目录
- 预备知识
- 1.关于ARM架构
- 2.关于汇编语言
- 3.树莓派安装参考
- 实验目的
- 实验环境
- 实验步骤一
- 实验步骤二
- 实验步骤三
预备知识
1.关于ARM架构
ARM架构,过去称作高级精简指令集机器(英语:Advanced RISC Machine,更早称作Acorn精简指令集机器,AcornRISC Machine),是一个精简指令集(RISC)处理器架构家族,其广泛地使用在许多嵌入式系统设计。由于节能的特点,其在其他领域上也有很多作为。ARM处理器非常适用于移动通信领域,匹配其主要设计目标为低成本、高性能、低耗电的特性。另一方面,超级计算机消耗大量电能,ARM同样被视作更高效的选择。安谋控股开发此架构并授权其他公司使用,以供他们实现ARM的某一个架构,开发自主的系统单片机和系统模块(system-on-module,SoC)。
2.关于汇编语言
汇编语言(英语:assembly language)是一种用于电子计算机、微处理器、微控制器,或其他可编程器件的低级语言。在不同的设备中,汇编语言对应着不同的机器语言指令集。 一种汇编语言专用于某种计算机系统结构,而不像许多高级语言,可以在不同系统平台之间移植。
3.树莓派安装参考
link
实验目的
通过该实验了解ARM汇编基础语法,这是我们学习ARM下的漏洞利用程序编写的基础。
实验环境
服务器:Ubuntu IP地址:随机分配
测试文件请在实验机内下载使用:http://tools.hetianlab.com/tools/T052.zip
启动树莓派命令:
$ qemu-system-arm -kernel ~/qemu_vms/qemu-rpi-kernel/kernel-qemu-4.4.34-jessie -cpu arm1176 -m 256 -M versatilepb -serial stdio -append "root=/dev/sda2 rootfstype=ext4 rw" -hda ~/qemu_vms/rasbian.img -redir tcp:5022::22 -no-reboot
SSH连接树莓派:
$ ssh pi@127.0.0.1 -p 5022
pi账户密码raspberry。
实验步骤一
有时,一次性加载(或存储)多个值更有效率。因此,我们需要使用LDM(载入多个值)和STM(存储多个值)。这些指令基于起始地址的不同,有不同的形式。下面是我们在本节中将会使用的代码。我们将一步一步地完成每一个指令,代码在test5.s中。
.data
array_buff:
.word 0x00000000 /* array_buff[0] */
.word 0x00000000 /* array_buff[1] */
.word 0x00000000 /* array_buff[2]. This element hasa relative address of array_buff+8 */
.word 0x00000000 /* array_buff[3] */
.word 0x00000000 /* array_buff[4] */
.text
.global _start
_start:
adr r0, words+12 /* address of words[3] -> r0 */
ldr r1, array_buff_bridge /* address of array_buff[0] -> r1 */
ldr r2, array_buff_bridge+4 /* address of array_buff[2] -> r2 */
ldm r0, {r4,r5} /* words[3] -> r4 = 0x03;words[4] -> r5 = 0x04 */
stm r1, {r4,r5} /* r4 -> array_buff[0] = 0x03;r5 -> array_buff[1] = 0x04 */
ldmia r0, {r4-r6} /* words[3] -> r4 = 0x03,words[4] -> r5 = 0x04; words[5] -> r6 = 0x05; */
stmia r1, {r4-r6} /* r4 -> array_buff[0] = 0x03;r5 -> array_buff[1] = 0x04; r6 -> array_buff[2] = 0x05 */
ldmib r0, {r4-r6} /* words[4] -> r4 = 0x04; words[5] -> r5= 0x05; words[6] -> r6 = 0x06 */
stmib r1, {r4-r6} /* r4 -> array_buff[1] = 0x04;r5 -> array_buff[2] = 0x05; r6 -> array_buff[3] = 0x06 */
ldmda r0, {r4-r6} /* words[3] -> r6 = 0x03; words[2]-> r5 = 0x02; words[1] -> r4 = 0x01 */
ldmdb r0, {r4-r6} /* words[2] -> r6 = 0x02;words[1] -> r5 = 0x01; words[0] -> r4 = 0x00 */
stmda r2, {r4-r6} /* r6 -> array_buff[2] = 0x02;r5 -> array_buff[1] = 0x01; r4 -> array_buff[0] = 0x00 */
stmdb r2, {r4-r5} /* r5 -> array_buff[1] = 0x01;r4 -> array_buff[0] = 0x00; */
bx lr
words:
.word 0x00000000 /* words[0] */
.word 0x00000001 /* words[1] */
.word 0x00000002 /* words[2] */
.word 0x00000003 /* words[3] */
.word 0x00000004 /* words[4] */
.word 0x00000005 /* words[5] */
.word 0x00000006 /* words[6] */
array_buff_bridge:
.word array_buff /* address of array_buff, or inother words - array_buff[0] */
.word array_buff+8 /* address of array_buff[2] */
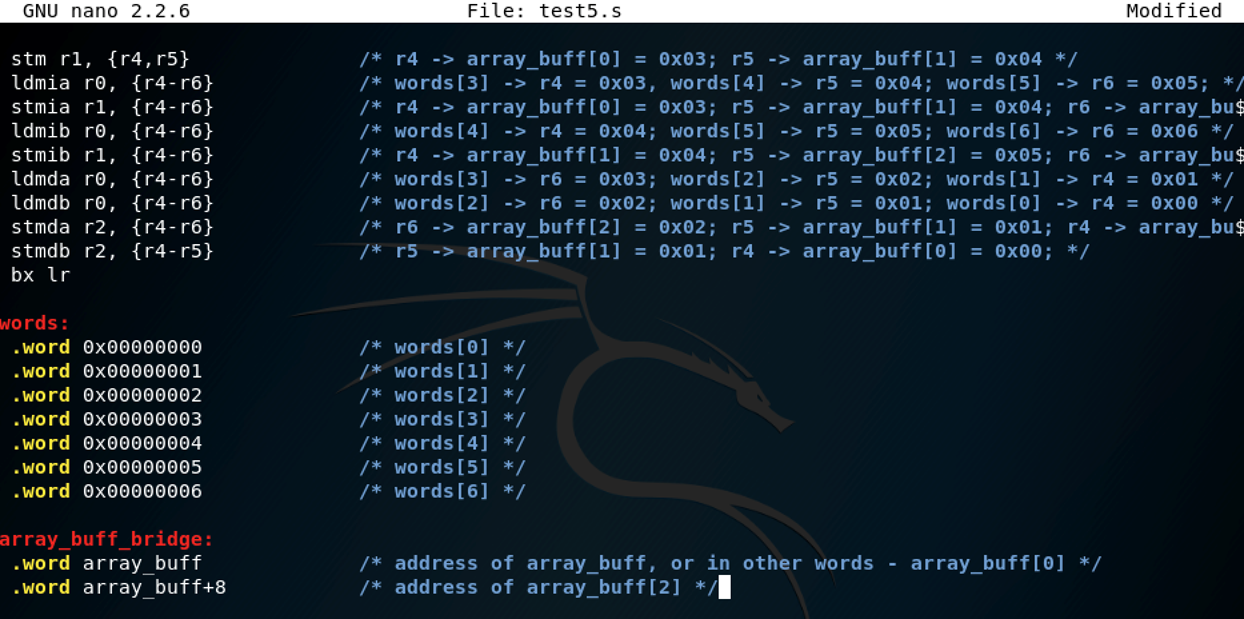
.word指向了一个32位共计4字节的数据(内存)区块,这对于理解代码中的偏移很重要。程序中包含了.data区段,在此我们开辟了一个有5个元素的空数组array_buff。.text段包含了由内存操作指令构成的代码,和一个包含了两个标签的只读数据池,其中一个标签规定了一个具有7个元素的数组,另一个标签起到了“桥接”.text区段和.data区段的作用,我们可以用它访问.data区段的array_buffer。
编译链接:

载入gdb调试,在_start下断点:
run,可以看到将要执行的指令:
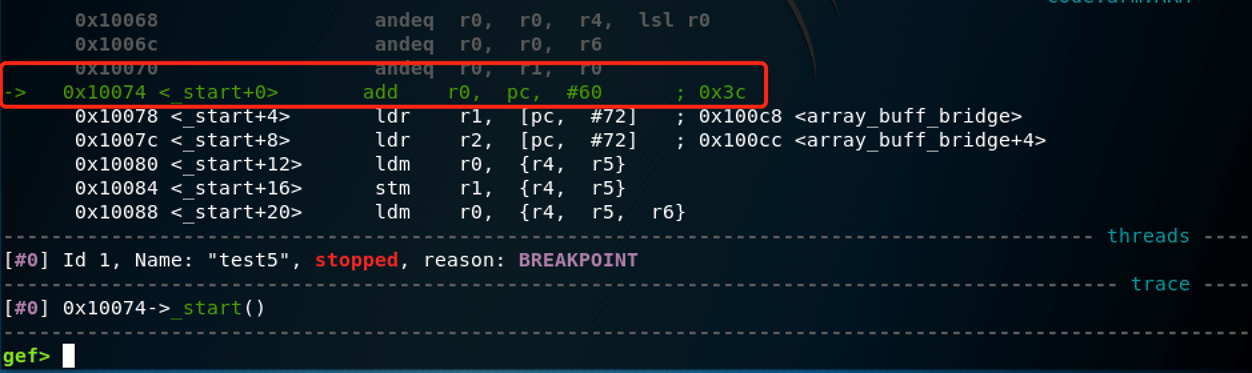
adr r0, words+12 /* 将word[3]的地址传送给r0*/
我们使用ADR指令(偷懒的办法)将数组第四部分(word[3])的地址传送给R0。我们用R0指向word数组的中间位置,所以我们可以从这开始向前或者向后移动指针。
nexti执行:
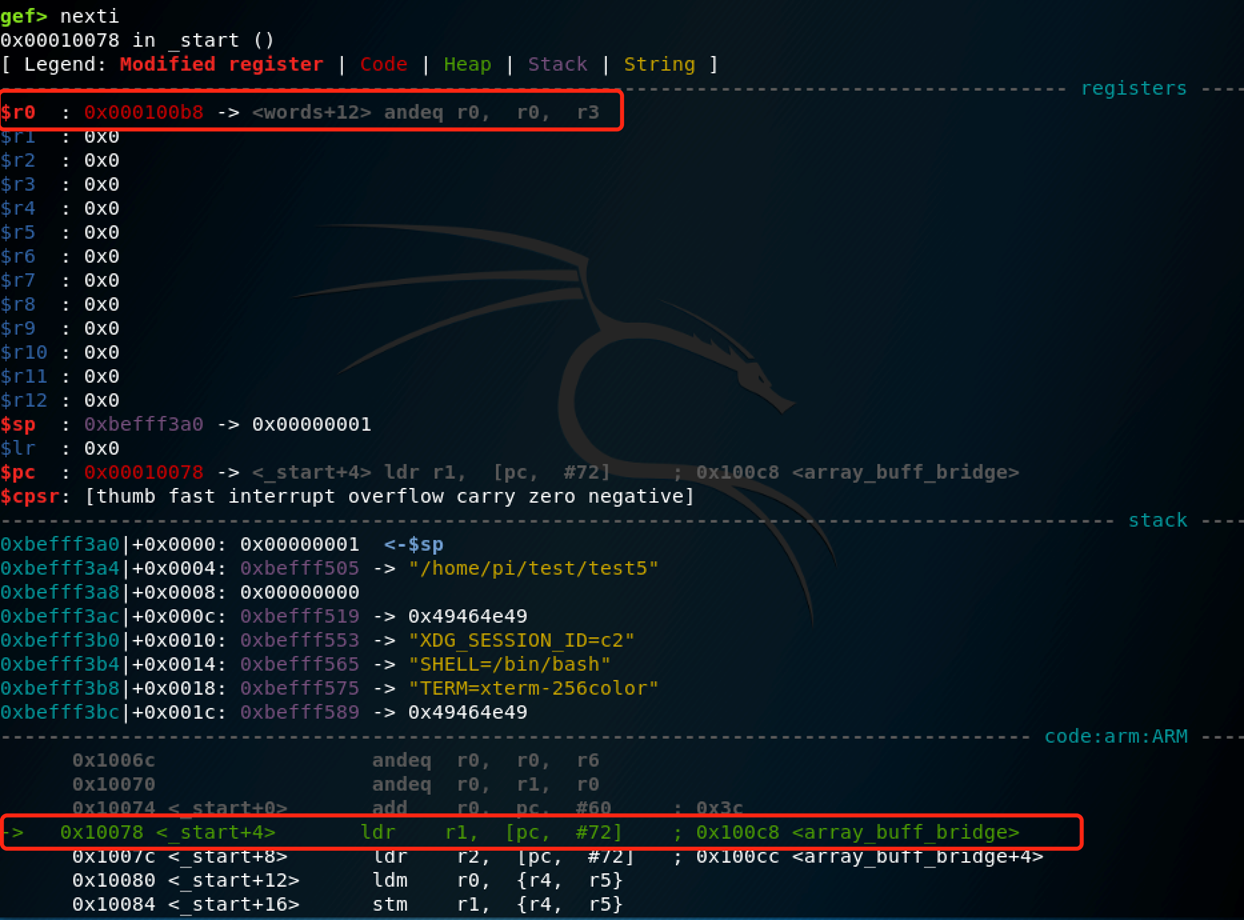
可以看到此时r0的地址为0x100b8,这是word[3]的地址,说明数组首地址word[0]为0x100b8-0xc(12的16进制)=0x100ac,使用下图命令验证,确实如此:

实验步骤二
在上上张图可以看到接下来要执行的两条指令:
ldr r1,array_buff_bridge /* address of array_buff[0] -> r1 */
ldr r2, array_buff_bridge+4 /*address of array_buff[2] -> r2 */
执行完上面的两条命令后,R1,R2中分别包含了 array_buff[0]的地址和 array_buff[2]的地址。
我们使用nexti 2来执行:
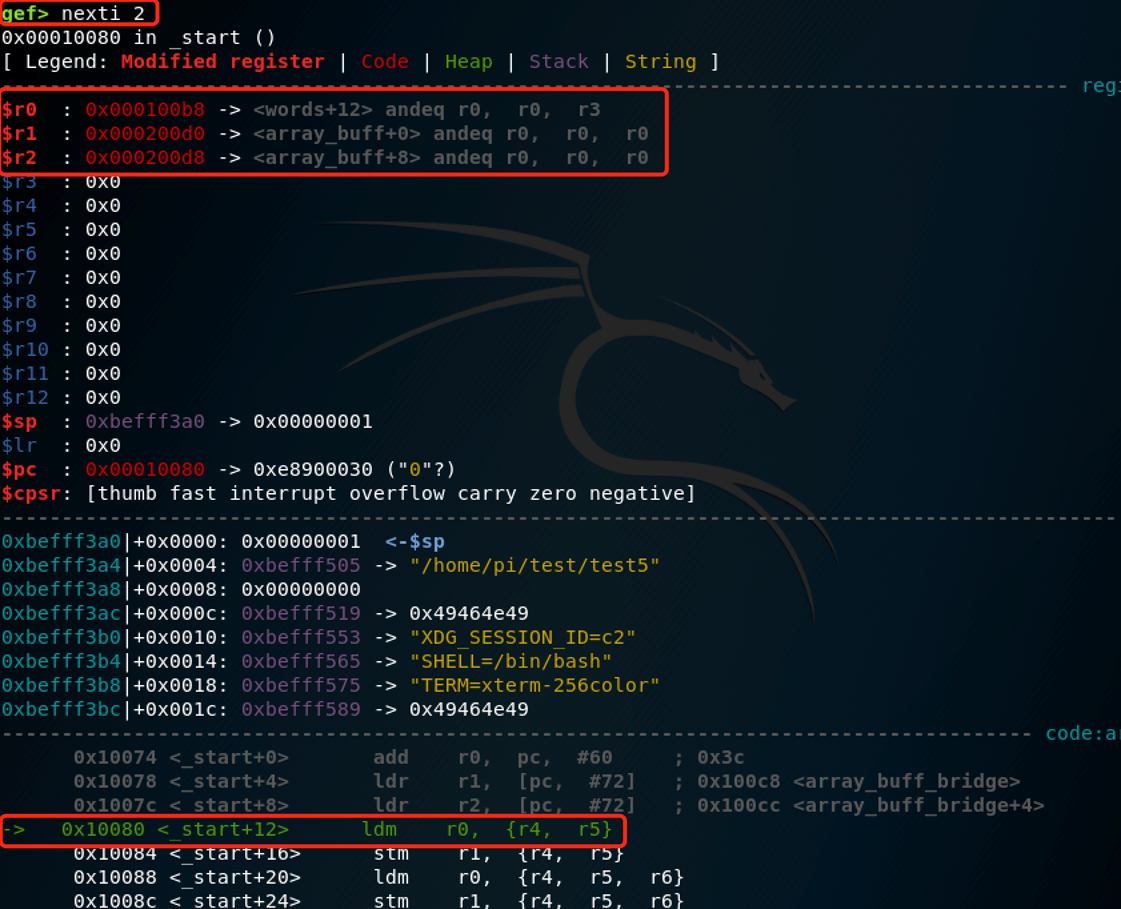
可以看到此时r1为0x200d0,r2为0x200d8,它们分别是array_buff[0]的地址和array_buff[2]的地址。
下一条指令为:
ldm r0, {r4,r5} /* words[3] -> r4 = 0x03; words[4] -> r5 = 0x04 */
使用LDM指令,将R0指向的内存中,取两个字的数据出来。由于之前我们让R0指向了word[3],因此word[3]的值会被存入R4,word[4]的会被存入R5。
也就是说,使用一条指令加载了多个数据(2个数据块),并将R4设置为0x00000003 ,R5设置为 0x00000004。
使用nexti执行后如图所示:
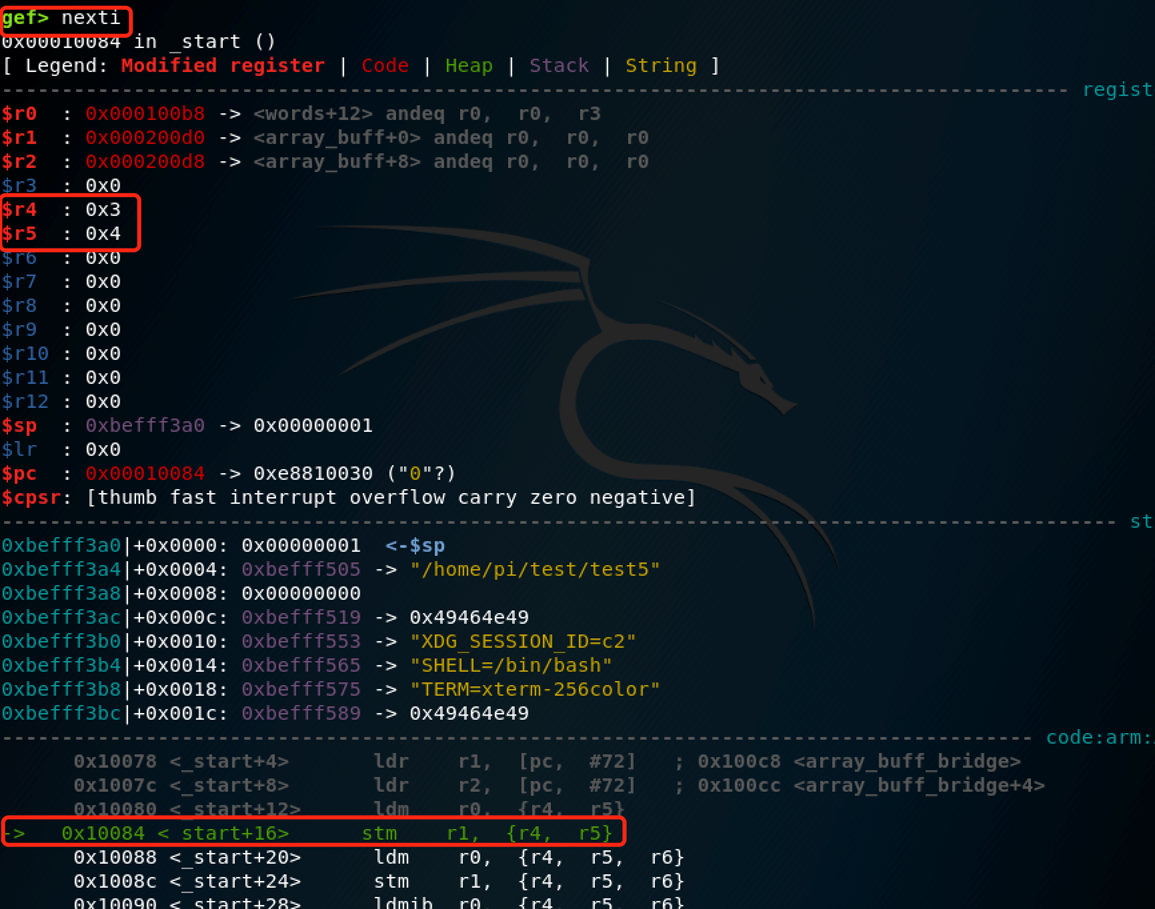
符合我们的推测。
下一条指令是:
stm r1, {r4,r5} /* r4 -> array_buff[0] = 0x03; r5 -> array_buff[1] = 0x04 */
使用STM指令将多个值写入内存。STM指令将R4,R5寄存器的值0x3和0x4存入R1指向的内存空间中。由于之前我们让R1指向 array_buff的第一个元素,所以指令执行后array_buff[0]=0x00000003,array_buff[1] =0x00000004。如果没有特别说明,LDM和STM指令操作的基本单位是一个字(32位等于4个字节)。
使用nexti执行后可以看到符合我们的推测:
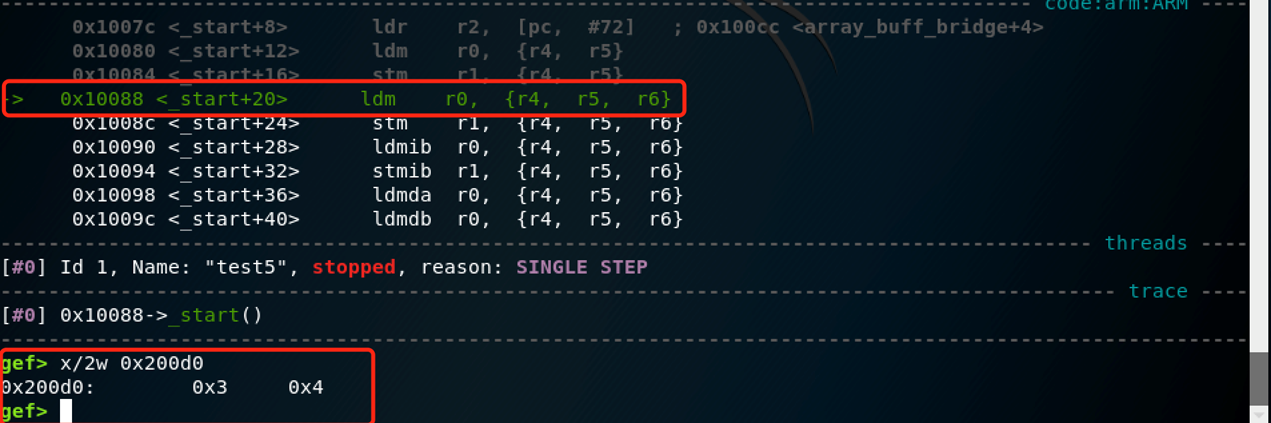
LDM和STM有多种不同的使用形式。具体是哪一种使用形式由指令的后缀所决定。这个示例列出了后缀的几种形式:-IA(之后增加),-IB(之前增加),-DA(之后减少),-DB(之前减少)。这么多种类型,他们之间是如何区分的呢?由指令的第一个字段:运算指令规定了访问内存的方式(寄存器作为源地址还是目标地址)。实际上,由于LDM和LDMIA作用相同,所以每次载入完成后,地址指针会自己增加,从而指向下一个被载入的元素。用这种方法可以从某内存地址中获取(前向)序列化的数据,并载入寄存器。
我们看接下来要执行的两条指令:
ldmia r0, {r4-r6} /* words[3] -> r4 = 0x03, words[4] -> r5 = 0x04; words[5] -> r6 = 0x05; */
stmia r1, {r4-r6} /* r4 -> array_buff[0] = 0x03; r5 -> array_buff[1] = 0x04; r6 -> array_buff[2] = 0x05 */
执行完上面的两条指令后,寄存器R4-R6分别包含了0x3,0x4,0x5,内存地址0x000100D0,0x000100D4和0x000100D8中也包含了0x3,0x4,0x5。
nexti 2执行:
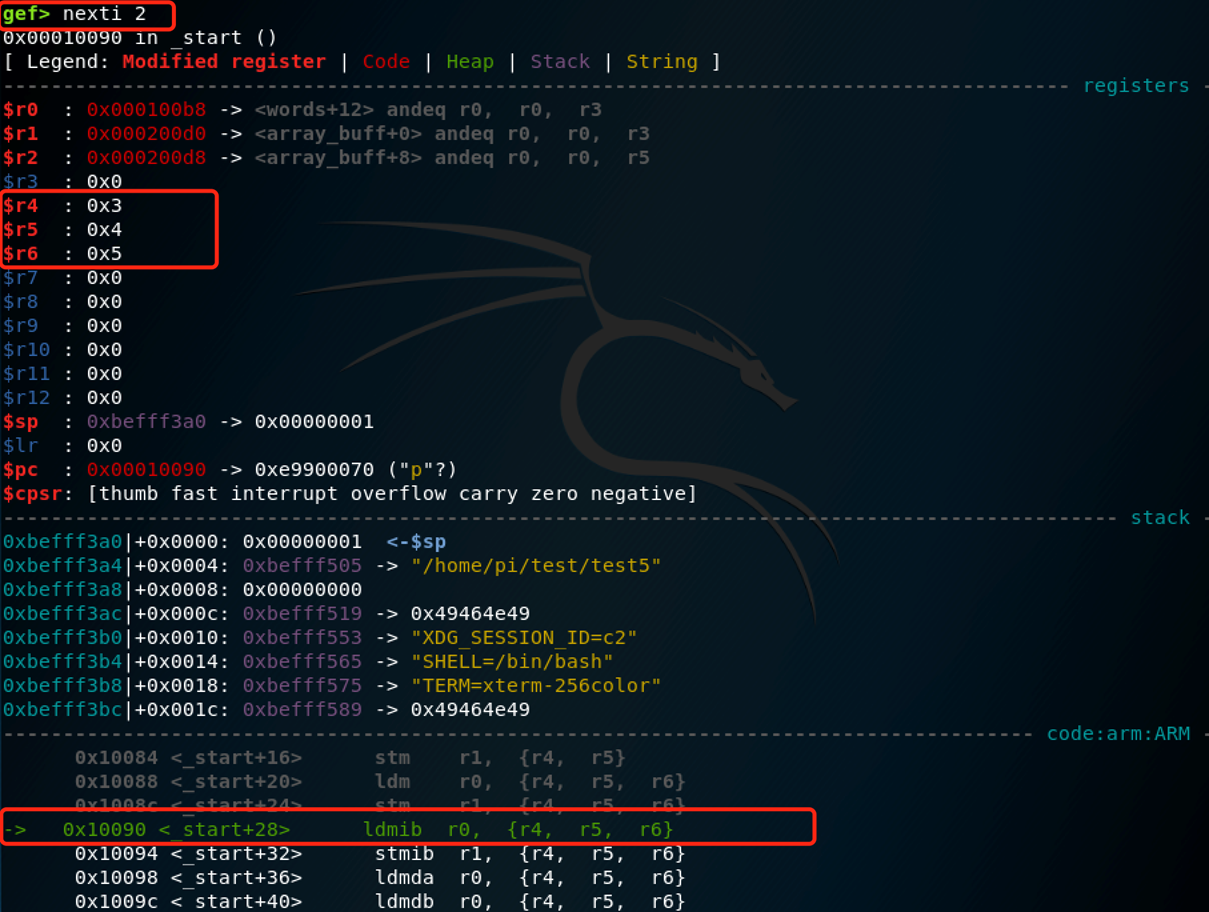
可以看到r4-r6确实符合,再看看0x200d0及其后的地址:

同样验证了。
接下来的两条指令为:
ldmib r0,{r4-r6} /*words[4] -> r4 = 0x04; words[5] -> r5 = 0x05; words[6] -> r6 = 0x06 */
stmib r1,{r4-r6} /* r4-> array_buff[1] = 0x04; r5 -> array_buff[2] = 0x05; r6 ->array_buff[3] = 0x06 */
LDMIB指令先将源地址增加4字节(一个字),然后开始载入数据。该方法仍能让我们载入一串前向数据,但第一个数据的起始地址相较源地址有4个字节的偏移。这就是为什么我们用LDMIB指令将内存中的第一个元素载入R4后,R4是0x04(word[4]),而不是R0指向的0x3(word[3])。
执行之后,寄存器R4-R6存储了0x4,0x5,0x6,0x100D4,0x100D8和0x100DC也存储了 0x4,0x5,0x6。
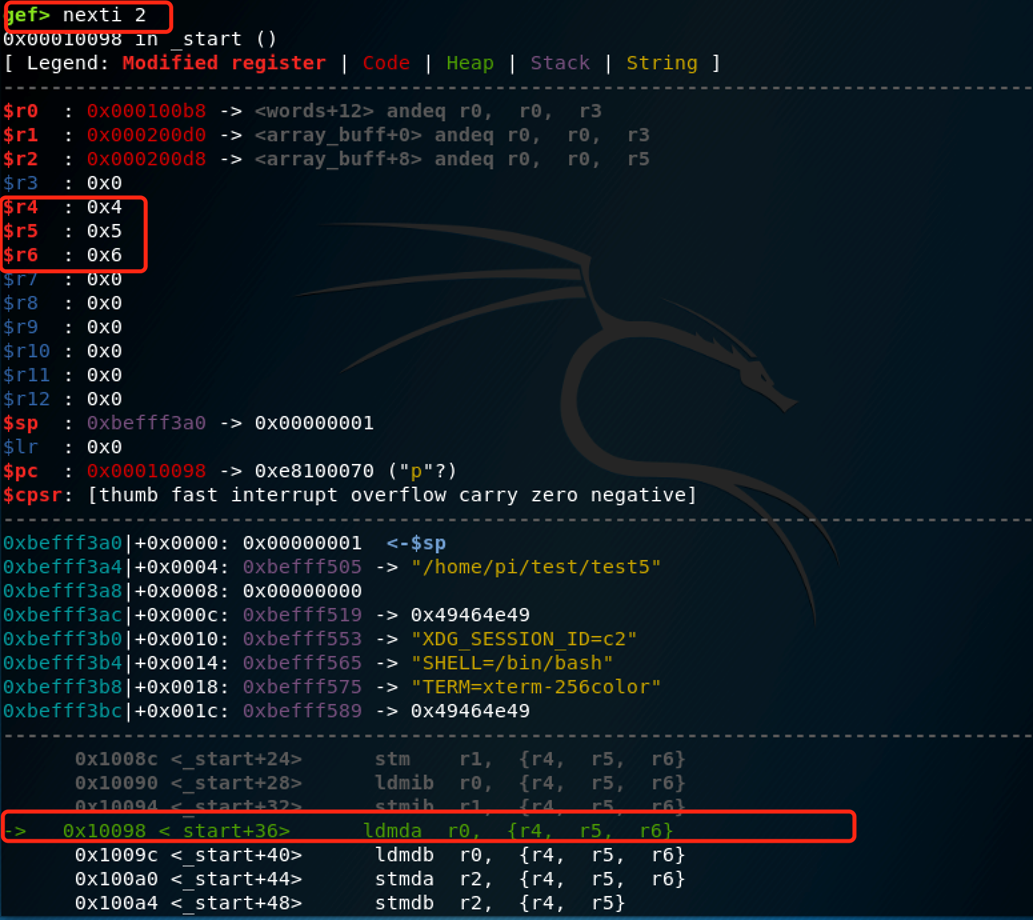
再看看对应的地址:

符合我们的推测。
接下来执行的是:
ldmda r0, {r4-r6} /* words[3] -> r6 = 0x03; words[2] -> r5 = 0x02; words[1] -> r4 = 0x01 */
使用LDMDA向相反方向执行运算。R0指向word[3],载入操作开始后,我们向后将 words[3],words[2]和words[1]载入R6,R5,R4。注意,连寄存器都是反着被载入的。所以指令将 R6赋值为0x00000003,R5赋值为0x00000002,R4赋值为0x00000001。这里的逻辑是,每次载入操作完成后向后减少内存地址所以是反向赋值。
Nexti后验证:
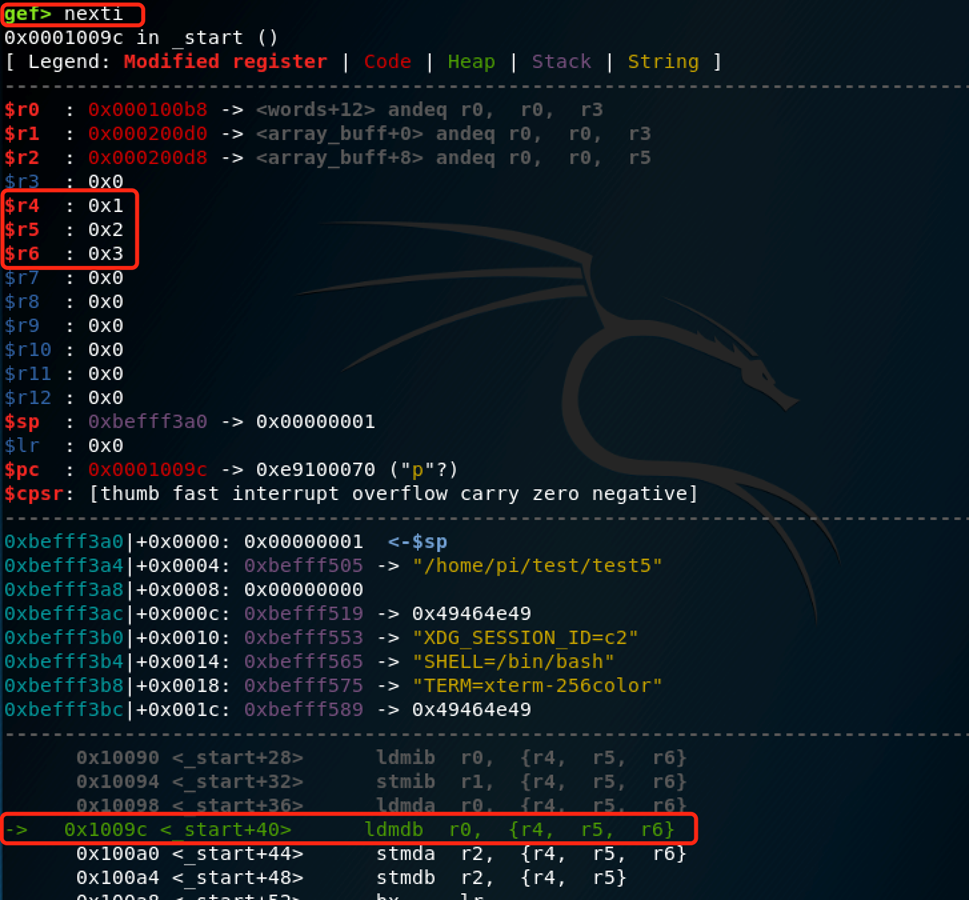
符合推测。
下一条执行的是:
ldmdb r0, {r4-r6} /* words[2] -> r6= 0x02; words[1] -> r5 = 0x01; words[0] -> r4 = 0x00 */
同样的道理,执行后r6为0x2,r5为0x1,r4为0x0。
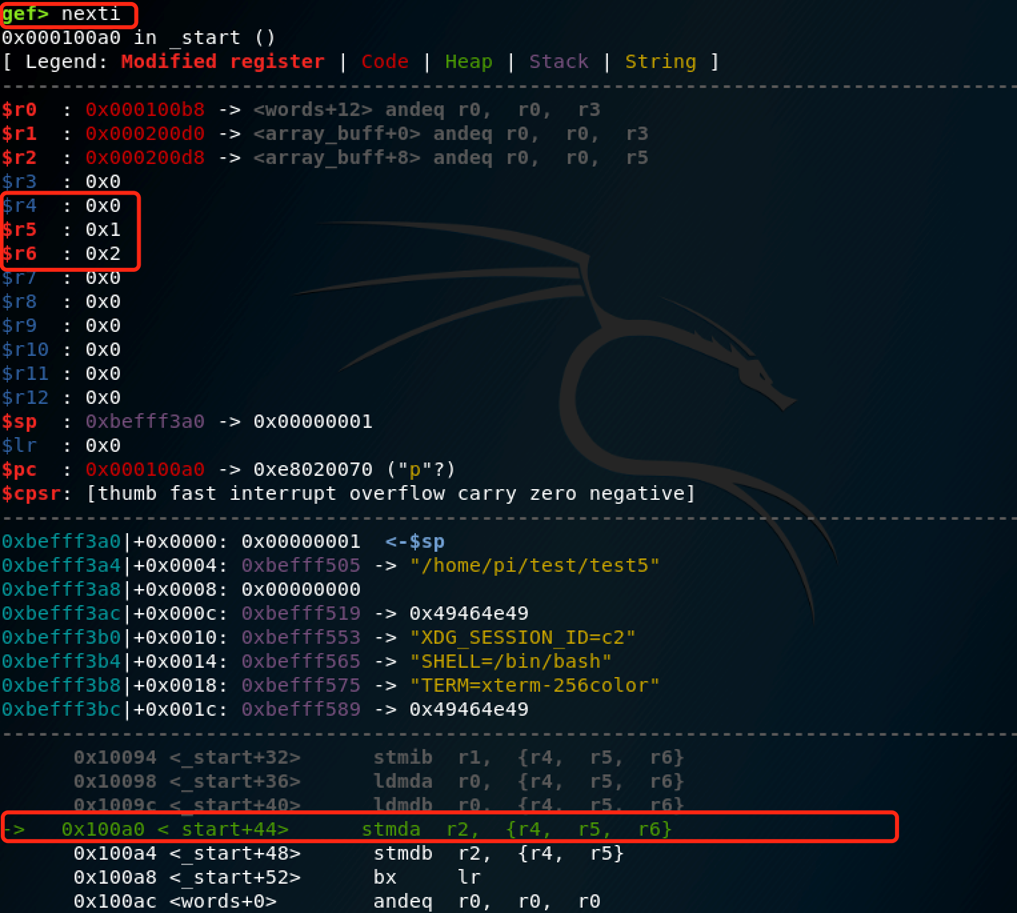
接着执行的是:
stmda r2, {r4-r6} /* r6 -> array_buff[2] = 0x02; r5 -> array_buff[1] = 0x01; r4 -> array_buff[0] = 0x00 */
同样的道理,存储值之后,降低地址,由r6往r4走,执行之后,array_buff[0](0x200d0)为0x0,array_buff[1](0x200d4)为0x1,array_buff[2](0x200d8)为0x2。
nexti执行:
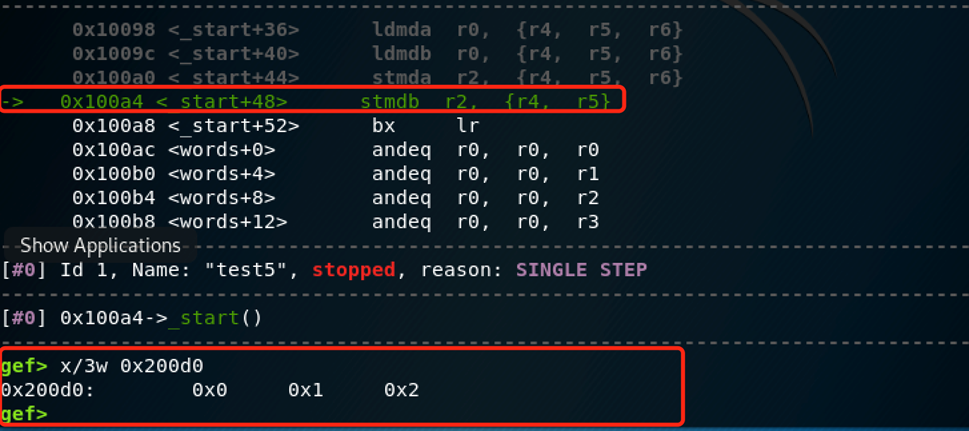
这一条执行的是:
stmdb r2, {r4-r5} /* r5 -> array_buff[1] = 0x01; r4 -> array_buff[0] = 0x00; */
一样的道理,执行之后,array_buff[1](0x100d4)为0x1,array_buff[0](0x100d0)为0x0。
nexti执行后使用下列命令查看:

符合推测。
实验步骤三
任务描述:学习push和pop。
进程中有使用一块内存区域叫堆栈。堆栈指针(SP)是一个寄存器,在正常情况下,它总是指向栈内存区域中的一个地址。应用程序通常使用堆栈进行临时数据存储。之前提过,ARM使用加载/存储模型进行内存访问,这意味着指令LDR/STR或它们的派生指令(LDM…/STM…)用于内存操作。在x86中,我们使用PUSH和POP从堆栈中加载和存储。在ARM中,我们也可以使用这两个指令:
当我们把数据压入降序分布的栈区(详见第7部分:栈和函数)后会发生:
首先,SP寄存器里的地址值减4。
第二步,将信息储存在SP指向的新的地址空间中。
当把数据弹出栈时会发生:
首先,当前SP地址所指向的内存里的值内载入到相应寄存器中。
然后SP里的值加4。
demo代码如下,在test6.s中:
.text
.global _start
_start:
mov r0, #3
mov r1, #4
push {r0, r1}
pop {r2, r3}
stmdb sp!, {r0, r1}
ldmia sp!, {r4, r5}
bkpt
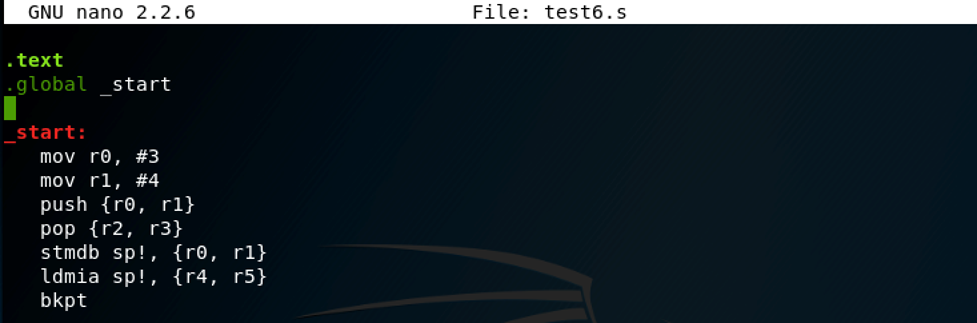
编译,链接后可以查看其汇编代码:
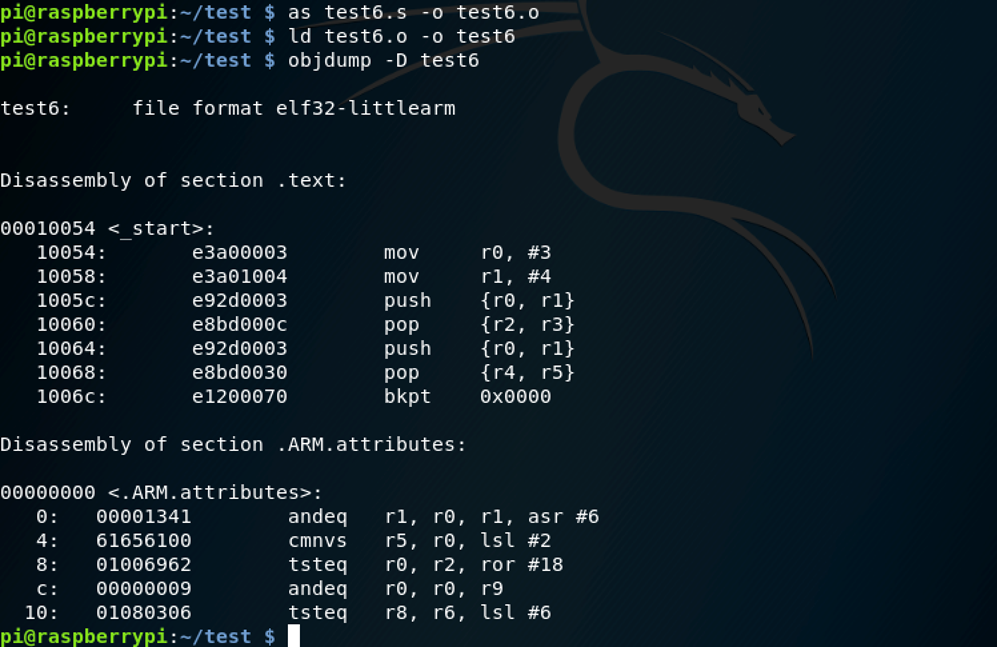
我们发现, LDMIA 和STMDB指令被转换成了 PUSH和POP。这是因为push有同义词stmdb SP!而pop有同义词LDMIA sp!
使用gdb调试,在_start下断点,使用nexti 2直接先执行前两条mov指令,然后看看情况。
先看看sp:
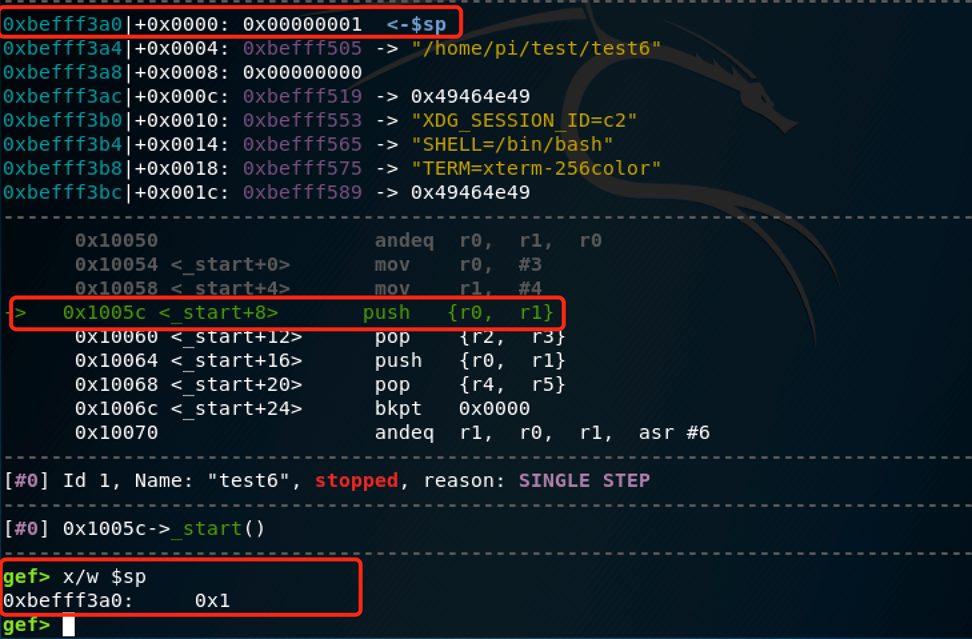
可以看到下一条push指令应该会把SP减8,并将R0和R1的值压入堆栈。
我们使用nexti执行后看看:
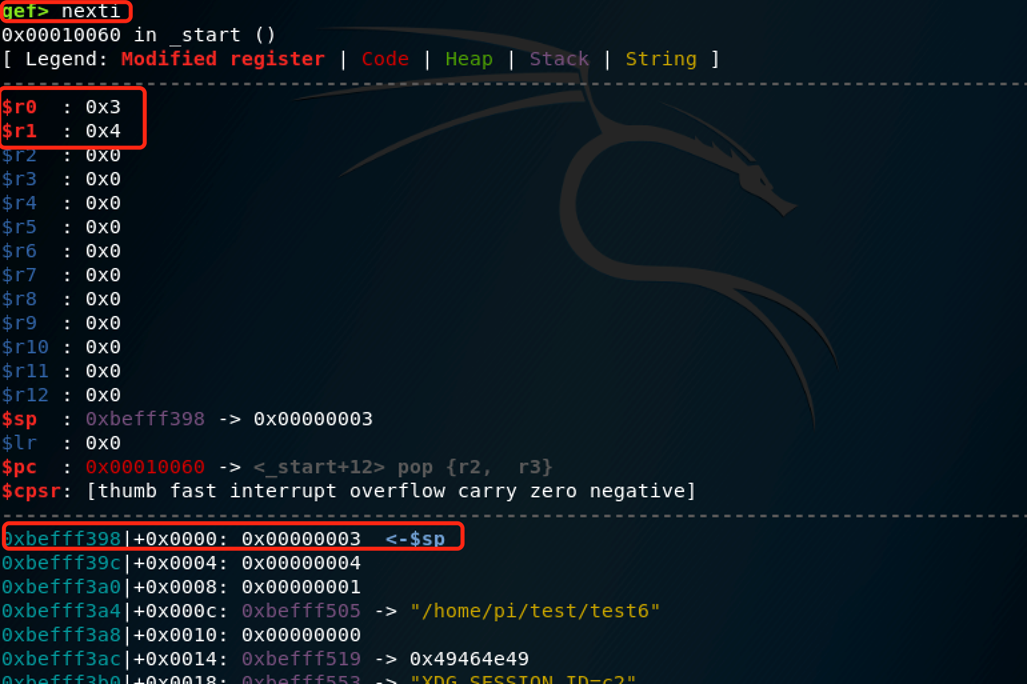
可以看到本来sp是0xbeff3a0,现在为0xbeff398,0xbeff398=0xbeff3a0-0x8。
并且r0,r1被压栈了。
下一条要执行的是pop:
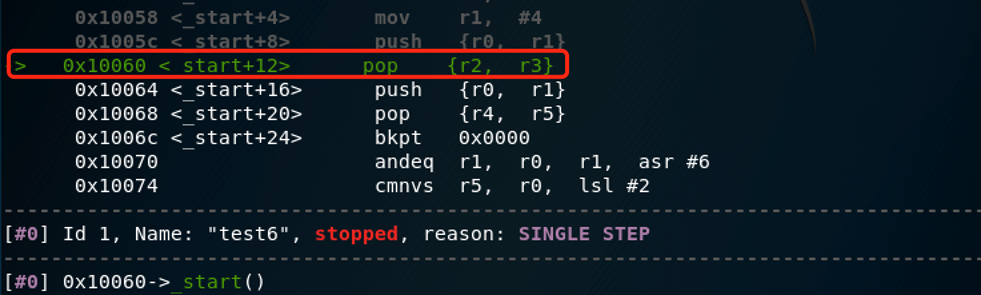
两个值(0x3和0x4)会被弹出到相应寄存器里(pop {r2, r3}),所以 R2=0x3 ,R3=0x4。SP加8。
执行nexti后查看:
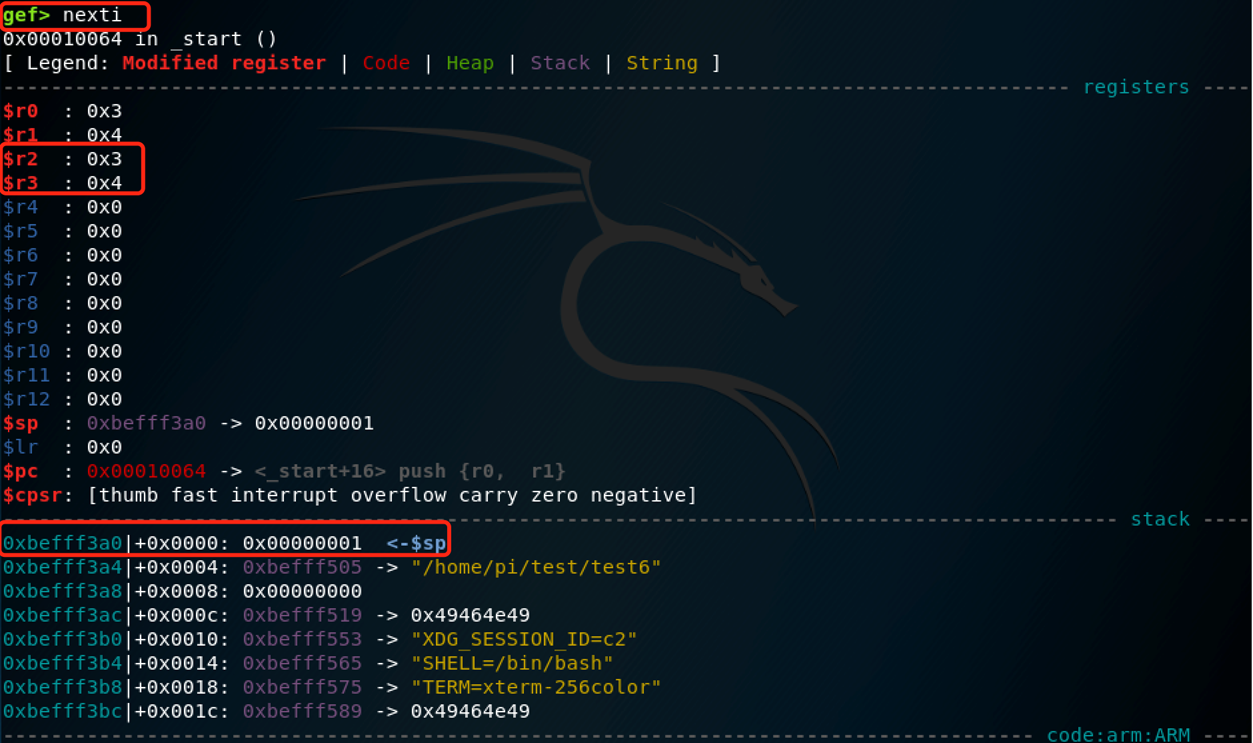
可以看到,此时sp+8,回到了0xbefff3a0,并且r2被赋为0x3,r3被赋为0x4,符合推测,后续的指令的分析也是同样的方法,不再演示。
最后
以上就是谦让冷风最近收集整理的关于ARM汇编教程三预备知识实验目的实验环境实验步骤一实验步骤二实验步骤三的全部内容,更多相关ARM汇编教程三预备知识实验目内容请搜索靠谱客的其他文章。








发表评论 取消回复