声明:本文来自于微信公众号 新智元,作者:新智元,授权靠谱客转载发布。
【新智元导读】科幻中的贾维斯,已经离我们不远了。Claude3.5接管人类电脑掀起了人机交互全新范式,爆料称谷歌同类Project Jarvis预计年底亮相。AI操控电脑已成为微软、苹果等巨头,下一个发力的战场。
AI接管人类电脑,就是下一个未来!
几天前,Anthropic向所有人展示了,Claude3.5自主看屏幕操作光标完成复杂任务,足以惊掉下巴。
刚刚,Information独家爆料称,谷歌正开发同类新项目「Project Jarvis」,能将Chrome网页任务自动化。
谷歌「贾维斯」将由未来版Gemini2.0驱动,预计在12月亮相。

起这个名字,是为了向钢铁侠中的J.A.R.V.I.S致敬。
无独有偶,微软团队悄悄放出的OmniParser,也在笃定AI智能体操控屏幕的未来。

论文地址:https://arxiv.org/pdf/2408.00203
OmniParser主要是一个屏幕解析的工具,可以将截图转化为结构化数据,帮助AI精准理解用户意图。
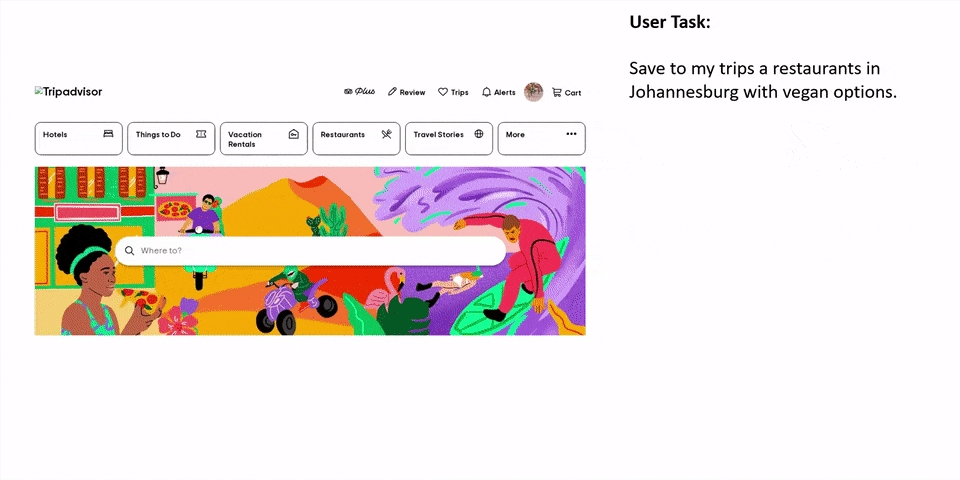
不仅如此,OpenAI内部已有了AI智能体雏形,可以操控计算机完成在线订餐、自动查询解决编程难题等任务。
包括苹果在内,预计在明年发布跨多个APP屏幕识别能力。最新迭代的Ferret-UI2,就是通用UI模型。
可见,「Computer use」已经成为科技大厂们,重点发力的下一个战场。

谷歌「贾维斯」年底出世,最强Gemini2加持
代号为Jarvis Project项目,本质上是一个大动作模型(LAM),也是谷歌一直以来在做的大模型方向。
它专门针对谷歌Chrome浏览器,进行了优化。
具体操作原理,与Claude3.5类似,通过截屏、解析屏幕内容,然后自动点击按钮,或输入文本,最终帮助人们完成基于网页的日常任务。
不论是收集研究信息、购物,或是预定航班等任务,谷歌「贾维斯」均可实现。
不过,它在执行不同操作时,中间会有几秒钟的思考时间。
因此,在终端设备中运行还不太现实,仍然需要云上操作。
5月的谷歌I/O大会上,谷歌CEO劈柴曾展示了,Gemini和Chrome如何协同工作的样貌。
如前所述,谷歌「贾维斯」将由Gemini2.0加持,也就意味着年底我们可以看到进步版Gemini模型。
尽管Sam Altman否认了Orion模型的发布,但外媒猜测,预计年底OpenAI也将放出新核弹
微软OmniParser也下场了
紧接着Claude「计算机使用」发布之后,微软就开源了AI框架OmniParser。
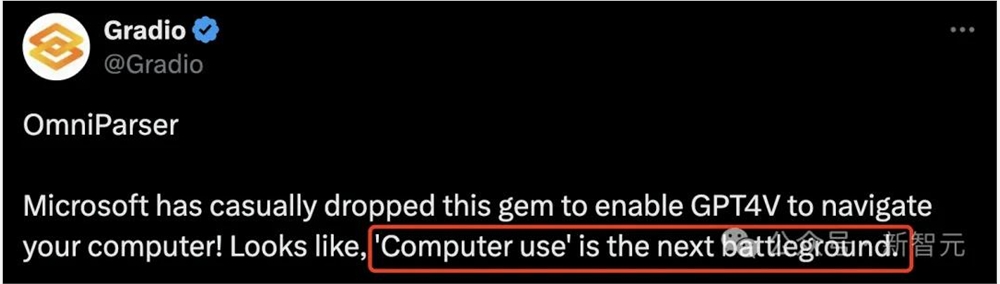
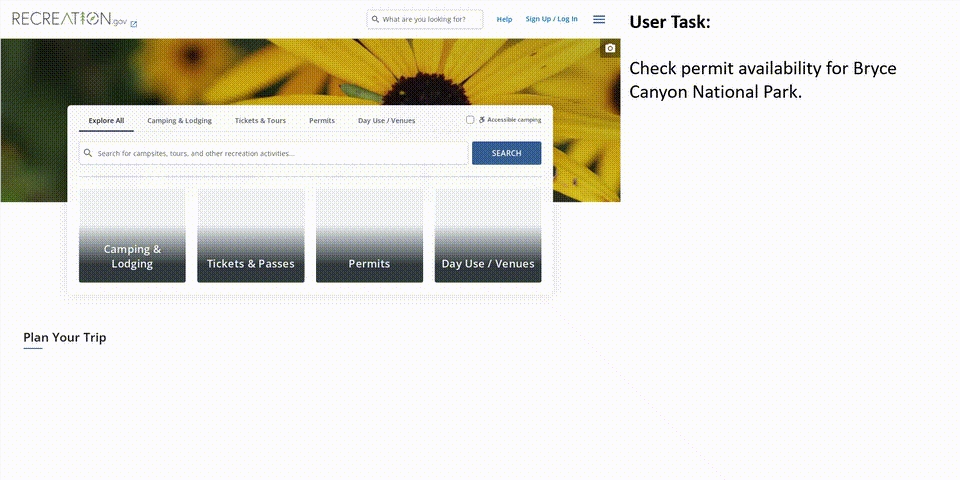
假设你想要去布赖斯峡谷国家公园,不知是否需要订票入园,这时OmniParser可以带你查询。
它会解析屏幕后,自动点击「permits」按钮,然后再截屏找到「布赖斯峡谷国家公园」,最后就可以完成用户任务。
可见,想要把类似GPT-4V的多模态大模型应用于操作系统上,模型还需要具备强大的屏幕解析能力,主要包括两方面:
1、准确地识别用户界面中的可交互图标;
2、理解屏幕截图中各种元素的语义,并准确将预期动作与屏幕上的相应区域关联起来。
基于上述思路,微软最新提出的OmniParser模型,可以将用户界面截图解析为结构化元素,显著增强了GPT-4V在对应界面区域预测行动的能力。
方法
一个复杂的操作任务通常可以分解成多个子行动步骤,在执行过程中,模型需要具备以下能力:
1、理解当前步骤的用户界面,即分析屏幕内容中大体上在展示什么、检测到的图标功能是什么等;
2、预测当前屏幕上的下一个动作,来帮助完成整个任务。
研究人员发现,将这两个目标分解开,比如在屏幕解析阶段只提取语义信息等,可以减轻GPT-4V的负担;模型也能够从解析后的屏幕中利用更多信息,动作预测准确率更高。
因此,OmniParser结合了微调后的可交互图标检测模型、微调后的图标描述模型以及光学字符识别(OCR)模块的输出,可以生成用户界面的结构化表示,类似于文档对象模型(DOM),以及一个叠加潜在可交互元素边界框的屏幕截图。
可交互区域检测(Interactable Region Detection)
从用户界面屏幕中识别出「可交互区域」非常关键,也是预测下一步行动来完成用户任务的基础。
研究人员并没有直接提示GPT-4V来预测屏幕中操作范围的xy坐标值,而是遵循先前的工作,使用标记集合方法在用户界面截图上叠加可交互图标的边界框,并要求GPT-4V生成要执行动作的边界框ID。
为了提高准确性,研究人员构造了一个用于可交互图标检测的微调数据集,包含6.7万个不重复的屏幕截图,其中所有图像都使用从DOM树派生的可交互图标的边界框进行标记。
为了构造数据集,研究人员首先从网络上公开可用的网址中提取了10万个均匀样本,并从每个URL的DOM树中收集网页的可交互区域的边界框。
除了可交互区域检测,还引有一个OCR模块来提取文本的边界框。
然后合并OCR检测模块和图标检测模块的边界框,同时移除重叠度很高的框(阈值为重叠超过90%)。
对于每个边界框,使用一个简单的算法在边框旁边标记一个ID,以最小化数字标签和其他边界框之间的重叠。
整合功能的局部语义(Incorporating Local Semantics of Functionality)
研究人员发现,在很多情况下,如果仅输入叠加了边界框和相关ID的用户界面截图可能会对GPT-4V造成误导,这种局限性可能源于GPT-4V无法「同时」执行「识别图标的语义信息」和「预测特定图标框上的下一个动作」的复合任务。
为了解决这个问题,研究人员将功能局部语义整合到提示中,即对于可交互区域检测模型检测到的图标,使用一个微调过的模型为图标生成功能描述;对于文本框,使用检测到的文本及其标签。

然而,目前还没有专门为用户界面图标描述而训练的公共模型,但这类模型非常适合目标场景,即能够为用户界面截图提供快速准确的局部语义。
研究人员使用GPT-4o构造了一个包含7000对「图标-描述」的数据集,并在数据集上微调了一个BLIP-v2模型,结果也证明了该模型在描述常见应用图标时更加可靠。

实验评估
SeeAssign任务
为了测试GPT-4V模型正确预测边界框描述所对应的标签ID的能力,研究人员手工制作了一个名为SeeAssign的数据集,其中包含了来自3个不同平台(移动设备、桌面电脑和网络浏览器)的112个任务样本,每个样本都包括一段简洁的任务描述和一个屏幕截图。
根据难度,任务被分为三类:简单(少于10个边界框)、中等(10-40个边界框)和困难(超过40个边界框)。
GPT-4V不带局部语义的提示:
Here is a UI screenshot image with bounding boxes and corresponding labeled ID overlayed on top of it, your task is {task}. Which icon box label you should operate on? Give a brief analysis, then put your answer in the format of n‘‘‘ Box with label ID: [xx]‘‘‘n
带局部语义的提示:
Here is a UI screenshot image with bounding boxes and corresponding labeled ID overlayed on top of it, and here is a list of icon/text box description: {parsed_local_semantics}. Your task is {task}. Which bounding box label you should operate on? Give a brief analysis, then put your answer in the format of n‘‘‘Box with label ID: [xx]‘‘‘n
从结果来看,GPT-4V经常错误地将数字ID分配给表格,特别是当屏幕上有很多边界框时;通过添加包括框内文本和检测到的图标的简短描述在内的局部语义,GPT-4V正确分配图标的能力从0.705提高到0.938

ScreenSpot评估
ScreenSpot数据集是一个基准测试数据集,包含了来自移动设备(iOS、Android)、桌面电脑(macOS、Windows)和网络平台的600多个界面截图,其中任务指令是人工创建的,以确保每个指令都对应用户界面屏幕上的一个可操作元素。
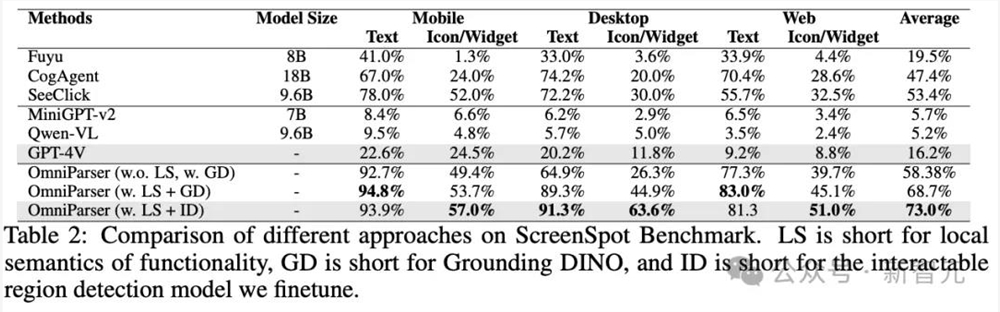
结果显示,在三个不同的平台上,OmniParser显著提高了GPT-4V的基线性能,甚至超过了专门在图形用户界面(GUI)数据集上微调过的模型,包括SeeClick、CogAgent和Fuyu,并且超出的幅度很大。
还可以注意到,加入局部语义(表中的OmniParser w. LS)可以进一步提高整体性能,即在文本格式中加入用户界面截图的局部语义(OCR文本和图标边界框的描述),可以帮助GPT-4V准确识别要操作的正确元素。
Mind2Web评估
测试集中有3种不同类型的任务:跨领域、跨网站和跨任务,可以测试OmniParser在网页导航场景中的辅助能力。
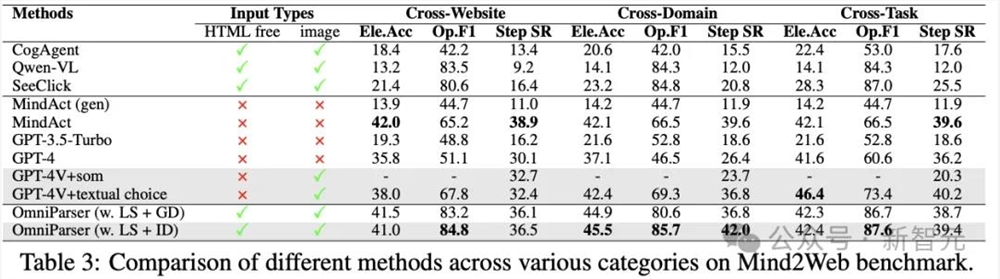
结果显示,即使没有使用网页的HTML信息,OmniParser也能大幅提高智能体的性能,甚至超过了一些使用HTML信息的模型,表明通过解析屏幕截图提供的语义信息非常有用,特别是在处理跨网站和跨领域任务时,模型的表现尤为出色。
AITW评估
研究人员还在移动设备导航基准测试AITW上对OmniParser进行了评估,测试包含3万条指令和71.5万条轨迹。

结果显示,用自己微调的模型替换了原有的IconNet模型,并加入了图标功能的局部语义信息后,OmniParser在大多数子类别中的表现都有了显著提升,整体得分也比之前最好的GPT-4V智能体提高了4.7%。
这表明了,模型能够很好地理解和处理移动设备上的用户界面,即使在没有额外训练数据的情况下也能表现出色。
参考资料:
https://microsoft.github.io/OmniParser/
https://x.com/Prashant_1722/status/1850265364158124192
(举报)








发表评论取消回复