路径
os.path.dirname(os.getcwd()) # 获取上一级文件路径
os.path.join(os.path.dirname(os.getcwd()),'test') # 建立同级文件
# 先获取上级目录,然后通过join函数来把同级的目录test拼进来。
os.listdir() # 获取当前目录下所有文件名
path = 'F:/pics'
os.path.dirname(path) # 输出:'F:/'
os.listdir(path) # 输出:['abc.jpg']
os.path.join(os.path.dirname(path),'test') # 输出:'F:/test'
(2) 相对路径
# / :表示当前路径的根路径。
# ./ :表示当前路径。
# ../ :表示父级路径,当前路径所在的上一级路径。
2. 文件读取
(1) 单个文件读取或输出
import pandas as pd
df1 = pd.read_csv("文件地址文件名称.csv",header=0,index_col=0,usecols=[1,2,3]) # 指定表头、序号列、使用的列
df2 = pd.read_excel("文件地址文件名称.xls/xlsx",sheetname=0,header=0,index_col=0) # 指定读取的sheet
df1.to_csv("文件地址文件名称.csv")
df2.to_excel("文件地址文件名称.xls")
(2) 批量读取文件处理框架:
一层嵌套
import os
import pandas as pd
read_path = '输入文件地址'
output_path = '输出文件地址'
def read_files(read_path,output_path):
files = os.listdir(read_path) # 顺序读取read_path下的所有文件夹名称
for file in files:
# 读取单个文件内容
df = pd.read_csv(read_path+"\"+file,header=0,index_col=0)
# 文件处理
# 输出文件保存到指定路径下
df.to_csv(output_path + "\" + file)
print("文件处理完毕")
两层嵌套
# 批量读取数据以及进行数据提取
def deal_files():
# 顺序读取read_path下的所有文件名称
files = os.listdir(read_path)
# print(files)
for file_name in files:
# print(file_name)
# 读取单个文件
print("正在处理:" + file_name)
# 读取文件下面的文件
file = os.listdir(read_path+"\"+file_name)
# print(file)
# 创建一个存储目录
path = output_path + "\" + file_name
os.mkdir(path) # 创建目录
for wj in file:
# print(wj)
df = pd.read_csv(read_path+"\"+file_name+'\'+wj,header=0,index_col=0)
# 数据处理
...
# 输出文件保存到指定路径下
df.to_csv(path + "\"+ wj)
print("ok")
print("文件处理完毕")
(3) 把两个excel写入到一个文件中
with pd.ExcelWriter('sheet.xlsx') as writer:
df1.to_excel(writer, sheet_name='sheet1')
df2.to_excel(writer, sheet_name='sheet2')
3. DataFrame
# pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
(1) 创建
① 由字典创建
d = {'col1': ['A','B'], 'col2': [1,2]}
pd.DataFrame(data=d)
# 输出:
col1 col2
0 A 1
1 B 2
pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}})
# 输出:
A B C
0 a 1 2
1 b 3 4
2 c 5 6
data = {'col_1': [3, 2, 1, 0], 'col_2': ['a', 'b', 'c', 'd']}
pd.DataFrame.from_dict(data) # 默认键名是列名
# 输出:
col_1 col_2
0 3 a
1 2 b
2 1 c
3 0 d
data = {'row_1': [3, 2, 1, 0], 'row_2': ['a', 'b', 'c', 'd']}
pd.DataFrame.from_dict(data, orient='index') # 键名作为index
# 输出:
0 1 2 3
row_1 3 2 1 0
row_2 a b c d
pd.DataFrame.from_dict(data, orient='index',
columns=['A', 'B', 'C', 'D'])
# 输出:
A B C D
row_1 3 2 1 0
row_2 a b c d
② 由包含Series的字典创建
d = {'col1': [0, 1, 2, 3], 'col2': pd.Series([2, 3], index=[2, 3])}
pd.DataFrame(data=d, index=[0, 1, 2, 3])
# 输出:
col1 col2
0 0 NaN
1 1 NaN
2 2 2.0
3 3 3.0
③ 由numpy数组创建
import numpy as np
pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]),
columns=['a', 'b', 'c'])
# 输出:
a b c
0 1 2 3
1 4 5 6
2 7 8 9
④ 直接创建
pd.DataFrame([['a1','a2'],['b1','b2']], columns=['A','B'])
# 输出:
A B
0 a1 a2
1 b1 b2
(2) 数据选取
df.loc 最好用
1)行(列)选取(单维度选取):df[] 只能选取行或者列
df[ ] 可以用切片取多行或一行(dataframe);可以取一列(series)
df[[ ]] 可以取多列、一列(dataframe),不能用切片
2)区域选取(多维选取):df.loc[],df.iloc[]
df.loc[] 取单行或单列,Series
df.loc[:, ] 可切片取多列,可用list取多列
df.loc[ ,:] 可切片取多行,可用list取多行
df.loc[[ ]] 可以取单行、多行,Dataframe,用index不可以切片
可定位、可赋值
3)单元格选取(点选取):df.at[],df.iat[]
整数索引切片是前闭后开,标签索引切片是前闭后闭
一个[]取一个,是series
两个[]取一个,是dataframe,里面的[]是一个列表
参考
① df[] # 取列/行
df = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=['a', 'b', 'c', 'd'],
)
df['A'] # Series,取列
# 输出:
a A0
b A1
c A2
d A3
Name: A, dtype: object
df.A # 同df['A']
# 输出:
a A0
b A1
c A2
d A3
Name: A, dtype: object
df[['A']] # DataFrame,取列
# 输出:
A
a A0
b A1
c A2
d A3
df[['A','C']] # # DataFrame,取多列
# 输出:
A C
a A0 C0
b A1 C1
c A2 C2
d A3 C3
df[0:2] # 取行,按序号前闭后开
# 输出:
A B C D
a A0 B0 C0 D0
b A1 B1 C1 D1
df['a':'c'] # 取行,按名称前闭后闭,index是int型不适用
# 输出:
A B C D
a A0 B0 C0 D0
b A1 B1 C1 D1
c A2 B2 C2 D2
② pandas.DataFrame.loc # 用名称
df = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
# df:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
df.loc[0] # Series,取单行
# 输出:
A A0
B B0
C C0
D D0
Name: 0, dtype: object
df.loc[[0]] # DataFrame,取单行
# 输出:
A B C D
0 A0 B0 C0 D0
df.loc[[0,2]] # DataFrame,取多行
# 输出:
A B C D
0 A0 B0 C0 D0
2 A2 B2 C2 D2
df.loc[0,'A'] # 取值
# 输出:
'A0'
df.loc[0,'A':'C'] # 取某行,切片
# 输出:
A A0
B B0
C C0
Name: 0, dtype: object
df.loc[:,'A':'B'] # 取某列,切片
# 输出:
A B
0 A0 B0
1 A1 B1
2 A2 B2
3 A3 B3
df.loc[df['A'] == 'A0'] # 定位,也可以用>,<
# 输出:
A B C D
0 A0 B0 C0 D0
df.loc[[1],['A']] = 'a' # 赋值
# 输出:
A B C D
0 A0 B0 C0 D0
1 a B0 C0 D0
2 A2 B2 C2 D2
3 A3 B3 C3 D3
df.loc[1,'B'] = 'B' # 赋值
# 输出:
A B C D
0 A0 B0 C0 D0
1 a B C0 D0
2 A2 B2 C2 D2
3 A3 B3 C3 D3
③ pandas.DataFrame.iloc # 用整数
# 用法与pandas.DataFrame.loc 相同
df = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
df.iloc[3,2] # 取值
# 输出:
'C3'
④ pandas.DataFrame.at 和 pandas.DataFrame.iat 取单个值
df = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
df.at[0,'A']
df.iat[0,0]
# 输出:
'A0'
'A0'
⑤ DataFrame.isin(values) 取特定值所在的行/列
'''
DataFrame.isin(values)
values: iterable, Series, DataFrame or dict
'''
df = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
# 输出:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
df[df['A'].isin(['A0'])]
# 输出:
A B C D
0 A0 B0 C0 D0
df[df['A'].isin(['A0','A3'])]
# 输出:
A B C D
0 A0 B0 C0 D0
3 A3 B3 C3 D3
已知特定行/列的序号或行名/列名→list,for循环读取,合并/存入新文件
⑥ DataFrame.filter() 根据索引标签划分子集
'''
DataFrame.filter(items=None, like=None, regex=None, axis=None)
'''
df = pd.DataFrame(np.array(([1, 2, 3], [4, 5, 6])),
index=['mouse', 'rabbit'],
columns=['one', 'two', 'three'])
# df:
one two three
mouse 1 2 3
rabbit 4 5 6
df.filter(items=['one', 'three']) # select columns by name
# 输出:
one three
mouse 1 3
rabbit 4 6
df.filter(regex='e$', axis=1) # select columns by regular expression
# 输出:
one three
mouse 1 3
rabbit 4 6
df.filter(like='bbi', axis=0) # select rows containing 'bbi'
# 输出:
one two three
rabbit 4 5 6
⑦ DataFrame.get() 选取列
'''
DataFrame.get(key, default=None)
Get item from object for given key (ex: DataFrame column).
Returns default value if not found.
'''
df = pd.DataFrame(np.array(([1, 2, 3], [4, 5, 6])),
index=['mouse', 'rabbit'],
columns=['one', 'two', 'three'])
df.get(['one','two'])
# 输出:
one two
mouse 1 2
rabbit 4 5
df.get('one')
# 输出:
mouse 1
rabbit 4
Name: one, dtype: int32
df.get(['four'],"没有")
# 输出:'没有'
⑧ DataFrame.select_dtypes() 根据列的数据类型返回子集
'''
DataFrame.select_dtypes(include=None, exclude=None)
To select all numeric types, use np.number or 'number'
To select strings you must use the object dtype, but note that this will return all object dtype columns
To select datetimes, use np.datetime64, 'datetime' or 'datetime64'
To select timedeltas, use np.timedelta64, 'timedelta' or 'timedelta64'
To select Pandas categorical dtypes, use 'category'
To select Pandas datetimetz dtypes, use 'datetimetz' (new in 0.20.0) or 'datetime64[ns, tz]'
numpy dtype hierarchy:https://numpy.org/doc/stable/reference/arrays.scalars.html
'''
df = pd.DataFrame({'a': [1, 2] * 3,
'b': [True, False] * 3,
'c': [1.0, 2.0] * 3})
df
# 输出:
a b c
0 1 True 1.0
1 2 False 2.0
2 1 True 1.0
3 2 False 2.0
4 1 True 1.0
5 2 False 2.0
df.dtypes
# 输出:
a int64
b bool
c float64
dtype: object
df.select_dtypes(include='bool')
# 输出:
b
0 True
1 False
2 True
3 False
4 True
5 False
df.select_dtypes(exclude='bool')
# 输出:
a c
0 1 1.0
1 2 2.0
2 1 1.0
3 2 2.0
4 1 1.0
5 2 2.0
(3) 合并df
① pandas.DataFrame.join 列合并
无index时:
'''
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)
加入另一个 DataFrame 的列;在索引或键列上将列与其他 DataFrame 连接。
'''
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'],
'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2'],
'B': ['B0', 'B1', 'B2']})
df1.join(df2) # 会报错
df1.join(df2, lsuffix='_1', rsuffix='_2') # 列加后缀
# 输出:
key_1 A key_2 B
0 K0 A0 K0 B0
1 K1 A1 K1 B1
2 K2 A2 K2 B2
3 K3 A3 NaN NaN
4 K4 A4 NaN NaN
5 K5 A5 NaN NaN
df1.set_index('key').join(df2.set_index('key')) # 使用键列连接
# 输出:
A B
key
K0 A0 B0
K1 A1 B1
K2 A2 B2
K3 A3 NaN
K4 A4 NaN
K5 A5 NaN
df1.join(df2.set_index('key'), on='key') # 根据相同列合并
# 输出:
key A B
0 K0 A0 B0
1 K1 A1 B1
2 K2 A2 B2
3 K3 A3 NaN
4 K4 A4 NaN
5 K5 A5 NaN
print(df2.set_index('key')) # 将某列设为index
# 输出:
key B
K0 B0
K1 B1
K2 B2
df1 = pd.DataFrame({'字母': ['A','B'], '数字': [1,2]})
df2 = pd.DataFrame({'英文': ['one','two']})
df1.join(df2)
# 输出:
字母 数字 英文
0 A 1 one
1 B 2 two
有index时:
df1 = pd.DataFrame({'字母': ['A','B'], '数字': [1,2]})
df2 = pd.DataFrame({'英文': ['one','two']},index=['a','b'])
df1.join(df2,how='right') # 使用哪个df的索引
# 输出:
字母 数字 英文
a NaN NaN one
b NaN NaN two
left = pd.DataFrame(
{"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]}, index=["K0", "K1", "K2"]
)
right = pd.DataFrame(
{"C": ["C0", "C2", "C3"], "D": ["D0", "D2", "D3"]}, index=["K0", "K2", "K3"]
)
left.join(right)
# 输出:
A B C D
K0 A0 B0 C0 D0
K1 A1 B1 NaN NaN
K2 A2 B2 C2 D2
right.join(left)
# 输出:
C D A B
K0 C0 D0 A0 B0
K2 C2 D2 A2 B2
K3 C3 D3 NaN NaN
left.join(right, how="inner")
# 输出:
A B C D
K0 A0 B0 C0 D0
K2 A2 B2 C2 D2
left.join(right, how="outer")
# 输出:
A B C D
K0 A0 B0 C0 D0
K1 A1 B1 NaN NaN
K2 A2 B2 C2 D2
K3 NaN NaN C3 D3
② pandas.DataFrame.merge 列合并
'''
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
how:{‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, default ‘inner’ 合并的类型
on:Column or index level names to join on, 两个df中都要有的列,默认是都有的列
left_on/right_on:左侧/右侧DataFrame中用于连接键的列名
suffixes:后缀
'''
df1 = pd.DataFrame({'akey': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'],
'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
df2 = pd.DataFrame({'bkey': ['K0', 'K1', 'K2'],
'B': ['B0', 'B1', 'B2']})
df1.merge(df2) # 报错
df1.merge(df2, left_on='akey', right_on='bkey')
# 输出:
akey A bkey B
0 K0 A0 K0 B0
1 K1 A1 K1 B1
2 K2 A2 K2 B2
df1 = pd.DataFrame({'akey': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'],
'v': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
df2 = pd.DataFrame({'bkey': ['K0', 'K1', 'K2'],
'v': ['B0', 'B1', 'B2']})
df1.merge(df2, left_on='akey', right_on='bkey') # 默认添加后缀_x,_y
# 输出:
akey v_x bkey v_y
0 K0 A0 K0 B0
1 K1 A1 K1 B1
2 K2 A2 K2 B2
df1.merge(df2, left_on='akey', right_on='bkey',suffixes=('_left', '_right')) # 自己添加后缀形式
# 输出:
akey v_left bkey v_right
0 K0 A0 K0 B0
1 K1 A1 K1 B1
2 K2 A2 K2 B2
df1 = pd.DataFrame({'a': ['foo', 'bar'], 'b': [1, 2]})
df2 = pd.DataFrame({'a': ['foo', 'baz'], 'c': [3, 4]})
df1.merge(df2, how='inner') # 只保留主键一致的行
# 输出:
a b c
0 foo 1 3
df1.merge(df2, how='outer') # 全部保留,空值填充
# 输出:
a b c
0 foo 1.0 3.0
1 bar 2.0 NaN
2 baz NaN 4.0
df1.merge(df2, how='left') # 左边b列是全的,右边c列有空值补全
# 输出:
a b c
0 foo 1 3.0
1 bar 2 NaN
df1.merge(df2, how='right') # 右边c列是全的,左边b列有空值补全
# 输出:
a b c
0 foo 1.0 3
1 baz NaN 4
df1.merge(df2, how='cross')
# 输出:
a_x b a_y c
0 foo 1 foo 3
1 foo 1 baz 4
2 bar 2 foo 3
3 bar 2 baz 4
df1 = pd.DataFrame({'a': ['foo', 'bar'], 'b': [1, 2], 'c': [3, 4]})
df2 = pd.DataFrame({'a': ['foo', 'baz'], 'b': [3, 4], 'c': [3, 4]})
df1.merge(df2, how='outer', on='a')
# 输出:
a b_x c_x b_y c_y
0 foo 1.0 3.0 3.0 3.0
1 bar 2.0 4.0 NaN NaN
2 baz NaN NaN 4.0 4.0
df1.merge(df2, how='outer', on='b')
# 输出:
a_x b c_x a_y c_y
0 foo 1 3.0 NaN NaN
1 bar 2 4.0 NaN NaN
2 NaN 3 NaN foo 3.0
3 NaN 4 NaN baz 4.0
参考:pandas.DataFrame.merge的用法
③ pandas.DataFrame.append # 行合并
'''
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=False)
'''
df1 = pd.DataFrame({'a': ['foo', 'bar'], 'b': [1, 2], 'c': [3, 4]})
df2 = pd.DataFrame({'a': ['foo', 'baz'], 'b': [3, 4], 'c': [3, 4]})
df1.append(df2)
# 输出:
a b c
0 foo 1 3
1 bar 2 4
0 foo 3 3
1 baz 4 4
df1.append(df2, ignore_index=True)
# 输出:
a b c
0 foo 1 3
1 bar 2 4
2 foo 3 3
3 baz 4 4
# 新建一列,并填充数据
df = pd.DataFrame(columns=['A'])
for i in range(5):
df = df.append({'A': i}, ignore_index=True)
# 输出:
A
0 0
1 1
2 2
3 3
4 4
参考:merge,join and concat
④ pandas.merge 列合并
具体的就看参考链接吧~
'''
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
'''
left = pd.DataFrame(
{"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]}, index=["K0", "K1", "K2"]
)
right = pd.DataFrame(
{"C": ["C0", "C2", "C3"], "D": ["D0", "D2", "D3"]}, index=["K0", "K2", "K3"]
)
pd.merge(left, right, left_index=True, right_index=True, how="outer")
# 输出:
A B C D
K0 A0 B0 C0 D0
K1 A1 B1 NaN NaN
K2 A2 B2 C2 D2
K3 NaN NaN C3 D3
# 和left.join(right, how="outer")的输出相同
pd.merge(left, right, left_index=True, right_index=True, how="inner")
# 输出:
A B C D
K0 A0 B0 C0 D0
K2 A2 B2 C2 D2
# 和left.join(right, how="inner")的输出相同
⑤ pandas.concat 行列都可
'''
pandas.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)
pandas.concat(objs, # 合并对象
axis=0, # 合并方向,默认是0纵轴方向
join='outer', # 合并取的是交集inner还是并集outer
ignore_index=False, # 合并之后索引是否重新
keys=None, # 在行索引的方向上带上原来数据的名字;主要是用于层次化索引,可以是任意的列表或者数组、元组数据或者列表数组
levels=None, # 指定用作层次化索引各级别上的索引,如果是设置了keys
names=None, # 行索引的名字,列表形式
verify_integrity=False, # 检查行索引是否重复;有则报错
sort=False, # 对非连接的轴进行排序
copy=True # 是否进行深拷贝
)
'''
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
df2 = pd.DataFrame(
{
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
},
index=[4, 5, 6, 7],
)
df3 = pd.DataFrame(
{
"A": ["A8", "A9", "A10", "A11"],
"B": ["B8", "B9", "B10", "B11"],
"C": ["C8", "C9", "C10", "C11"],
"D": ["D8", "D9", "D10", "D11"],
},
index=[8, 9, 10, 11],
)
pd.concat([df1, df2, df3])
# 输出:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
result = pd.concat([df1, df2, df3], keys=["x", "y", "z"])
# 输出:
A B C D
x 0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
y 4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
z 8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
result.loc["y"]
# 输出:
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
df2 = pd.DataFrame(
{
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
},
index=[2, 3, 6, 7],
)
pd.concat([df1, df2], axis=1).reindex(df1.index) # 使用df1的index
# 输出:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
df2 = pd.DataFrame(
{
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
}
)
df3 = pd.DataFrame(
{
"A": ["A8", "A9", "A10", "A11"],
"B": ["B8", "B9", "B10", "B11"],
"C": ["C8", "C9", "C10", "C11"],
"D": ["D8", "D9", "D10", "D11"],
}
)
pd.concat([df1, df2, df3],ignore_index=True)
# 输出:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
pd.concat([df1, df2, df3],axis=1)
# 输出:
A B C D A B C D A B C D
0 A0 B0 C0 D0 A4 B4 C4 D4 A8 B8 C8 D8
1 A1 B1 C1 D1 A5 B5 C5 D5 A9 B9 C9 D9
2 A2 B2 C2 D2 A6 B6 C6 D6 A10 B10 C10 D10
3 A3 B3 C3 D3 A7 B7 C7 D7 A11 B11 C11 D11
(4) 插入列
'''
DataFrame.insert(loc, column, value, allow_duplicates=False)
在特定位置插入列
'''
df = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
"E": ["A0", "A1", "A2", "A3"]
}
)
df.insert(0,'new_A',[1,0,0, 100])
# df:
new_A A B C D E
0 1 A0 B0 C0 D0 A0
1 0 A1 B1 C1 D1 A1
2 0 A2 B2 C2 D2 A2
3 100 A3 B3 C3 D3 A3
df.insert(3,'A',[1,0,0, 100],allow_duplicates=True)
# df:
new_A A B A C D E
0 1 A0 B0 1 C0 D0 A0
1 0 A1 B1 0 C1 D1 A1
2 0 A2 B2 0 C2 D2 A2
3 100 A3 B3 100 C3 D3 A3
(5) 列分割
df = pd.DataFrame([['2015-02-04 04:05:00'],['2015-02-04 04:05:05'],['2015-02-04 04:05:10']],columns=['time'])
# df:
time
0 2015-02-04 04:05:00
1 2015-02-04 04:05:05
2 2015-02-04 04:05:10
t = df['time'].str.split(' ',expand=True)
# t:
0 1
0 2015-02-04 04:05:00
1 2015-02-04 04:05:05
2 2015-02-04 04:05:10
适用于时间、带单位的数据分割
(6) 删除行/列
'''
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False) # 删除重复行
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) # 删除缺失值
'''
① DataFrame.drop()
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(12).reshape(3, 4),
columns=['A', 'B', 'C', 'D'])
# df:
A B C D
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
# 删除列
df.drop(['B','C'],axis=1)
# 输出:
A D
0 0 3
1 4 7
2 8 11
df.drop(columns=['B','C'])
# 输出:
A D
0 0 3
1 4 7
2 8 11
# 删除行
df.drop([1,2],axis=0)
# 输出:
A B C D
0 0 1 2 3
# 删除行列
df.drop(index=[2],columns=['B','C'])
# 输出:
A D
0 0 3
1 4 7
② DataFrame.drop_duplicates() 只能删除重复行,利用转置删除重复列
'''
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
Parameters
subset:column label or sequence of labels, optional
用于判断重复项的列
keep:{‘first’, ‘last’, False}, default ‘first’
保留哪一项
- first : Drop duplicates except for the first occurrence.
- last : Drop duplicates except for the last occurrence.
- False : Drop all duplicates.
inplace:bool, default False
是否返回copy:Whether to drop duplicates in place or to return a copy.
ignore_index:bool, default False
index重排
'''
df = pd.DataFrame(
[["A0", "A1", "A2", "A3"],["B0", "B1", "B2", "B3"],["C0", "C1", "C2", "C3"], ["D0", "D1", "D2", "D3"],["A0", "A1", "A2", "A3"]],
columns=[0, 1, 2, 3]
)
# df:
0 1 2 3
0 A0 A1 A2 A3
1 B0 B1 B2 B3
2 C0 C1 C2 C3
3 D0 D1 D2 D3
4 A0 A1 A2 A3
df.drop_duplicates()
# 输出:
0 1 2 3
0 A0 A1 A2 A3
1 B0 B1 B2 B3
2 C0 C1 C2 C3
3 D0 D1 D2 D3
# 可以利用转置,删除重复列
df = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
"E": ["A0", "A1", "A2", "A3"]
}
)
# df:
A B C D E
0 A0 B0 C0 D0 A0
1 A1 B1 C1 D1 A1
2 A2 B2 C2 D2 A2
3 A3 B3 C3 D3 A3
df_new = df.T
# df_new:
0 1 2 3
A A0 A1 A2 A3
B B0 B1 B2 B3
C C0 C1 C2 C3
D D0 D1 D2 D3
E A0 A1 A2 A3
df1 = df_new.drop_duplicates()
# df1:
0 1 2 3
A A0 A1 A2 A3
B B0 B1 B2 B3
C C0 C1 C2 C3
D D0 D1 D2 D3
df2 = df1.T
# df2:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
③ DataFrame.pop() 使用列名,只能删除一列
'''
DataFrame.pop(item)
item: label
Label of column to be popped. # 使用列名,只能删除一列
返回:删除的列Series
'''
df = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
"E": ["A0", "A1", "A2", "A3"]
}
)
df.pop('A')
# 输出:
0 A0
1 A1
2 A2
3 A3
Name: A, dtype: object
df
# df:
B C D E
0 B0 C0 D0 A0
1 B1 C1 D1 A1
2 B2 C2 D2 A2
3 B3 C3 D3 A3
④ delete 删除列
df = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
"E": ["A0", "A1", "A2", "A3"]
}
)
del df['A']
# 输出:
B C D E
0 B0 C0 D0 A0
1 B1 C1 D1 A1
2 B2 C2 D2 A2
3 B3 C3 D3 A3
⑤ isin() 删除含有特定值的行/列
df[df['有效'].isin(['否'])] # 取df中‘有效’列为‘否’的行
df[-df['有效'].isin(['否'])] # 取df中‘有效’列不为‘否’的行,取反
(7) 缺失值处理
① DataFrame.isna()和DataFrame.isnull() 缺失值检测
NA values, such as None or numpy.NaN
# ① DataFrame.isna() # 空值检测
# NA values, such as None or numpy.NaN
df = pd.DataFrame(dict(age=[5, 6, np.NaN],
born=[pd.NaT, pd.Timestamp('1939-05-27'),
pd.Timestamp('1940-04-25')],
name=['Alfred', 'Batman', ''],
toy=[None, 'Batmobile', 'Joker']))
df
# df:
age born name toy
0 5.0 NaT Alfred None
1 6.0 1939-05-27 Batman Batmobile
2 NaN 1940-04-25 Joker
df.isna()
# 输出:
age born name toy
0 False True False True
1 False False False False
2 True False False False
# DataFrame.isnull() .isna()的别名
# 非缺失值值检测
DataFrame.notna()
DataFrame.notnull()
df[df['XX'].isnull()] # 筛选某列中的空值
df[~df['XX'].isnull()] # 筛选某列中的非空值
df[df['XX'].notnull()] # 筛选非空值
df.dropna(subset=['XX']) # 筛选非空值
含空值相关的数据筛选
② DataFrame.dropna() 删除缺失值
# ② DataFrame.dropna() # 删除缺失值
'''
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
axis:{0 or ‘index’, 1 or ‘columns’}, default 0
0, or ‘index’ : Drop rows which contain missing values.
1, or ‘columns’ : Drop columns which contain missing value.
how:{‘any’, ‘all’}, default ‘any’
Determine if row or column is removed from DataFrame, when we have at least one NA or all NA.
‘any’ : If any NA values are present, drop that row or column.
‘all’ : If all values are NA, drop that row or column.
thresh:int, optional
Require that many non-NA values.
subset:column label or sequence of labels, optional
Labels along other axis to consider, e.g. if you are dropping rows these would be a list of columns to include.
inplace:bool, default False
If True, do operation inplace and return None.
'''
df.dropna(axis=0, how='any', subset=None, inplace=True)
③ DataFrame.fillna() 缺失值填充
'''
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None
pad / ffill: propagate last valid observation forward to next valid
backfill / bfill: use next valid observation to fill gap.
'''
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, np.nan],
[np.nan, 3, np.nan, 4]],
columns=list("ABCD"))
df
# 输出:
A B C D
0 NaN 2.0 NaN 0.0
1 3.0 4.0 NaN 1.0
2 NaN NaN NaN NaN
3 NaN 3.0 NaN 4.0
df.fillna(0)
# 输出:
A B C D
0 0.0 2.0 0.0 0.0
1 3.0 4.0 0.0 1.0
2 0.0 0.0 0.0 0.0
3 0.0 3.0 0.0 4.0
df.fillna(method="ffill") # 用前一个值填充
# 输出:
A B C D
0 NaN 2.0 NaN 0.0
1 3.0 4.0 NaN 1.0
2 3.0 4.0 NaN 1.0
3 3.0 3.0 NaN 4.0
df.fillna(method="bfill") # 用后一个值填充
# 输出:
A B C D
0 3.0 2.0 NaN 0.0
1 3.0 4.0 NaN 1.0
2 NaN 3.0 NaN 4.0
3 NaN 3.0 NaN 4.0
values = {"A": 0, "B": 1, "C": 2, "D": 3}
df.fillna(value=values) # 用给定的值填充
# 输出:
A B C D
0 0.0 2.0 2.0 0.0
1 3.0 4.0 2.0 1.0
2 0.0 1.0 2.0 3.0
3 0.0 3.0 2.0 4.0
df.fillna(value=values, limit=1) # 仅填充第一个
# 输出:
A B C D
0 0.0 2.0 2.0 0.0
1 3.0 4.0 NaN 1.0
2 NaN 1.0 NaN 3.0
3 NaN 3.0 NaN 4.0
df2 = pd.DataFrame(np.zeros((4, 4)), columns=list("ABCE"))
# df2:
A B C E
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
df.fillna(df2) # 使用表填充,填充相同的index和columns
④ nan的判断
import numpy as np
type(np.nan) # float
a = np.nan
print(a==np.nan)
# False
np.isnan(a)
# True
# 如果nan类型为<class 'numpy.float64'>
# 判断:math.isnan()
df.at[i,'Amap_loc'] = 'XX' # 字符串型
np.isnan(df.at[i,'Amap_loc'])
# 报错:
TypeError: ufunc 'isnan' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
# 修改:
pd.isna(df.at[i,'Amap_loc'])
(8) 数据类型转换
'''
pandas.DataFrame.dtypes # 输出数据类型
pandas.DataFrame.select_dtypes(include=None, exclude=None) # 根据列的数据类型返回子集
pandas.to_numeric(arg, errors='raise', downcast=None)
pandas.to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False, utc=None, format=None, exact=True, unit=None, infer_datetime_format=False, origin='unix', cache=True)
pandas.to_timedelta(arg, unit=None, errors='raise')
DataFrame.astype(dtype, copy=True, errors='raise') # 强制转换
DataFrame.convert_dtypes(infer_objects=True, convert_string=True, convert_integer=True, convert_boolean=True, convert_floating=True) # 使用支持 pd.NA 的 dtypes 将列转换为可能的最佳 dtypes。
'''
# 时间类型转换
df = pd.DataFrame({'year': [2015, 2016],
'month': [2, 3],
'day': [4, 5]})
pd.to_datetime(df)
# 输出:
0 2015-02-04
1 2016-03-05
dtype: datetime64[ns]
pd.to_datetime(1490195805, unit='s')
# 输出:
Timestamp('2017-03-22 15:16:45')
pd.to_datetime('2015-02-04 4:05')
# 输出:
Timestamp('2015-02-04 04:05:00')
df = pd.DataFrame([['2015.02.04 04:05:00'],['2015-02-04 4:5:5'],['2015-02-04 04:05:10']],columns=['time'])
# 时间为字符串格式,不可直接求时间差
# df:
time
0 2015.02.04 04:05:00
1 2015-02-04 4:5:5
2 2015-02-04 04:05:10
df['time']=pd.to_datetime(df['time'],format="%Y-%m-%d %H:%M:%S") # 格式转换
# df:
time
0 2015-02-04 04:05:00
1 2015-02-04 04:05:05
2 2015-02-04 04:05:10
(9) 排序
'''
DataFrame.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, ignore_index=False, key=None) # 按index/columns的名称
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None) # Sort DataFrame by the value.
'''
① DataFrame.sort_index() # 按行名/列名
df = pd.DataFrame({
'col1': ['A', 'A', 'B', np.nan, 'D', 'C'],
'col4': [2, 1, 9, 8, 7, 4],
'col3': [0, 1, 9, 4, 2, 3],
'col2': ['a', 'B', 'c', 'D', 'e', 'F']},
index = [3,4,5,2,6,8])
df.sort_index()
# 输出:
col1 col4 col3 col2
2 NaN 8 4 D
3 A 2 0 a
4 A 1 1 B
5 B 9 9 c
6 D 7 2 e
8 C 4 3 F
df.sort_index(axis=1)
# 输出:
col1 col2 col3 col4
3 A a 0 2
4 A B 1 1
5 B c 9 9
2 NaN D 4 8
6 D e 2 7
8 C F 3 4
② DataFrame.sort_values() # 按某行/列的值
df = pd.DataFrame({
'col1': ['A', 'A', 'B', np.nan, 'D', 'C'],
'col2': [2, 1, 9, 8, 7, 4],
'col3': [0, 1, 9, 4, 2, 3],
'col4': ['a', 'B', 'c', 'D', 'e', 'F']
})
# df:
col1 col2 col3 col4
0 A 2 0 a
1 A 1 1 B
2 B 9 9 c
3 NaN 8 4 D
4 D 7 2 e
5 C 4 3 F
df.sort_values(by=['col1']) # 按一列排序
# 输出:
col1 col2 col3 col4
0 A 2 0 a
1 A 1 1 B
2 B 9 9 c
5 C 4 3 F
4 D 7 2 e
3 NaN 8 4 D
df.sort_values(by=['col1', 'col2']) # 按两列排序
# 输出:
col1 col2 col3 col4
1 A 1 1 B
0 A 2 0 a
2 B 9 9 c
5 C 4 3 F
4 D 7 2 e
3 NaN 8 4 D
df.sort_values(by='col1', ascending=False) # 降序
# 输出:
col1 col2 col3 col4
4 D 7 2 e
5 C 4 3 F
2 B 9 9 c
0 A 2 0 a
1 A 1 1 B
3 NaN 8 4 D
df.sort_values(by='col1', ascending=False, na_position='first') # 缺失值放在最前面
# 输出:
col1 col2 col3 col4
3 NaN 8 4 D
4 D 7 2 e
5 C 4 3 F
2 B 9 9 c
0 A 2 0 a
1 A 1 1 B
(10) 行列命名、设置索引
'''
名称:
DataFrame.index
DataFrame.columns
重命名:
DataFrame.rename(mapper=None, *, index=None, columns=None, axis=None, copy=True, inplace=False, level=None, errors='ignore')
DataFrame.rename_axis(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False)
DataFrame.set_axis(labels, axis=0, inplace=False) # 可以通过分配类似列表或索引来更改列或行标签的索引。
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False) # 使用现有列设置DataFrame索引。
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='') # 重置index
特殊:
'''
① DataFrame.index和DataFrame.columns # 直接更改
df = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]})
df.index=[2,3,4]
# df:
A B
2 1 4
3 2 5
4 3 6
df.columns=['a','b']
# df:
a b
2 1 4
3 2 5
4 3 6
② DataFrame.rename() # 更改某行/某列名
df = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]})
df.rename(columns={"A": "a", "B": "c"})
# 输出:
a c
0 1 4
1 2 5
2 3 6
df.rename(index={0: "x", 1: "y", 2: "z"})
# 输出:
A B
x 1 4
y 2 5
z 3 6
df.rename(str.lower, axis='columns')
# 输出:
a b
0 1 4
1 2 5
2 3 6
df.rename({1: 2, 2: 4}, axis='index')
# 输出:
A B
0 1 4
2 2 5
4 3 6
③ DataFrame.rename_axis() # 更改总的行/列的名称, 更适用于多级标题
df = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]})
df.rename_axis('数字',axis='index')
# 输出:
A B
数字
0 1 4
1 2 5
2 3 6
df.rename_axis('字母',axis='columns')
# 输出:
字母 A B
0 1 4
1 2 5
2 3 6
df = pd.DataFrame({"num_legs": [4, 4, 2],
"num_arms": [0, 0, 2]},
["dog", "cat", "monkey"])
# 输出:
num_legs num_arms
dog 4 0
cat 4 0
monkey 2 2
df.index = pd.MultiIndex.from_product([['mammal'],
['dog', 'cat', 'monkey']],
names=['type', 'ani_name'])
# df:
num_legs num_arms
type ani_name
mammal dog 4 0
cat 4 0
monkey 2 2
df.rename_axis(index={'type': 'class'})
# df:
num_legs num_arms
class ani_name
mammal dog 4 0
cat 4 0
monkey 2 2
④ DataFrame.set_axis() 更改列或行标签的索引
df = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]})
df.set_axis(['a', 'b', 'c'], axis='index')
A B
a 1 4
b 2 5
c 3 6
df.set_axis(['I', 'II'], axis='columns')
I II
0 1 4
1 2 5
2 3 6
df.set_axis(['i', 'ii'], axis='columns', inplace=True)
df
i ii
0 1 4
1 2 5
2 3 6
⑤ DataFrame.set_index() 设置索引,支持多级
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale': [55, 40, 84, 31]})
df.set_index('month')
# 输出:
year sale
month
1 2012 55
4 2014 40
7 2013 84
10 2014 31
df.set_index(['year', 'month'])
# 输出:
sale
year month
2012 1 55
2014 4 40
2013 7 84
2014 10 31
df.set_index([pd.Index([1, 2, 3, 4]), 'year'])
# 输出:
month sale
year
1 2012 1 55
2 2014 4 40
3 2013 7 84
4 2014 10 31
⑥ DataFrame.reset_index() index更新
适用于删除某些行后更新index的序号,1,2,3…
'''
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
'''
df = pd.DataFrame({
'col1': ['A', 'A', 'B', np.nan, 'D', 'C'],
'col4': [2, 1, 9, 8, 7, 4],
'col3': [0, 1, 9, 4, 2, 3],
'col2': ['a', 'B', 'c', 'D', 'e', 'F']},
index = [3,4,5,2,6,8])
df.reset_index(drop=True,inplace=False)
# 输出:
col1 col4 col3 col2
0 A 2 0 a
1 A 1 1 B
2 B 9 9 c
3 NaN 8 4 D
4 D 7 2 e
5 C 4 3 F
df1 = df.reset_index(drop=True,inplace=True)
df 排序了,同上输出
df1 NoneType
df.reset_index(inplace=True) # 多了一行index,新序号正确
df.reset_index(drop=True) # 没有多,但是序号不对
df.reset_index(drop=True,inplace=True) # 正确结果
pandas reset_index
⑦ DataFrame.reindex() 重排/填充/扩展数据
# DataFrame.reindex() 使用可选的填充逻辑使 Series/DataFrame 符合新索引
'''
DataFrame.reindex(labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=nan, limit=None, tolerance=None)
a. 可以改变行或列的排序方式
b. 填充NaN值
c. 扩展数据
'''
# https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.reindex.html
(11) 数据统计
① 最值、均值、众数、方差等
pandas.DataFrame.min()
pandas.DataFrame.max()
pandas.DataFrame.mode()
pandas.DataFrame.median()
pandas.DataFrame.mean()
pandas.DataFrame.std()
pandas.DataFrame.sum()
...
df = pd.DataFrame([('bird', 2, 2),
('mammal', 4, np.nan),
('arthropod', 8, 0),
('bird', 2, np.nan)],
index=('falcon', 'horse', 'spider', 'ostrich'),
columns=('species', 'legs', 'wings'))
df
species legs wings
falcon bird 2 2.0
horse mammal 4 NaN
spider arthropod 8 0.0
ostrich bird 2 NaN
# 0→列,1→行
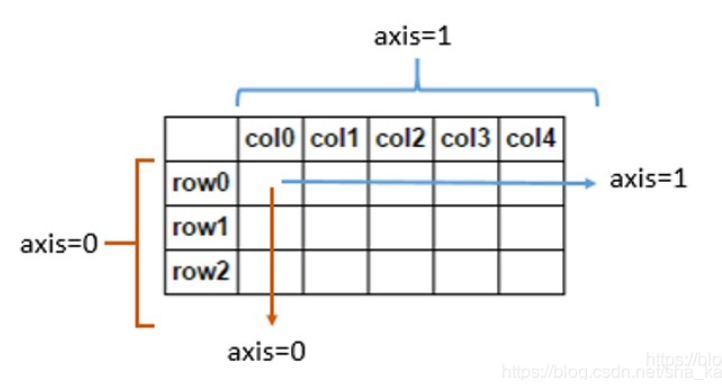
df.min(axis = 0)
# 输出:
species arthropod
legs 2
wings 0.0
dtype: object
df.max(axis = 1)
# 输出:
falcon 2.0
horse 4.0
spider 8.0
ostrich 2.0
dtype: float64
② DataFrame.value_counts()
DataFrame.value_counts(subset=None, normalize=False, sort=True, ascending=False, dropna=True)
统计数据出现的次数,可升降序,可对某列/行筛选
DataFrame.value_counts()
③ DataFrame.groupby()
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True)
把数据分组
DataFrame.groupby()
④ DataFrameGroupBy.value_counts()
DataFrameGroupBy.value_counts(subset=None, normalize=False, sort=True, ascending=False, dropna=True)[source]
DataFrameGroupBy.value_counts()
(12) 多级标题
① 读取含多级标题的文件
df = pd.read_excel("POI.xlsx", header=[0,1], index_col=0)
通过header控制
② 建立多级标题的DataFrame
参考:很多方式
'''
pandas.MultiIndex(levels=None, codes=None, sortorder=None, names=None, dtype=None, copy=False, name=None, verify_integrity=True)
先设置MultiIndex
新建df,让index/columns = MultiIndex
'''
# 一个实例:
columns = [('0', 'formatted_address'), ('1', 'sematic_description'), ('POIs', 'name'), ('POIs', 'address'), ('POIs', 'poiType'), ('POIs', 'tag'), ('POIs', 'longitude'), ('POIs', 'latitude'), ('POIs', 'direction'), ('POIs', 'distance')]
c = pd.MultiIndex.from_tuples(columns)
df = pd.DataFrame(columns=c)

③ 取值/赋值,需要加括号
df.at[0,('POIs', 'distance')] = 20
④ 更改标题名称
DataFrame.index
DataFrame.columns
DataFrame.rename()
DataFrame.rename_axis()
DataFrame.set_index()
(13) Dataframe转dictionary
DataFrame.to_dict(orient='dict', into=<class 'dict'>)
orientstr {‘dict’, ‘list’, ‘series’, ‘split’, ‘records’, ‘index’}
Determines the type of the values of the dictionary.
‘dict’ (default) : dict like {column -> {index -> value}}
‘list’ : dict like {column -> [values]}
‘series’ : dict like {column -> Series(values)}
‘split’ : dict like {‘index’ -> [index], ‘columns’ -> [columns], ‘data’ -> [values]}
‘tight’ : dict like {‘index’ -> [index], ‘columns’ -> [columns], ‘data’ -> [values], ‘index_names’ -> [index.names], ‘column_names’ -> [column.names]}
‘records’ : list like [{column -> value}, … , {column -> value}]
‘index’ : dict like {index -> {column -> value}}
Abbreviations are allowed. s indicates series and sp indicates split.
重点注意:
dict:key = col,value_key = row,value_value = value
index:key = row,value_key = col,value_value = value
list:key = col,value = 列的list
records:一行一个dict,key = col,value = value
df = pd.DataFrame({'col1': [1, 2],
'col2': [0.5, 0.75]},
index=['row1', 'row2'])
# df:
col1 col2
row1 1 0.50
row2 2 0.75
df.to_dict()
# 输出:
{'col1': {'row1': 1, 'row2': 2}, 'col2': {'row1': 0.5, 'row2': 0.75}}
df.to_dict('dict')
# 输出:
{'col1': {'row1': 1, 'row2': 2}, 'col2': {'row1': 0.5, 'row2': 0.75}}
df.to_dict('list')
# 输出:
{'col1': [1, 2], 'col2': [0.5, 0.75]}
# 与list相同效果:
tmp_dict = {col:df[col].tolist() for col in df.columns}
print(tmp_dict)
# 输出:
{'col1': [1, 2], 'col2': [0.5, 0.75]}
df.to_dict('series')
# 输出:
{'col1': row1 1
row2 2
Name: col1, dtype: int64,
'col2': row1 0.50
row2 0.75
Name: col2, dtype: float64}
df.to_dict('split')
# 输出:
{'index': ['row1', 'row2'],
'columns': ['col1', 'col2'],
'data': [[1, 0.5], [2, 0.75]]}
df.to_dict('tight')
# 输出:
{'index': ['row1', 'row2'],
'columns': ['col1', 'col2'],
'data': [[1, 0.5], [2, 0.75]],
'index_names': [None],
'column_names': [None]}
df.to_dict('records')
# 输出:
[{'col1': 1, 'col2': 0.5}, {'col1': 2, 'col2': 0.75}]
df.to_dict('index')
# 输出:
{'row1': {'col1': 1, 'col2': 0.5}, 'row2': {'col1': 2, 'col2': 0.75}}
4. 进制转换
# 二进制以0b或0B开头
# 八进制以0o或0O开头
# 十六进制以0x或0X开头
# 32/16/8/2进制转10进制:
# 32进制32=2×32⁰+3×32¹
print(int('32', 32))
# 16进制a=10
print(int('0xa', 16))
# 8进制12=2×8⁰+1×8¹
print(int('0o12', 8))
# 2进制1010=0×2⁰+1×2¹+0×2²+1×2³
print(int('0b1010', 2))
# 开头的标志可以不写
print(int('a', 16))
print(int('12', 8))
print(int('1010', 2))
# 将十进制decimal system转换成二进制binary system
print(bin(10))
# 将十进制decimal system转换成八进制octal system
print(oct(10))
# 将十进制decimal system转换成十六进制hexadecimal system
print(hex(10))
# 例子
m = '000AC949'
print(int(m,16)) # 输出:706889
print(hex(706889)) # 输出:0xac949
bug和常用易错点
(1)读入长文本输出后末位数字变为000
① 读入文件时把将长文本列转换成str,输出excel后会没问题
df = pd.read_excel(file,header=0,index_col=0,converters={"XXX": str})
② 将长文本列更改一下,输出csv会没问题
参考
def num_out(data):
data = str(data)+'t'
return data
df['XXX'] = df['XXX'].map(num_out)
(2)变量报错
在函数内部,给变量添加global修饰符,声明此变量为全局变量
(3)nan值判断
print(type(df.at[0,'Amap']))
# <class 'numpy.float64'>
import pandas as pd
import numpy as np
import math
if np.isnan(df.at[0,'Amap']):
print('1')
if math.isnan(df.at[0,'Amap']):
print('1')
if pd.isnull(df.at[0,'Amap']):
print('1')
# 输出:
1
1
1
(4)存在某值的某列取值
参考1
参考2
# 判断某列是否存在某值:
print(some_value in df['column_name'].values)
# 取存在某值的某列中的行信息
df.loc[df['column_name'] == some_value]
df.loc[df['column_name'].isin([some_value])]
# 取存在特殊值的行的XX列信息
# 通过index
print(df.at[df[df['column_name'] == some_value].index[0],'XX'])
# 直接取值
print(df.loc[df['column_name'] == some_value,'XX'].values[0])
(5)为某列为某值的其他行复制
# 为num列为2的行的类型列赋值为abc
df.loc[:,'类型'].loc[df['num']==2] = 'abc'
(6)保存后格式发生变化
-
如果有时间格式数据,特别是计算了时间差,需要保存成csv
如果需要xlsx格式,就先保存成csv再读入保存成xlsx可正常显示。 -
列表类型保存后读入成为字符串
使用eval()转换
df['list'] = pd.eval(df['list'])
特别注意
留坑
- reset_index
- reindex
- inplace=True
- 如果XXX中有inplace=True,不能写df=df.XXX
- 保留疑问
df.set_axis(['i', 'ii'], axis='columns', inplace=True)df.reset_index(drop=True,inplace=True)
最后
以上就是负责小鸭子最近收集整理的关于数据处理代码记录数据处理的全部内容,更多相关数据处理代码记录数据处理内容请搜索靠谱客的其他文章。








发表评论 取消回复