文章目录
- 一、前言
- 二、开始
- (一)获取推送URL链接
- (二)爬取网页并提取图片保存
- 1.定义用于爬取推送图片的PictureSpider类
- 2.定义get_url_text()方法
- 3.定义search_pictures()方法
- 4.定义download_pictues()方法
- 5.定义save_picture()方法
- 6.开始爬取与结果
- 7.爬虫部分完整代码
- (三)将图片批量导入PPT
- 1.代码
- 2.结果
- 三、结语
一、前言
前两天在微信看到董付国老师的公众号“python小屋”发了一篇推送,标题是《学习Python+numpy数组运算和矩阵运算看这254页PPT就够了》。董老师把他课件中的254页PPT图片全部放在了这篇推送中。
我最近正在学习机器学习,并尝试把吴恩达老师《Deep Learning》课程中用Matlab实现的代码用Python重新实现。而想要用Python高效率地实现矩阵运算,就要求我尽快掌握Numpy库的用法,因此我十分想要这份PPT。然而想要获得这份PPT是有要求的:

But,36个赞对我来说有点难,我的微信好友压根就没几个……可我又实在想要这份PPT,怎么办?看来只能尝试写个脚本,把这些图片爬取下来并自动导入PPT了。这里给董老师道个歉,白嫖实属无奈,希望您能原谅~
最后的结果:
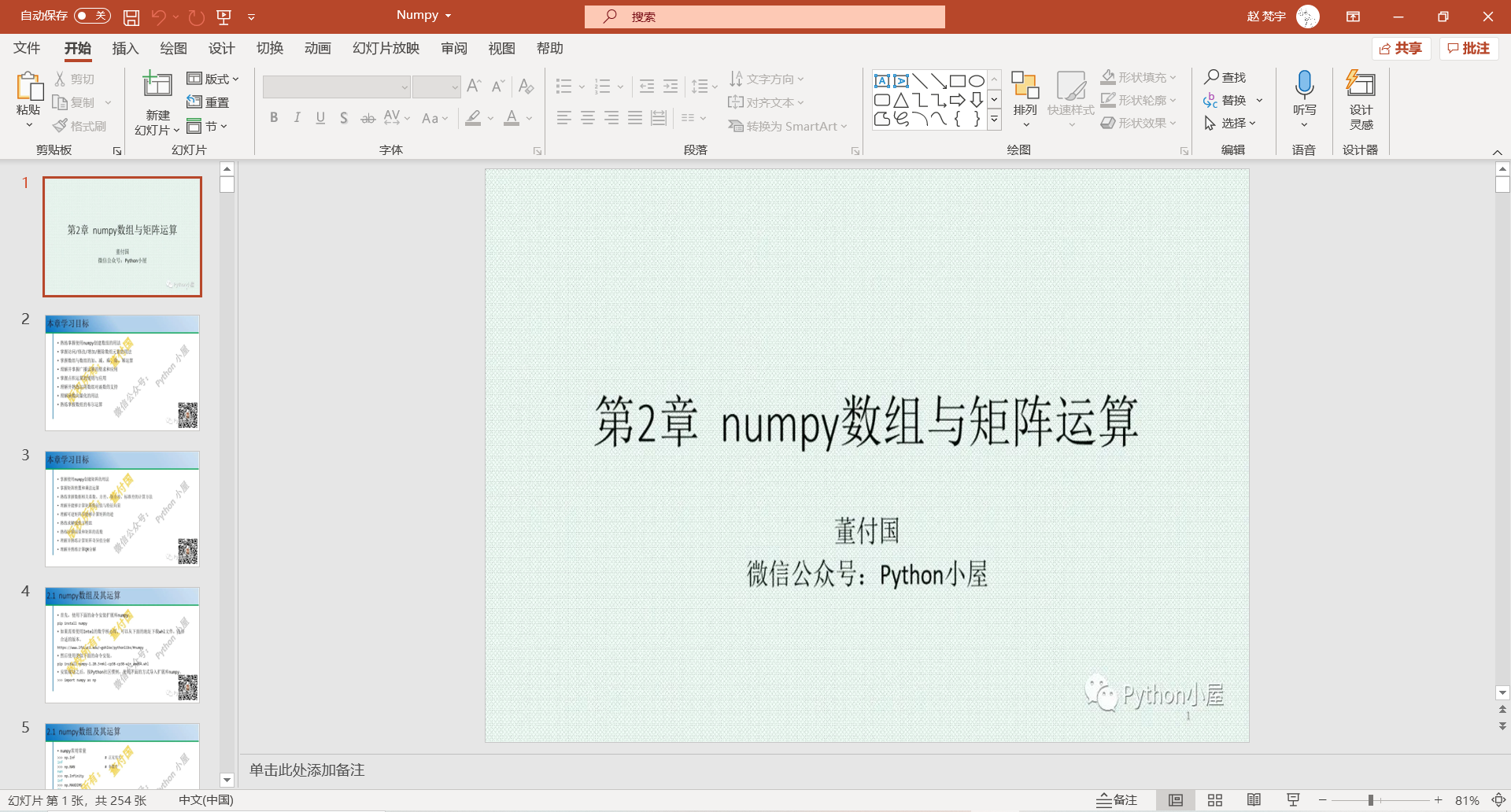
二、开始
(一)获取推送URL链接
想要爬取某个网页,自然要先获取它的URL链接。由于直接打开某篇推送微信会自动随机生成一个临时链接,所以这里我依然是用微信公众号后台获取了目标推送的URL。具体方式见我的另一篇文章用python爬取公众号文章。最后得到目标推送的链接:
https://mp.weixin.qq.com/s?__biz=MzI4MzM2MDgyMQ==&mid=2247493780&idx=1&sn=efde5d4ec9a5c04383b709ace1222518&chksm=eb8943cedcfecad84ffb4794d19cce4c7ae3344ffa0c361f646d10689717af33dab5da93332f#rd
(二)爬取网页并提取图片保存
1.定义用于爬取推送图片的PictureSpider类
这次的爬虫,我选择以 面向对象 的方式来实现。
首先定义一个专门用于爬取公众号推送中图片的类,命名为PictureSpider,在初始化时向其传入要爬取的推送的链接start_url,并设置爬虫的headers参数(这里我将Cookie和User-Agent都保存在了"wechat.yaml"文件中,初始化时会自动读取):
class PictureSpider(object):
def __init__(self,start_url):
with open("wechat.yaml", "r") as file:
file_data = file.read()
self.config = yaml.safe_load(file_data)
self.headers = {
"Cookie": self.config['cookie'],
"User-Agent": self.config['user_agent']
}
self.start_url = start_url
2.定义get_url_text()方法
定义get_url_text()方法爬取推送,并返回推送的html内容:
def get_url_text(self):
"""
返回网页html内容
parameter:
url->str:网址
return:
r.text->str:网页内容
"""
r = requests.get(self.start_url,headers=self.headers)
if r.status_code!=200:
print("网页加载失败")
else:
return r.text
3.定义search_pictures()方法
定义search_pictures()方法提取推送中的图片,并返回一个列表,这个列表储存了该推送中所有图片的URL链接:
def search_pictures(self,text):
"""
在网页中搜索图片url
parameter:
text->str: 网页内容
return:
picture_url->list: 图片URL列表
"""
pictures_url = []
re_image = re.compile('<img.*?src="(.*?)".*?>',re.S)
pictures = re_image.finditer(text)
for img in pictures:
if img.group(1):
pictures_url.append(img.group(1))
return pictures_url
4.定义download_pictues()方法
定义download_pictues()方法,对pictures_url列表中的每一个URL进行遍历爬取,即下载图片内容,并调用save_picture()方法将图片保存在指定文件夹中:
def download_pictues(self,pictues_url,save_address):
"""
下载图片
parameter:
pictures_url->list: 储存图片url的列表
save_address->str: 图片保存地址
"""
i = 1
n = len(pictues_url)
for url in pictues_url:
r = requests.get(url,headers=self.headers)
if r.status_code!=200:
print(f"图片爬取失败,第{i}/{n}张")
i += 1
continue
else:
self.save_picture(r,str(i),save_address)
print(f"success,{i}/{n}")
i += 1
if i%5==0:
time.sleep(1)
5.定义save_picture()方法
定义save_picture()方法,将图片以二进制形式写入文件保存:
def save_picture(self,r,name,save_address):
"""
保存图片
parameter:
r->requests.Response: 图片url请求返回结果
name->str: 图片保存名称
save_adress->str: 图片保存地址
"""
with open(save_address+'\'+name+'.jpg',"wb") as f:
f.write(r.content)
6.开始爬取与结果
最后,实例化一个PictureSpider类,开始爬取:
if __name__ == "__main__":
url = "https://mp.weixin.qq.com/s?__biz=MzI4MzM2MDgyMQ==&mid=2247493780&idx=1&sn=efde5d4ec9a5c04383b709ace1222518&chksm=eb8943cedcfecad84ffb4794d19cce4c7ae3344ffa0c361f646d10689717af33dab5da93332f#rd"
spider = PictureSpider(url)
text = spider.get_url_text()
pictures_address = spider.search_pictures(text)
spider.download_pictues(pictures_address,"Numpy_PPT")
待爬取结束后,可以看到目标推送中的所有图片都被保存到了“Numpy_PPT”文件夹中,并被按顺序命名:

7.爬虫部分完整代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : picture_spider.py
@Time : 2021/06/06 19:35:55
@Author : YuFanWenShu
@Contact : 1365240381@qq.com
'''
# here put the import lib
import requests
import yaml
import re
import os
import time
class PictureSpider(object):
def __init__(self,start_url):
with open("wechat.yaml", "r") as file:
file_data = file.read()
self.config = yaml.safe_load(file_data)
self.headers = {
"Cookie": self.config['cookie'],
"User-Agent": self.config['user_agent']
}
self.start_url = start_url
def get_url_text(self):
"""
返回网页html内容
parameter:
url->str:网址
return:
r.text->str:网页内容
"""
r = requests.get(self.start_url,headers=self.headers)
if r.status_code!=200:
print("网页加载失败")
else:
return r.text
def search_pictures(self,text):
"""
在网页中搜索图片url
parameter:
text->str: 网页内容
return:
picture_url->list: 图片URL列表
"""
pictures_url = []
re_image = re.compile('<img.*?src="(.*?)".*?>',re.S)
pictures = re_image.finditer(text)
for img in pictures:
if img.group(1):
pictures_url.append(img.group(1))
return pictures_url
def download_pictues(self,pictues_url,save_address):
"""
下载图片
parameter:
pictures_url->list: 储存图片url的列表
save_address->str: 图片保存地址
"""
i = 1
n = len(pictues_url)
for url in pictues_url:
r = requests.get(url,headers=self.headers)
if r.status_code!=200:
print(f"图片爬取失败,第{i}/{n}张")
i += 1
continue
else:
self.save_picture(r,str(i),save_address)
print(f"success,{i}/{n}")
i += 1
if i%5==0:
time.sleep(1)
def save_picture(self,r,name,save_address):
"""
保存图片
parameter:
r->requests.Response: 图片url请求返回结果
name->str: 图片保存名称
save_adress->str: 图片保存地址
"""
with open(save_address+'\'+name+'.jpg',"wb") as f:
f.write(r.content)
if __name__ == "__main__":
url = "https://mp.weixin.qq.com/s?__biz=MzI4MzM2MDgyMQ==&mid=2247493780&idx=1&sn=efde5d4ec9a5c04383b709ace1222518&chksm=eb8943cedcfecad84ffb4794d19cce4c7ae3344ffa0c361f646d10689717af33dab5da93332f#rd"
spider = PictureSpider(url)
text = spider.get_url_text()
pictures_address = spider.search_pictures(text)
spider.download_pictues(pictures_address,"Numpy_PPT")
(三)将图片批量导入PPT
1.代码
这部分使用到了“python-pptx”这个库,首先设置储存图片的文件夹路径,输入新建PPT的名字,然后自动将文件夹下的JPG图片按编号顺序写入PPT文件,最后保存:
import os
import pptx
from pptx.util import Inches
path = os.getcwd()
os.chdir(path+'\Numpy_PPT')
ppt_filename = input('输入目标ppt文件名(无需后缀):')
full_ppt_filename = '{}.{}'.format(ppt_filename,'pptx')
ppt_file = pptx.Presentation()
pic_files = [fn for fn in os.listdir() if fn.endswith('.jpg')]
# 按图片编号顺序导入
for fn in sorted(pic_files, key=lambda item:int(item[:item.rindex('.')])):
slide = ppt_file.slides.add_slide(ppt_file.slide_layouts[1])
# 为PPTX文件当前幻灯片中第一个文本框设置文字,本文代码中可忽略
slide.shapes.placeholders[0].text = fn[:fn.rindex('.')]
# 导入并为当前幻灯片添加图片,起始位置和尺寸可修改
slide.shapes.add_picture(fn, Inches(0), Inches(0), Inches(10), Inches(7.5))
ppt_file.save(full_ppt_filename)
2.结果
运行脚本后,文件夹中生成了一个PPT文件:
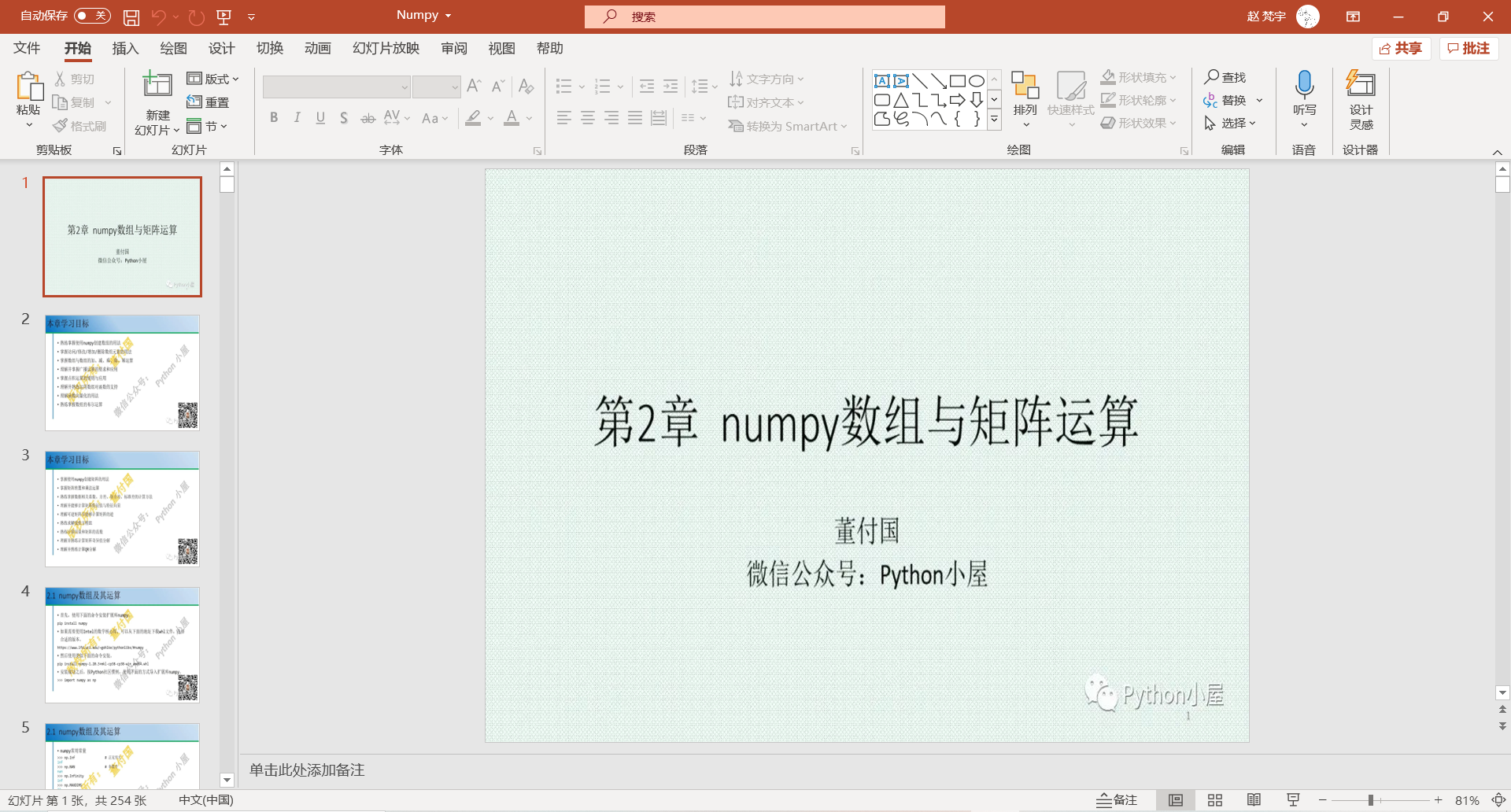
可以看到,所有254张图片都被按顺序导入了进来,效果十分理想。
三、结语
有了上次爬取“北邮家教部”公众号的经验,这次代码写起来十分顺畅,一共花了一个多小时就完成了所有模块,效果也十分理想。啥也不说了,Python,yyds!
另外再次感谢董付国老师~ 董老师写的好几本书我都看完了,并且在去年完成了当时“小屋刷题”系统中的所有练习题。可以说,董老师和北航的嵩天老师就是我的Python引路人。
最后
以上就是甜美烧鹅最近收集整理的关于用python爬取公众号推送图片并保存为PPT一、前言二、开始三、结语的全部内容,更多相关用python爬取公众号推送图片并保存为PPT一、前言二、开始三、结语内容请搜索靠谱客的其他文章。








发表评论 取消回复