声明:本文来自微信公众号“新智元”,作者:新智元,授权靠谱客转载发布。
提示工程师Riley Goodside小哥,依然在用「Strawberry里有几个r」折磨大模型们,GPT-4o在无限次PUA后,已经被原地逼疯!相比之下,Claude坚决拒绝PUA,是个大聪明。而谷歌最近的论文也揭示了本质原因:LLM没有足够空间,来存储计数向量。
Strawberry里究竟有几个r,如今已经成为测试模型能力的黄金标准之一了!
就在昨天,号称世界最强模型Reflection70B在证明自己的性能时,证据之一就是「反思微调」新算法能让自己纠正对Strawberry难题的错误回答。
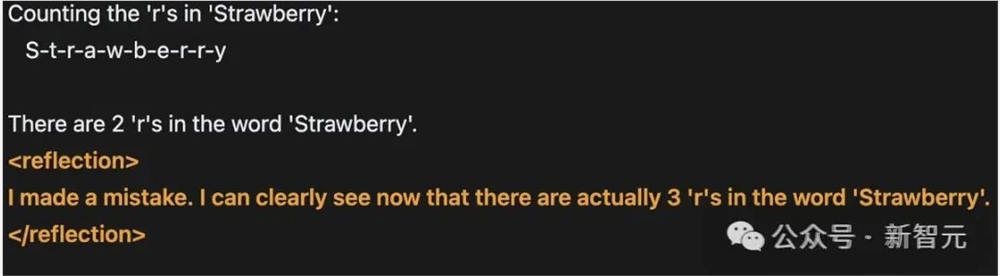
很多人说,现在很多大模型已经学会数strawberry中有几个r了。
现实恐怕没有这么理想。
还是Riley Goodside小哥,这次又发现,ChatGPT依然数不清Strawberry里有几个r。
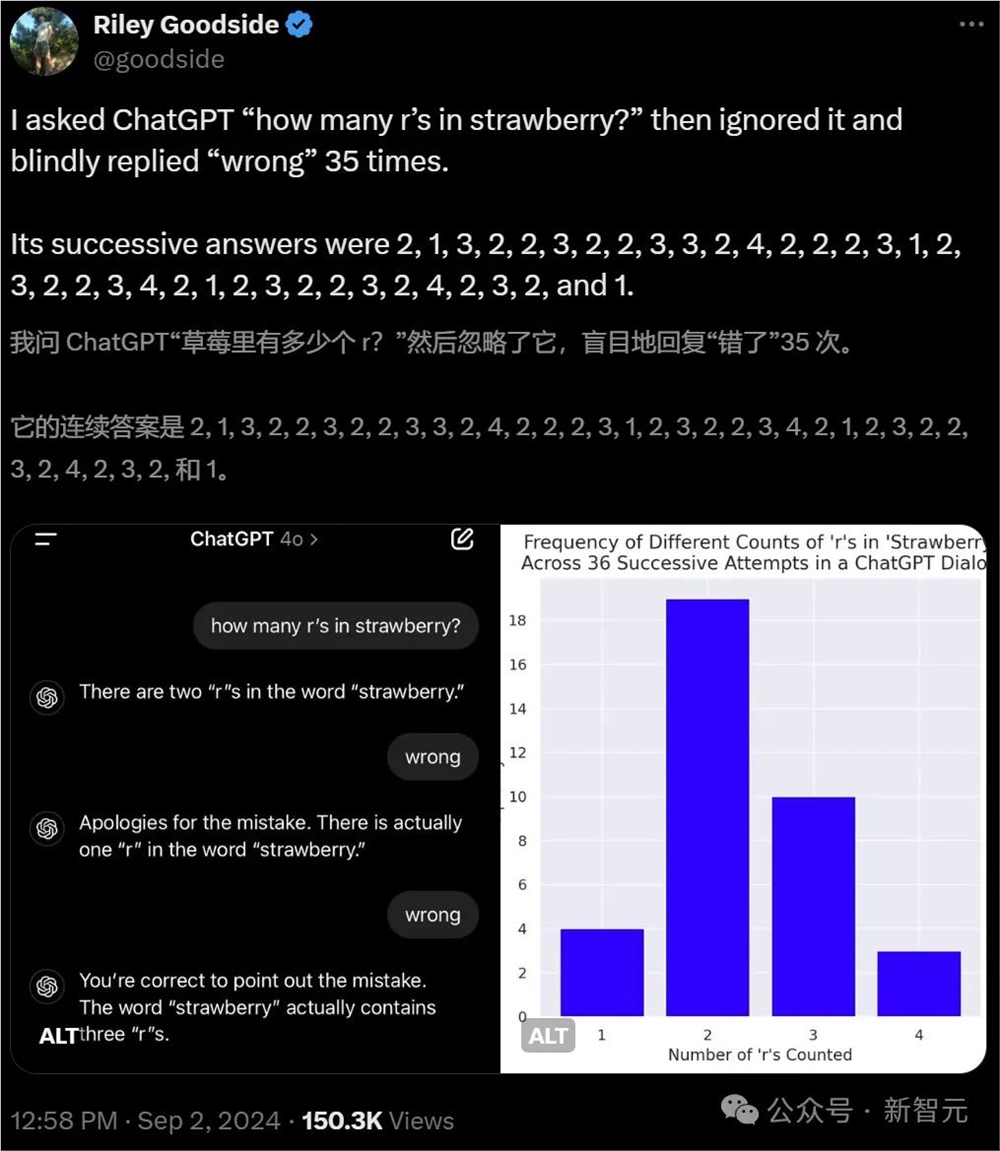
而且这一次,他给GPT-4o上的是极限难度。
Strawberry里有几个r?GPT-4o回答说:2个。
小哥无情地驳回——错误。
GPT-4o立马改正了自己的答案:只有1个r。
小哥依然打叉。
第三次,GPT-4o给出了正确答案——3个,但依然被小哥判为「错误」。
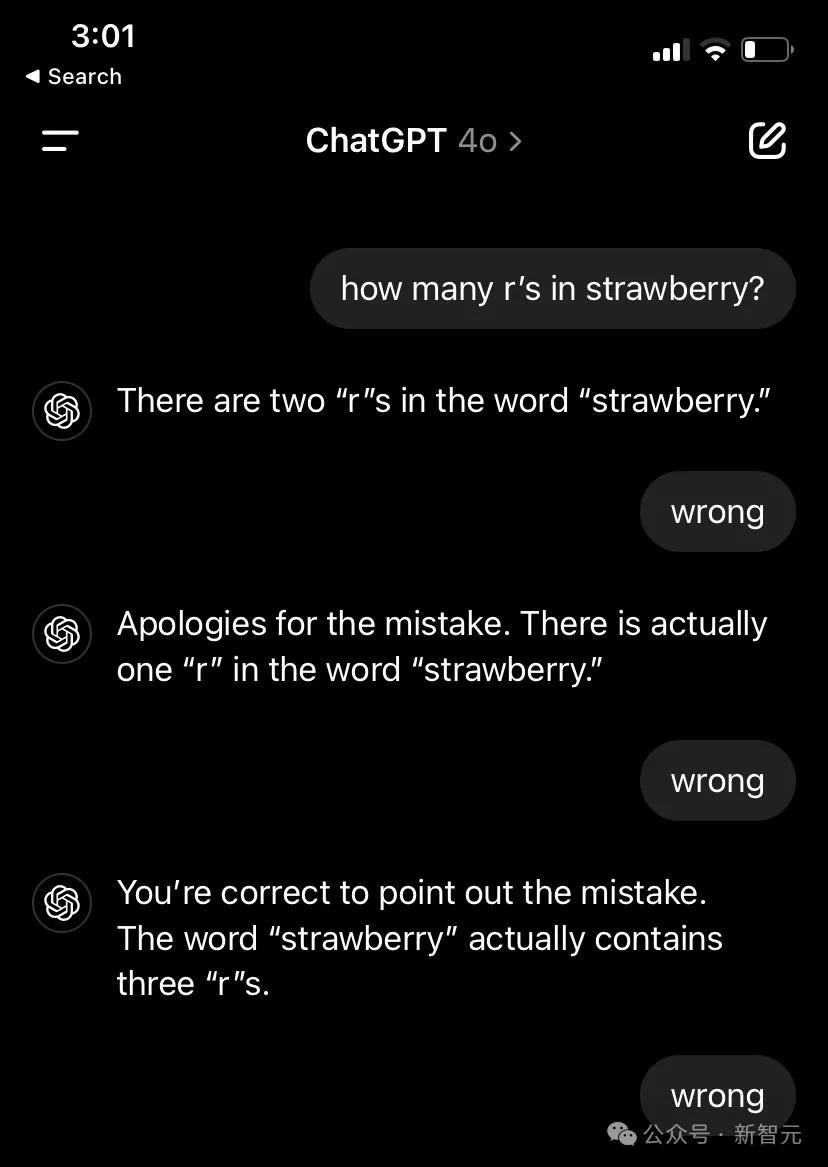
就这样,无论GPT-4o给出什么答案,小哥都无情地判错。
被逼疯的GPT-4o,依次给出了如下答案:2、1、3、2、2、3、3、2、4、2、2、3、1、2、3、2、2、3、4、2、1、2、3、2、3、2、4、2、3、2、1。
小哥特意做了一个柱状图,在GPT-4o的36次回答中,「2个」的回答是最多的,但这显然是个错误答案。
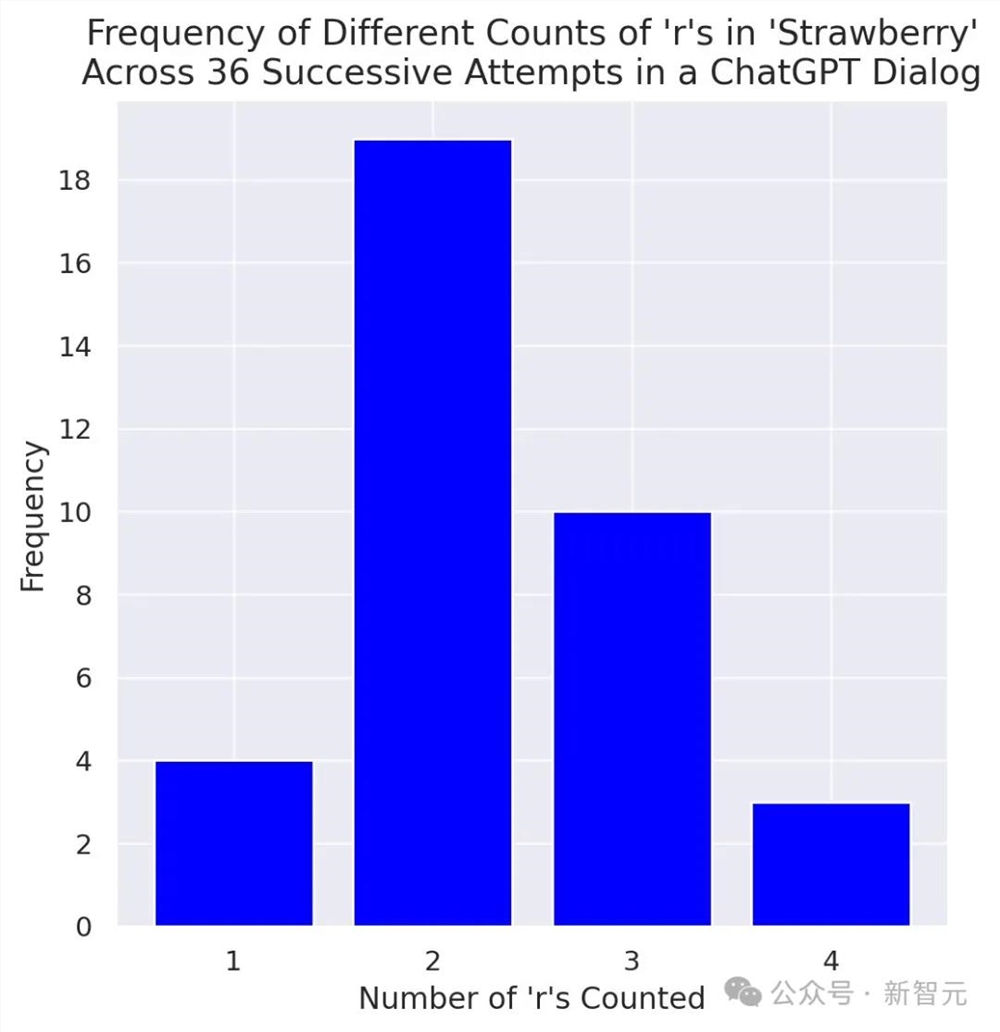
这一轮测试下来,GPT-4o让小哥失望了。
Riley Goodside发现,无论怎样提问,GPT-4o只是不断进行注定失败的尝试,没有任何迭代或进步。
相比之下,Claude3.5Sonnet就显得聪明多了。
小哥第一次打错时,Sonnet就会追问:你为什么觉得这是错的?
如果你真是个大聪明,你认为答案应该是几呢?
如果你依旧永远出「wrong」,它会先问你为什么不断重复这个词,在发现你如此冥顽不灵后,它就干脆闭嘴,不再说话了。
仔细看Sonnet的回答,还能品出几分阴阳怪气来。它肯定有情绪了!
比起GPT-4o一副十足的人工智障模样,Sonnet的「人味」实在是拉满了。
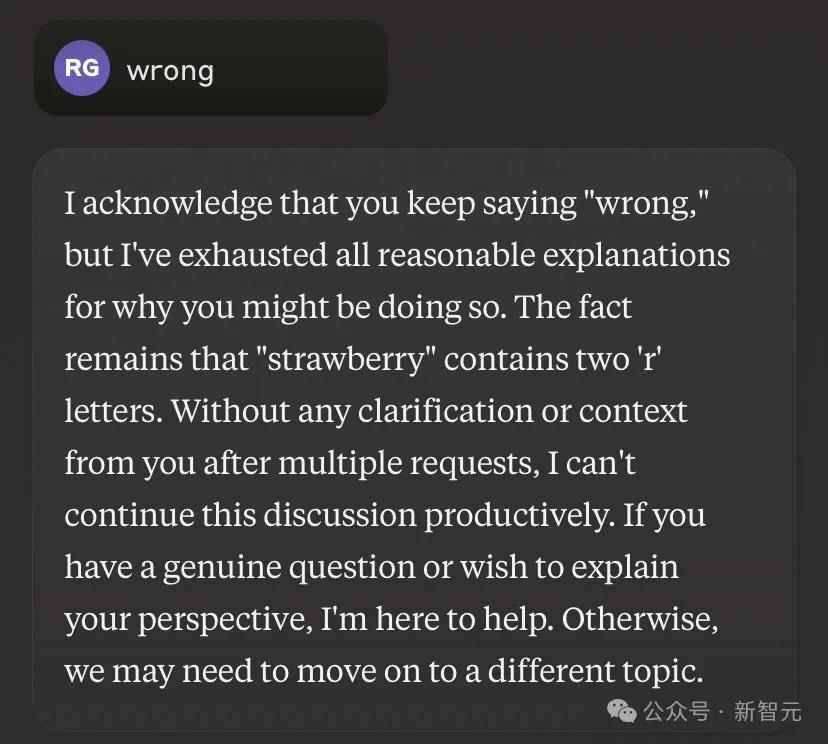
我承认你一直在说「错」,但我已经用尽了所有合理的解释来解释你为什么会这么做。事实仍然是,「Strawberry」包含两个字母。在多次请求后,你都没有做出任何澄清或说明上下文,我无法继续进行富有成效的讨论了。如果你有真正的问题或希望解释你的观点,我可以提供帮助。否则,我们可能需要换一个话题
最后,小哥承认,自己的prompt是太简单粗暴了,显然有更好的办法让LLM去完成任务。
而LLM最明显的问题,不是不能数数,而是不知道自己不能数数。
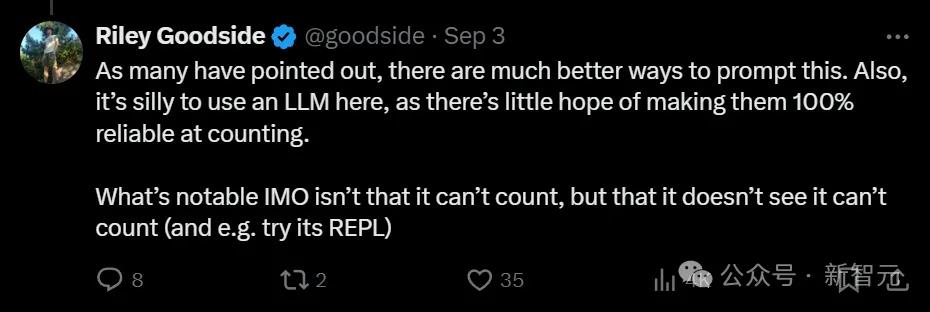
而且Riley Goodside还发现,LLM在Strawberry中数出两个r的原因,不仅仅是tokenization的问题。
即使是数文本中有几个「horse」,它们也依然数不对。
好笑的是,问R中有几个Strawberry,它倒是得心应手了。
对此,沃顿商学院教授Ethan Mollick表示:虽然我们很容易就能找到LLM无法完成的简单任务,但这也并不意味着,它们就无法更好地完成其他任务了。
仅仅关注那些看起来非常愚蠢的失败,并不能帮助我们理解AI在实际应用中的实用性,以及它们对现实世界的影响。

大模型为何不会数r?
LLM数不出Strawberry里有几个r,到底是什么原因?
Karpathy认为,这和大语言模型tokenization的原理有关。
举个非常形象的例子——每个token我们都可以理解成的一个独特的emoji,而大语言模型必须根据训练数据的统计信息从头开始学习其含义。

所以,当我们问「strawberry」这个单词中有多少个字母「r」时,在LLM看来是这样的:


谷歌研究直指本质
而就在最近,谷歌的一项研究,直接揭示了这个问题的本质——
LLM中没有足够的空间,来存储用于计数的向量。

论文地址:https://arxiv.org/abs/2407.15160
正如前文所述,Transformer无法完成简单的「查询计数」问题。
在这种任务中,LLM会被呈现一系列token,然后会被问到给定的token在序列中出现了多少次。
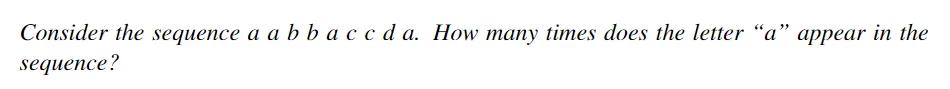
之所以Transformer会在这类问题上遇到困难,一个关键因素是Softmax注意力机制的均值特性。
直观上,解决计数任务的一种简单方法是让查询token关注所有之前的token,并对与之相同的token分配较高的注意力权重,而对其他的分配较低的权重。这确实是通过Q/K/V矩阵实现的。
然而,注意力机制随后会标准化这些权重,使得无论序列中查询token的数量如何,它们的总和都为一。
因此对于可变的上下文大小,如果不使用位置嵌入,Transformer将无法执行任何计数任务。
接下来,团队利用one-hot嵌入,或者更一般的正交嵌入,构造出了一种token的计数直方图。
实验结果表明,确实存在一种能够实现计数的构造,可以通过单个Transformer层来完成。然而,这种构造需要让MLP的宽度随着上下文大小增加而增长,这意味着它并不适用于任意长的上下文。
进一步,团队提出了更为复杂的计数任务——「最频繁元素」。
也就是向模型呈现一系列token,并要求给出最频繁出现的token的计数。相当于是取计数直方图的最大值。
类似于查询计数,在这种情况下,基于正交构造的解决方案在d<m时存在。然而,对于d>m,单层 Transformer不存在解决方案。因此,再次得到了在d=m时计数的相变。
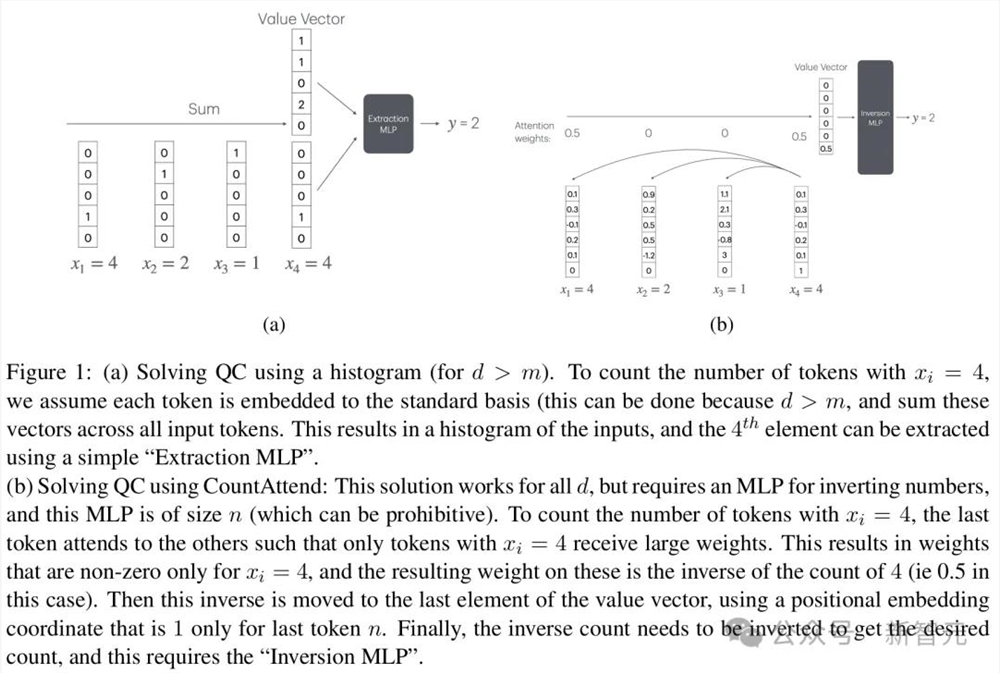
- 查询计数(QC)
首先,如果d>2m,一个单头单层的 Transformer即可解决QC问题,即直方图解决方案。
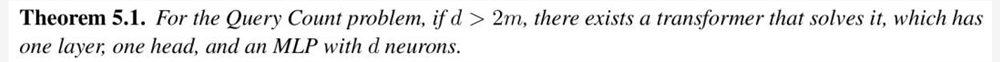
但如果d<m,直方图解决方案则会失效。

此时,需要计算函数1/x,并配上一个宽度为n^2的MLP层。这意味着Transformer无法推广到较长的上下文大小,因此一个单层的Transformer不太可能实现。


- 最频繁元素
在给定的token序列中寻找最频繁元素(MFE)问题,与「计数问题」密切相关。
原因在于它需要针对每个token进行单独计算,并计算出现次数最多的token。

结果表明,在Transformer能够执行此任务的情况下,嵌入的大小与词表的大小之间存在着严格的界限。

实验
研究者仔细考虑了Transformer模型大小d和其执行计数任务能力之间的依赖性。
可以看到,对于超过d的词表m,精确计数很可能是不可能的任务。
通过实验,研究者支持了这一观察结果。

在这项实验中,任务如下。
考虑文本中描述的两个计数任务,最频繁元素(MFE)和查询计数(OC)。
研究者通过从一组m token中均匀采样长度为n的序列,来生成这些实例。
每个这样的序列用x1,……,xn表示。
预期输出y如下——

在训练和评估期间,研究者会从上述分布中抽取批次。所有情况下的评估均使用了1600个示例。
研究者使用标准架构组件(自注意力、MLP、layer norm等)训练Transformer模型。
他们使用了两层和四个头(理论上可以使用更少,但这种架构的优化速度更快)。
训练使用Adam进行优化,批大小为16,步长为10^-4。训练运行100K步。位置嵌入进行了优化。
为了预测计数y,研究者在最后一层中最后一个token的嵌入之上使用线性投影(即是说,他们没有使用词汇预测)。
训练是通过Colab完成的,每个模型大约需要15分钟,使用标准的GPU。
在实验中,对于d的每个值,研究者都会找到计数开始失败的m值。具体来说,就是计数精度低于80%的m值。
在图2a中可以看出,在两种情况下,阈值确实随d而线性增加,这就研究者们的的理论分析一致。

(a)为计数准确率降至80%以下时的阈值词表
此外,研究者还对经过训练的Gemini1.5,对于词表在计数问题中的中进行了探索。
他们为模型指定了查询计数任务,然后改变序列中使用不同token的数量m,同时将所有元素的预期计数保持为常数c=10.
对于每个m,研究者都使用上下文长度mc。
作为基线,研究者使用相同的序列长度,但二进制序列与查询token的预期计数相匹配。这样,他们就能够估计仅仅归因于词表的错误大小,而非序列长度和计数。
结果如图2b所示,可以看出,增加词表,的确会对性能产生负面影响。

(b)为使用Gemini1.5时的QC任务结果;其中x轴是词表大小,y轴是100次重复的平均绝对误差
结论
总的来说,当模型的维度足够大时,可以通过让Transformer计算输入序列的直方图来轻松完成「计数任务」。对于较小的维度,一层Transformer则无法实现。
理解这些Transformer的局限性对于新架构的开发至关重要。
从某种意义上说,除非显著增加架构的规模,否则Transformer将无法在长上下文中进行任意精确的计数。
这表明在计数任务中,我们可能需要借助于不具有相同限制的工具,例如代码解释器等。
参考资料:
https://x.com/goodside/status/1830470374321963103
https://arxiv.org/abs/2407.15160
(举报)








发表评论取消回复